系列文章
结构方程模型建模思路及Amos操作–基础准备
结构方程模型建模思路及Amos操作–分析前的原始数据处理
结构方程模型建模思路及Amos操作–组成信度和平均萃取量的计算
结构方程模型建模思路及Amos操作–模型匹适度检验
结构方程模型建模思路及Amos操作–模型修正
所谓模型修正的意义就是,,刚才匹适度指标和参数指标都不通过,然后我们通过修正模型的方法,使得各项指标都满足要求。
修正方法:
一、对路径进行修正
1.将没有达到显著性水平的影响路径删除
如果外因潜变量对内因潜变量的路径系数不显著(γ系数值,p>0.05),或内因潜在变量间关系的路径系数不显著(β系数值,p>0.05),则这些不显著的直接效果路径可以删除。
2.删除不合理路径
如果增加的路径系数的正负号与原先理论文献或经验法则相反,则此条路径系数应该删除。
3.限制路径
新增加一些相关或者因果关系的限制。
但是增列的参数关系不能违反SEM的假定
1.外因潜变量与内因潜变量的指标变量间没有直接关系。
2.内因潜变量与外因潜变量的指标变量间没有直接关系。
3.外因潜变量的指标变量与内因潜变量的指标变量间没有直接关系。
4.指标变量的残差项与潜在变量间无关(不能建立共变关系),指标变量的残差项可以有共变关系,但是指标变量间的残差项间不能建立路径因果关系。
用图来说就是下面红线都是错误示范。
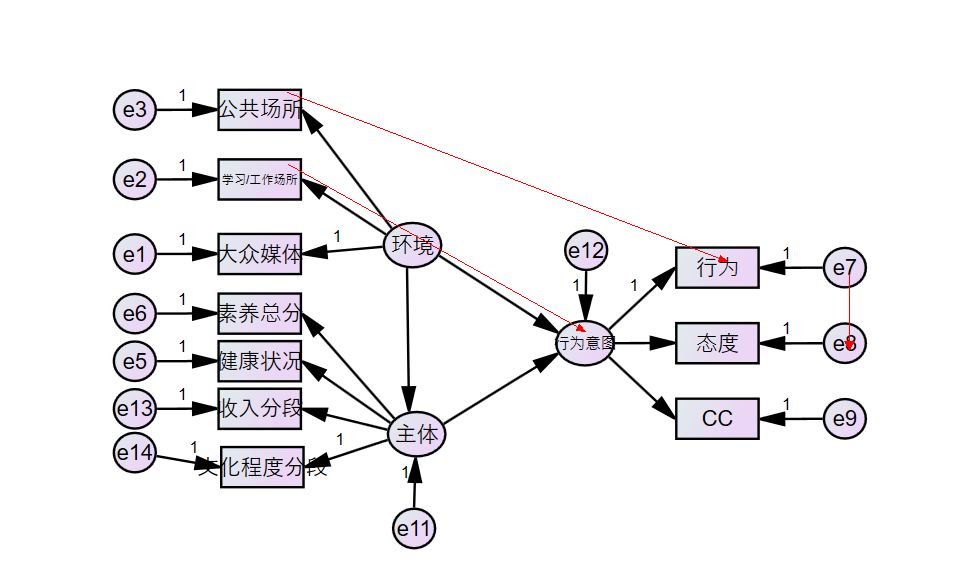

4.释放原先限制的路径
就是把之前设定的不合理和相关、因果等关系释放。
二、通过修正指标进行修正
较大的修正指标搭配较大的期望参数改变值表示该参数应被释放,因为释放的结果可以使整体契合度的卡方值降低很多,且获得较大的参数改变。
在CFA模型匹适中,根据修正指标来修正原先的假设模型,虽然可以有效的改善模型的匹适度,降低卡方值,使得假设模型契合实际数据,但如此不断修正假设模型,更改参数设定及变量间的关系,修正以后的新模型已原理CFA本质。
以上这段话的意思是,能少用修正指标修正模型就少用,就我像写的第一篇AMOS操作里面所说明的那样,设计问卷的时候多几条条目,通过删除不合理的路径来提升模型,最好少用修正指标。
这里要输出修正指数,记得分析属性那里一定要记得选修正指数选项,见下图红色方框。
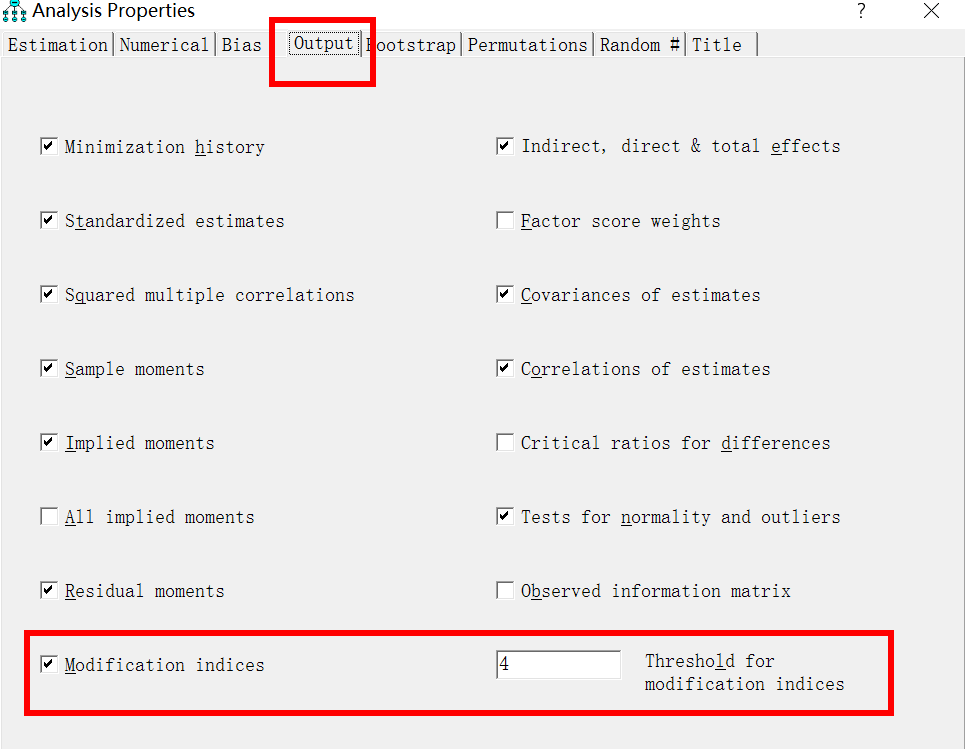

这里红色框起来的还有一个“threshold for modification indices”,就是显示修正指标的门槛值,AMOS里面内定为4,就是说修正指标只有大于4才会显示出来,之前看老师操作的时候他偶尔会设为20,但是我觉得有些时候修正,20太大了,所以就设为4。
点开output里面的修正指标(modification indices),见下图,一共包含三个部分,协方差、方差和回归系数。如果模型选了估计变量的均值和截距的话,修正指标还会有均值和截距项。什么时候选均值和截距,请参考第一篇文章结构方程模型建模思路及Amos操作–基础准备。


右侧输出有两个指标,分别是M.I 和Par Change。
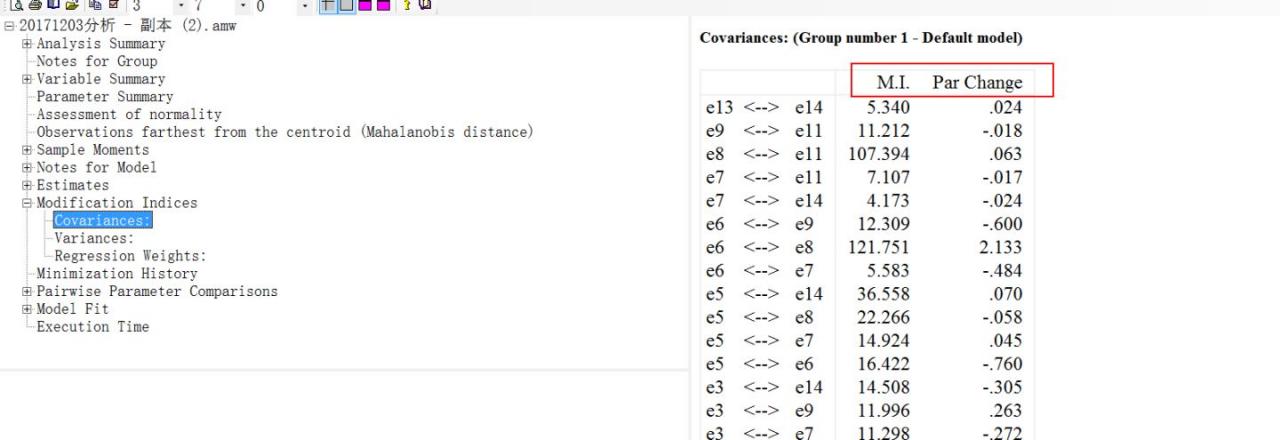

M.I:修正指标卡方值(modification indices),进行这个修正能够降低的卡方值最少是多少。
(不用知道太清楚,会用就行)从统计学意义上来看,修正指标即自由度为1,前后两个估计模型卡方值之间的差异值,因此,最大的修正指标值表示当某个固定参数被改设为自由参数而重新估计时,该参数可以降低整个模型卡方值的最大数值。
Par Change:期望参数改变量(expected parameter change, EPC值)。
(不用知道太清楚,会用就行)EPC值为当固定参数被放宽修正而重新估计时,所期望获得的改参数估计值的改变量,如果MI值较大,且对应的EPC值改变量也比较大,表示修正改参数带来的期望参数改变量的数值也较大,可以明显降低卡方值,此种修正才有显著的实质意义。
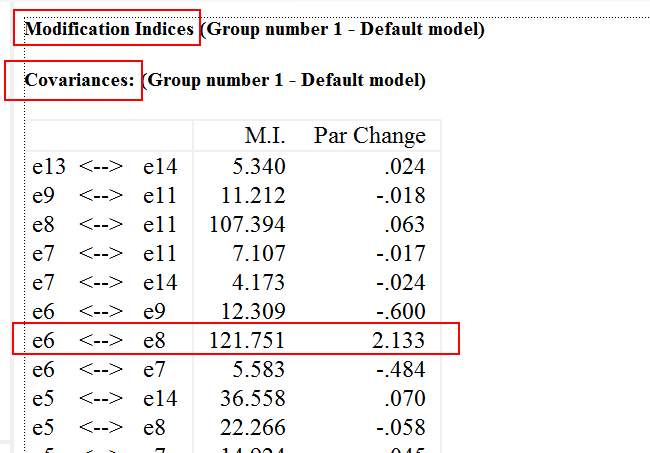

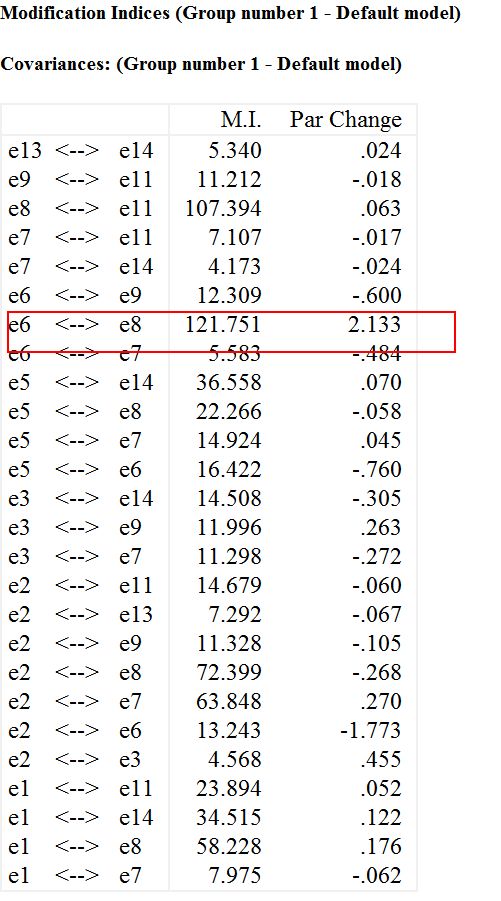
解释一下,就是,看上图,红色框起来的,代表是协方差的修正指标,里面最大的是e6和e8的修正指标,MI值为121.751,代表如果将e6和e8由固定参数(fixed parameter)改为自由参数(free parameter),可以降低至少卡方值121.751。Par change为2.133,表示将e6和e8由固定参数改为自由参数的话,相比较原先界定的模型,Par change会增加2.133.
这里,由固定参数改为自由参数,需要在操作界面,假设e6和e8有共变关系。见下图。
第一步,点回操作界面

下面这个双向箭头的就是代表共变关系。点击这个图标,然后连接e6和e8就可以了。

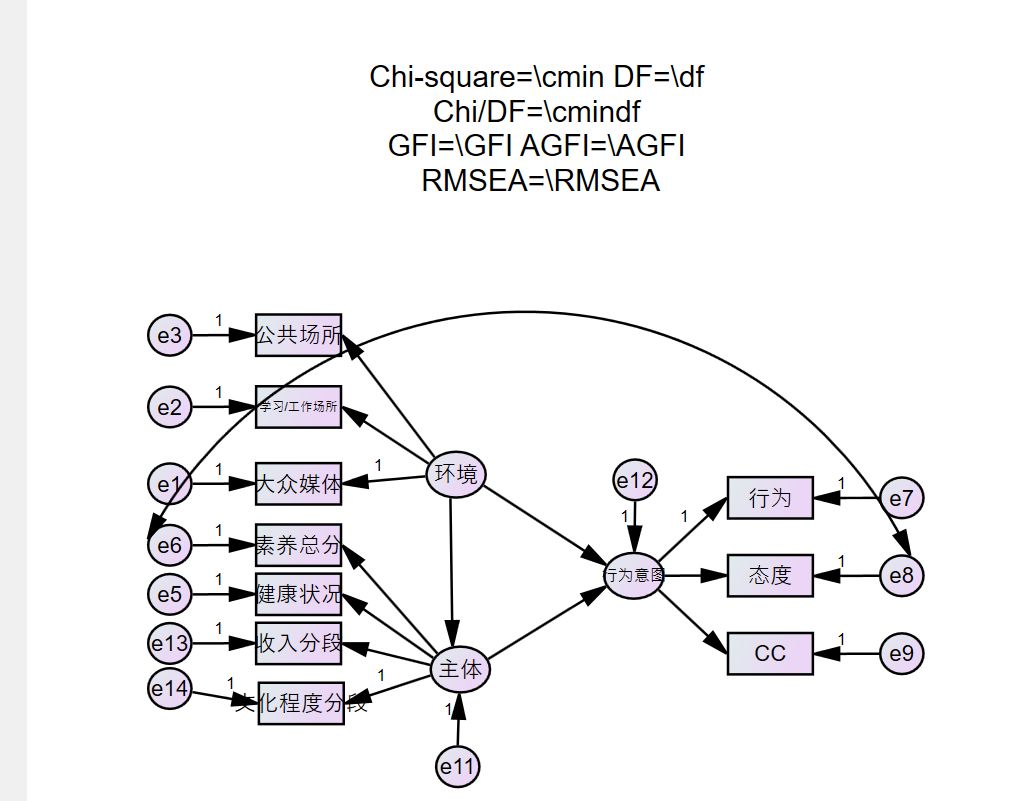
模型就变成这样。再运行就可以了。

三、实例操作
刚才是示范哈,虽然指标很少,但是,再三提示,除非没有办法,最好不要一来就用修正指标进行修正,先看看路径系数哪些能删,还能增加哪些限制。
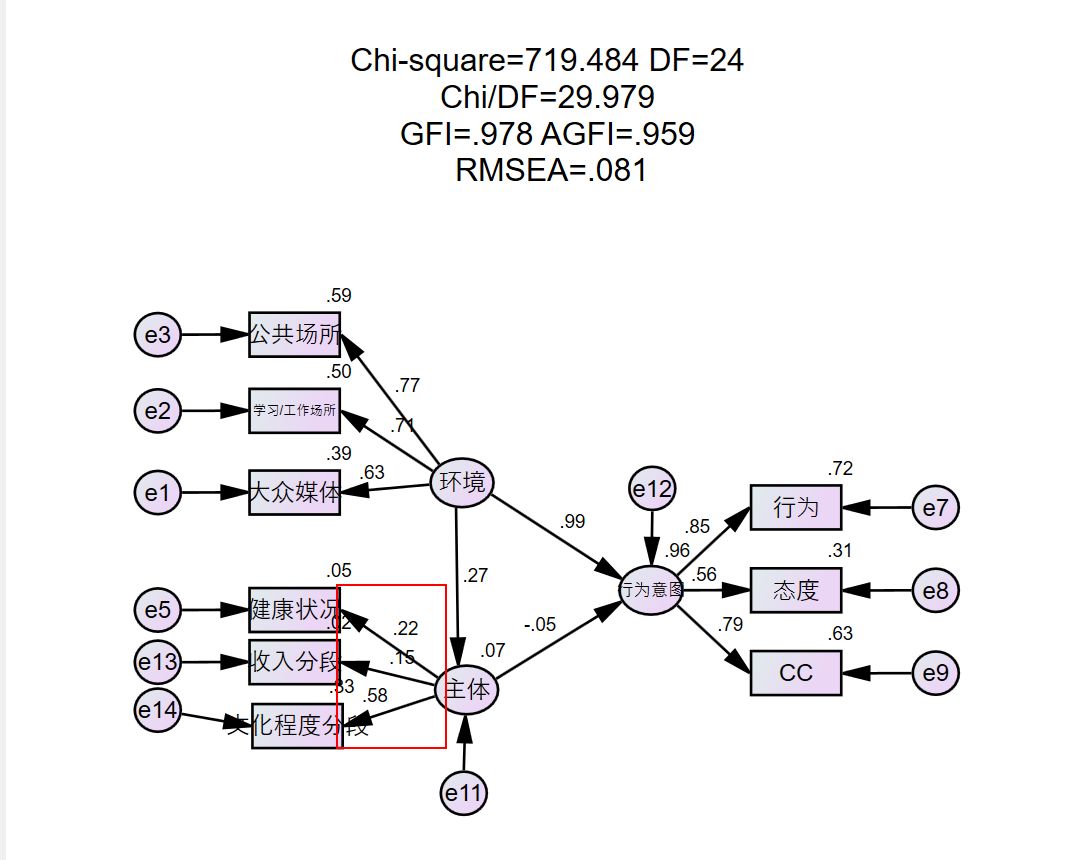
首先我们看loading值,见下图,有两部分出了问题,一块是环境对行为意图的loading大于1,提示环境部分的三个观察变量存在多重共线性,可以把loading 值最低的大众媒体删除(待会看看MI值确定是不是)。第二部分是“主体”的各个观察变量之间的loading值,素养总分的loading大于0.7,但是健康状况和收入分段的loading却很低,这种情况就是这个部分一个不止一个潜变量,应该有两个,but。。。我的数据支撑不了二阶潜变量,所以还是删除一些维度,变成一阶潜变量得了。但是不能按照loading值最低的删除,看MI值。
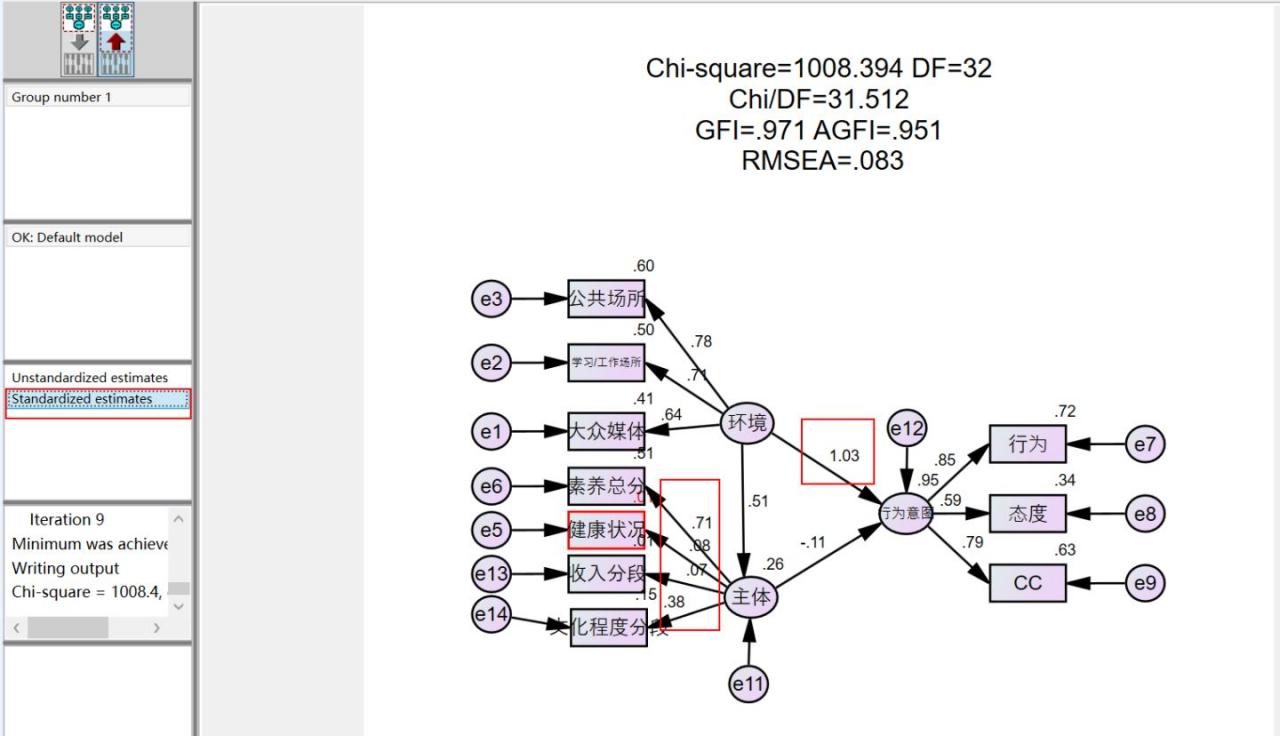

这里的话e6和e8的MI值最大,见上图和下图,e6是素养总分,e8是态度,根据刚才的讨论,我们先把e6的维度,素养总分删了。然后跑一跑程序。

果然。。数据真心太差了。主体那一块的loading还是不合格,如果是问卷的话,说明问卷的设计信度不够。

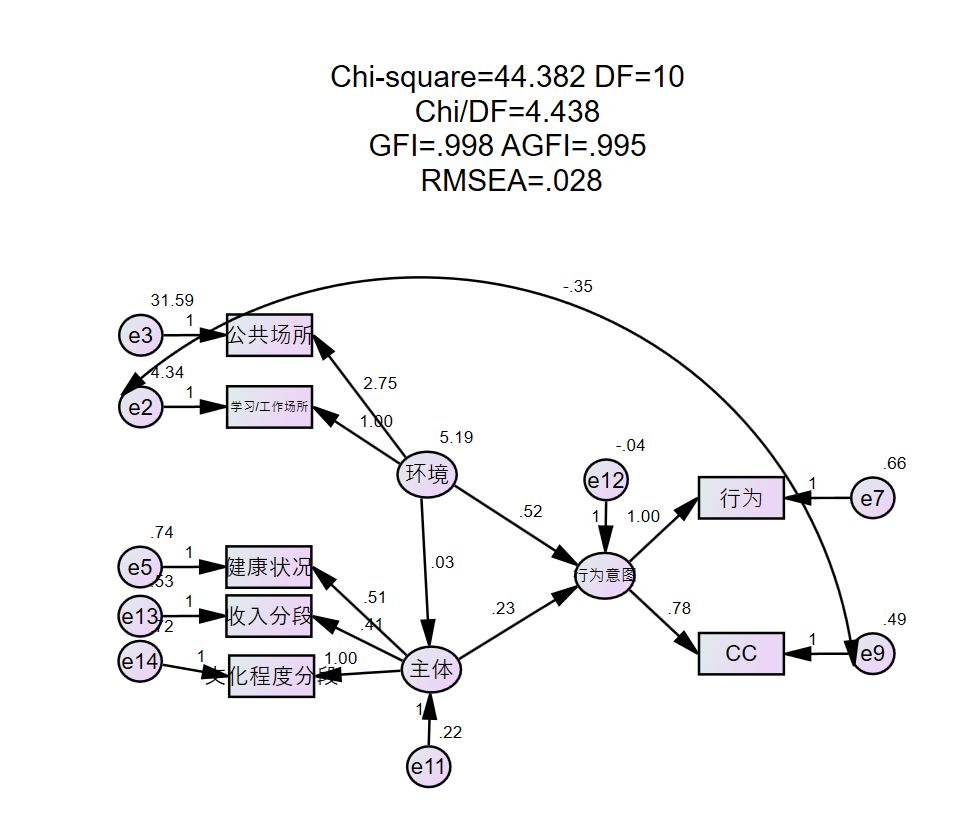
反正秉持着删loading值较低和修正MI值较大的原则。多试几次,建立不同的模型。总有一款适合。
最后的模型修正成这样,真心无能为力了,各项指标达标就OK了。

本文来自zhihu,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhuanlan.zhihu.com/p/31743768
注意:本文归作者所有,未经作者允许,不得转载

