按照上一篇的方法建好模,开始运行之后,检查各项结果的情况。一般的思路是看各项指标的合理性、匹适度,如果不过关(基本上都是不过关的),再修正模型,然后直到过关啦。
一、各项指标的合理性
(一)参数估计值
刚才看了匹适度的指标,现在看一下参数值是否合理,类似于模型诊断这样子的,看参数和模型哪里出了问题,然后针对性的修正。
(1)负的误差方差
方差是标准差的平方,所以是不可能为负值的,如果出现负的误差方差,则可能是模型或数据出了什么问题。在Amos模型的估计值中,若出现方差为负或相关系数的绝对值大于1,会得到不可理解(inadmissible)的情形,即使模型可以顺利识别或估计,但得到的参数无法作合理的解释。方差为负也成为heywood案例(heywood case)。
误差方差可以从两个地方看
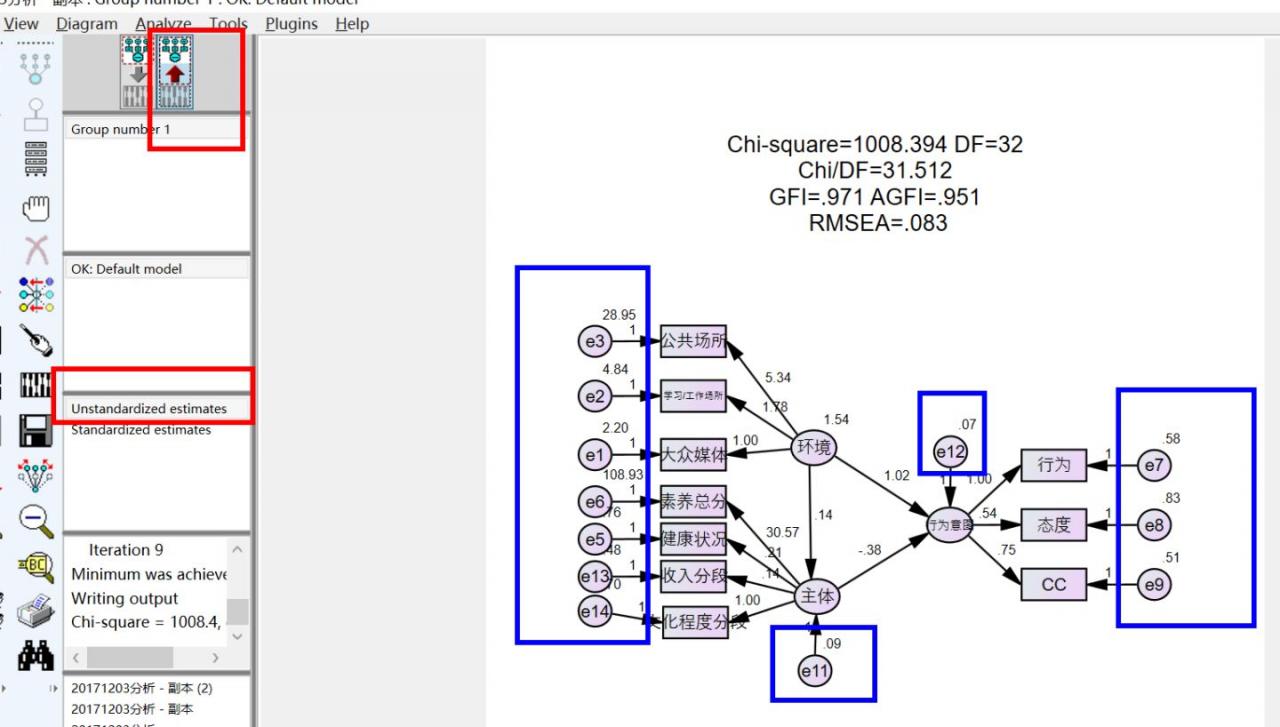
第一种方法,结果跑出来以后,点击结果显示,非标准化的估计结果(unstandardized estimates),蓝色框起来的这些就是残差方差,比如说最下面e11的方差就是0.09.

第二种方法,点击查看输出结果,框起来的这个图标

点开以后,看左边的对话框点击估计(Estimates),把“+”点击一下,扩展开来,可以看见蓝色框起来的“Variances”这里,就是残差方差啦。

可以看见e11的方差是0.091,和上面的那个是一样的,看上面的横标题,estimate就是估计值,S.E是估计参数的标准误(standard error),C.R是检验统计量(临界比,critical ratio),P是P值,***均是代表小于0.001,label是标签。
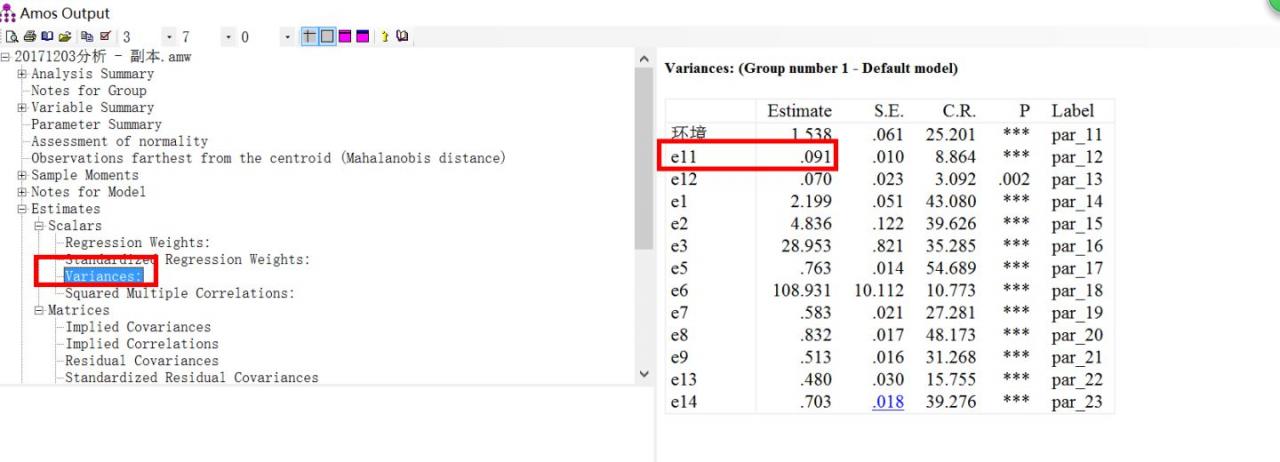

结论:所以,这个模型里面误差方差均大于0,是没有异常值的。
(2)协方差间标准化估计值的相关系数大于1
相关系数的取值范围就是0~1,所以大于1肯定是异常情况。
这个在哪里我没有找到。。。
(3)协方差矩阵或相关矩阵不是正定矩阵
正定矩阵是一种实对称矩阵。正定二次型f(x1,x2,…,xn)=X′AX的矩阵A(或A的转置)称为正定矩阵。

因为AMOS只要有相关矩阵或者协方差矩阵,就可以不用原数据跑程序,所以图就不上传了。
双箭头连结的两个外因变量在非标准化估计值模型图中呈现的是二者的协方差,在标准化估计值模型图中呈现的是二者的积差相关系数。
(4)标准化回归系数超过或非常接近1(临界值0.95,Heir et. Al. 1998))
也有两种查看的渠道
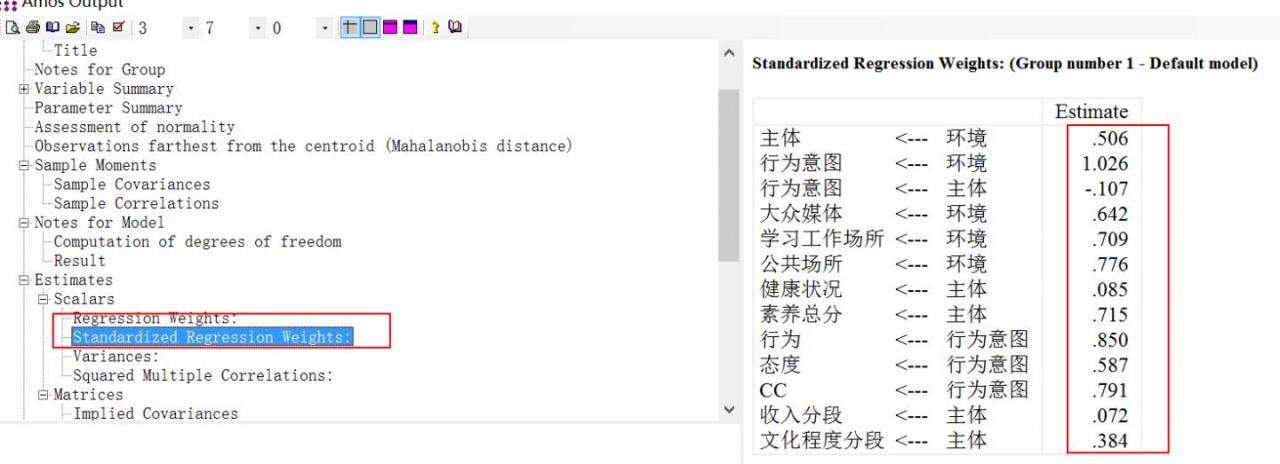
方法一,可以直接查看,点击结果查看的红色按钮,选择标准化估计(standardized estimates),结果就是标准化的了。见下图蓝色框起来的就是标准化的回归系数,均是小于0.95的,红色框起来的“行为意图”,右上角有一个0.95,注意那不是标准化回归系数,而是“行为意图”的R平方估计(squared multiple correlation)。


方法二:点击估计—标准化的回归权重,可以看见环境对“行为意图”那一块的标准化回归系数大于1,有异常。

(5)标准误出现极端值,非常大或接近0.
出现参数估计值异常的原因
- 样本量太小
- 未能符合每个潜在变量至少三个变量的原则
(二)CFA分析时因素负荷量常出现的问题
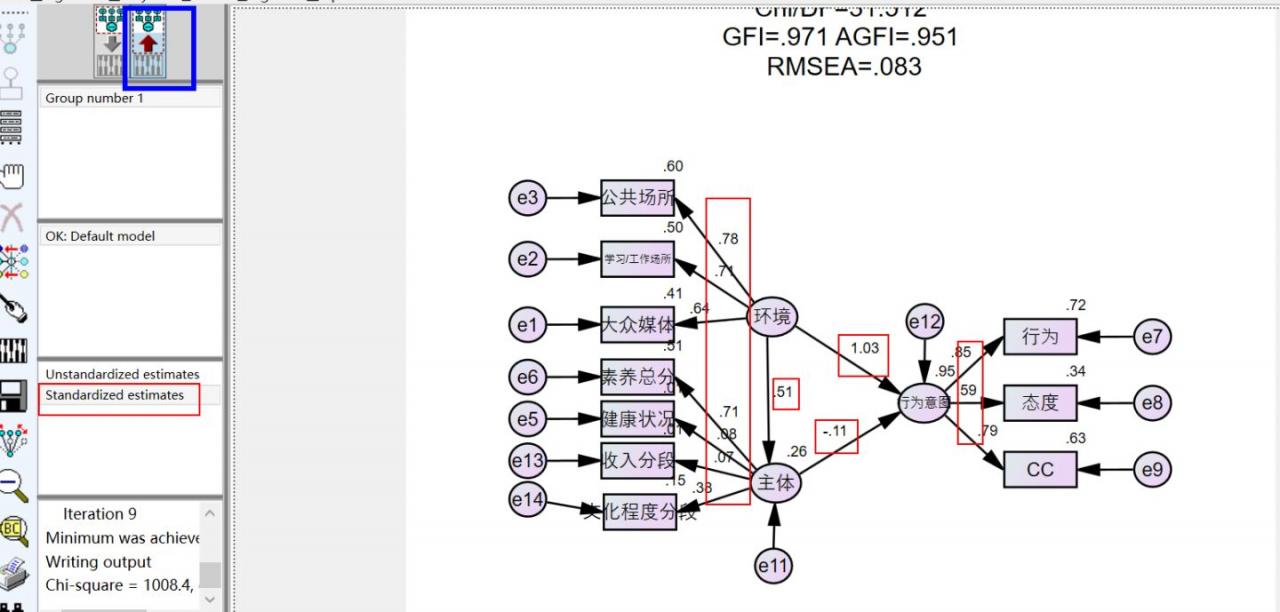
因素负荷量也称为标准化的回归系数(β值),即路径分析中的路径系数,见下图红色方框。

(1)因素负荷量不高,如小于0.45
原因:问卷设计不良,缺乏信度。
观察变量应该放到其他的潜在变量的地方。(Kline, 2011)
(2)某些因素负荷量高于1
原因:观察变量之间存在多重共线性
(3)因素负荷量部分大于0.7,但是部分小于0.5
原因:潜在变量应该不是一个,而是存在两个潜在变量。
(4)因素负荷量均大于0.7,但模型匹适度低
原因:残差不独立,即样本不独立。
(5)因素负荷量为负值
原因:表反向题忘记转向
(6)CFA根本跑不出来
原因:观察变量之间相关性太低或为1。
二、模型匹适度情况
需要注意的是,不像回归那样,需要首先看的是回归模型的检验(P值),再看各个回归系数是否有统计学意义,在SEM里面,匹适度的P值不作为主要的判断标准
P值在结果输出的模型注解部分。见下图。


P值小于0.05,拒绝原假设,表示观察数据的S矩阵与假设模型隐含的 矩阵不契合,即观察数据(data)与假设模型(model)间不匹配。但是样本越大,越容易拒绝H0(P<0.05),更容易犯二类错误。所以在实际应用上很少用P值作为匹适度的判断指标,Tanaka (1993)和Maruyama (1998)的研究都显示,当样本量大于200时,几乎所有的研究都是具有显著性的(P<0.05),因此判断匹适度的时候应该辅助以其他指标。
常用模型匹适度判断指标
模型匹适度可以分为三大评估原则
- 估计出的匹适度>0.5,表示越接近1越好,0.9以上为理想值,0.8以上为可接受
- 估计出的匹适度<0.5,表示越接近0越好,0.05以下为理想值,0.08以下为可接受
- 估计出的匹适度不在0~1之间,表示值越低越好。
一般来说,一些匹适度的指标在输出结果就可以查到,一些需要自己计算。
匹适度指标分类
1.绝对匹适指标
可解释为样本协方差矩阵被模型协方差矩阵解释的比例,类似R方。
常见指标有
卡方值:越小越好,大样本的情况下卡方值也作为一个参考指标
P值:不常用
卡方值/P值:也成为normed chi-square(NC),作为卡方值的修正和补充,严谨情况下NC值在1~3之间为理想值,宽松情况下小于5即可。
GFI值:大于0.9以上为理想。
AGFI(调整后的AGFI)值:大于0.9以上为理想。
CN值:不常用,大于200,数值越大匹适度越好。
2.增值匹适指标
研究模型的匹适度与统计基本模型比较改善的程度,基本模型指的是独立模型。
RMR值(残差均方和平方根):不常用,小于0.05
SRMR值(标准化残差均方和平方根):常用,小于0.05,这个值我看吴明隆老师的书把它归在了绝对匹适度里面。
RMSEA(渐进……) :小于0.08为可接受,小于0.05为良好,这个值同上面的SRMR一样,我看吴明隆老师的书把它归在了绝对匹适度里面。
HOELTER(CN):大于200,越大越好
3.精简匹适指标
决定研究模型是否太过复杂,同一样本资料但相似的模型以精简指标越大的越好。原理是惩罚参数多的模型。
PGFI (简约匹适度指标): >0.50
PNFI (简约后规范指标) :>0.50
PCFI (简约后匹适指标): >0.50
4.竞争型匹适指标
一般在有两个以上模型的时候才会用到竞争型匹适指标,类似在回归分析中,当有数据可以拟合多个模型时,利用拟合优度来筛选模型。这里也是,利用竞争型匹适指标来挑选匹适效果最好的模型。
NCP: (非集中性参数) :越小越好
SNCP(尺度化参数) :越小越好
ECVI (期望交叉效度指标) :常用,越小越好
AIC (资讯指标) :常用,越小越好
CAIC (一致性指标) :越小越好
BCC (Browne-Cudeck 标准) :越小越好
BIC(贝氏资讯标准):常用,越小越好
5.比较适度指标
这个指标是我在吴明隆老师的书里面看见的,判断依据都是宽松要求为大于0.9,大于等于0.95为良好。
分别有:NFI值、RFI值、TLI值(NNFI值)、CFI值、MFI值(Mc)
匹适度指标的查找
这里我贴一张从一些学者的研究里面报告的匹适度检验,他做了卡方/自由度(NC值),RMSEA, NFI, NNFI, CFI, IFI, SRMR这几个指标。我们也就这几个指标吧。
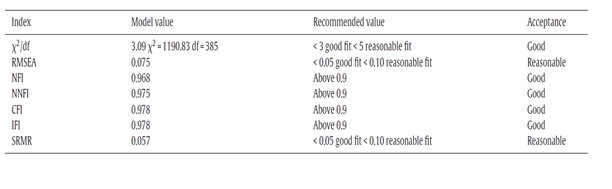

运行模型以后,点击查看输出,看模型匹适情况的输出结果,model fit就是匹适结果的输出(为什么知乎上面上传照片像素这么渣啊,我传天依的照片是因为没有文字吗?感觉就没有这么差劲)
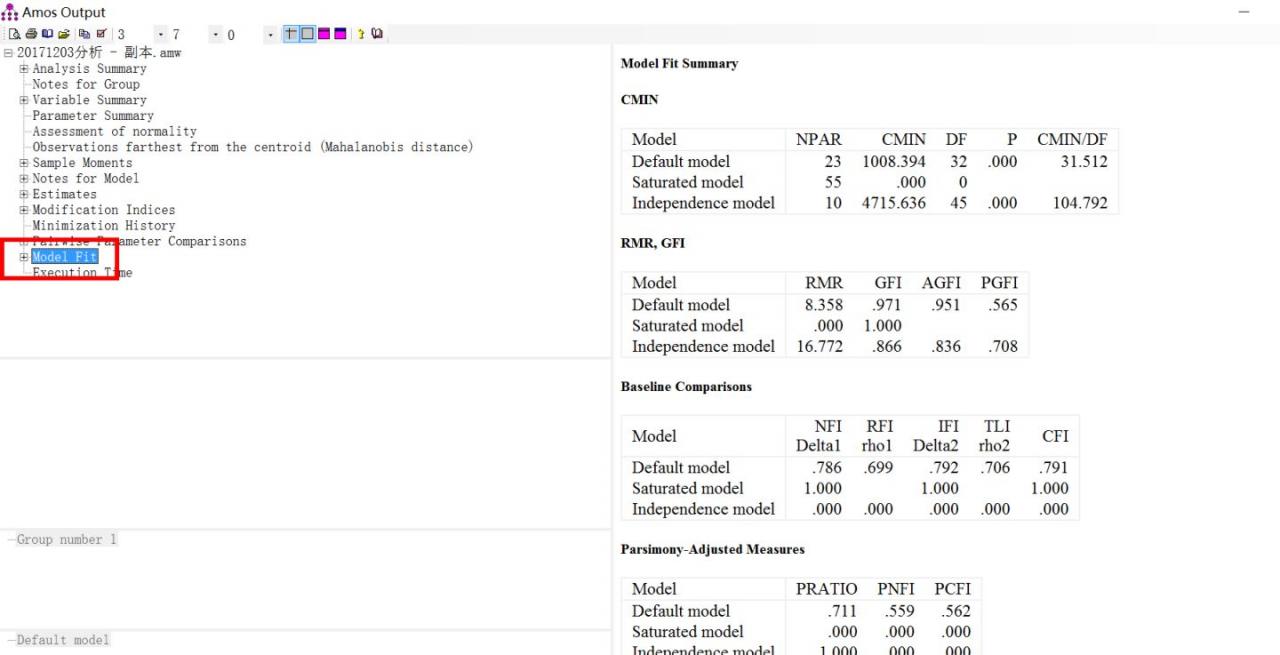

这里看上方可以看见每个匹适度指标下面都分别出现了三个model,分别是默认模型(default model),饱和模型(saturated model)和独立模型(independent model)。我们看default model的值。
在匹适度的输出结果里面小伙伴就可以找到NFI,CFI, IFI, SRMR和 NNFI, 还差RMSEA和卡方/自由度(NC值)的值,NC值可以在输出的“notes for model”里面自己用卡方值除以自由度,也可以和在title那里查,RMSEA的值也在那里。title怎么做见上一篇文章。
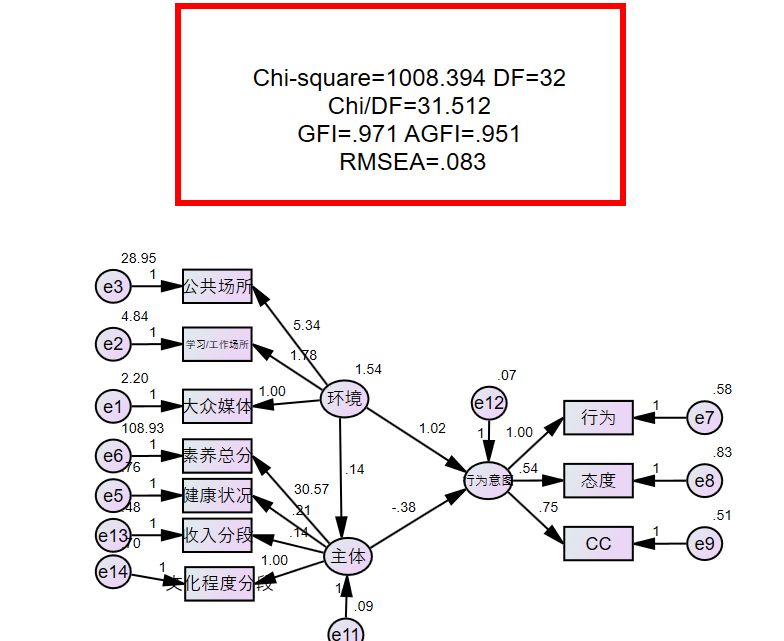

匹适度的报告格式就像刚才那篇英文paper里面的格式就可以了,或者看到哪篇paper的报告格式顺眼就借鉴(抄袭,划掉)就可以啦。
正态性检验
在结果里面的assessment of normality里面,见下图,min是最小值,max是最大值,skew是偏度,kurtosis是峰度,c.r.是显著性检验,在符合正态性的情况下,峰度和偏度系数应该接近0,显著性检验的值和1.96比,要是其绝对值大于1.96则证明非正太。Kline(1998)认为偏度系数大于3,峰度系数大于8,则样本非正太,要是峰度系数大于20,则样本存在严重偏态。下图就是收入分段的峰度系数最大,为12.509,大于8小于20。


所以从正态性的检验来看,上一篇我们用的是MLS估计,是初步的估计,接下来的估计我们应该用ADF进行估计。
本文来自zhihu,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhuanlan.zhihu.com/p/31665403
注意:本文归作者所有,未经作者允许,不得转载

