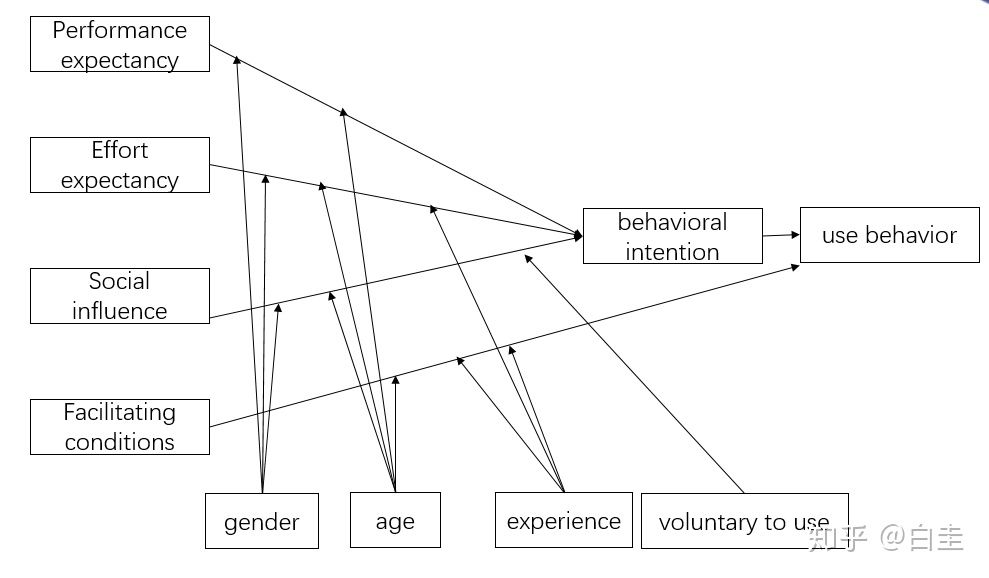
介绍一下这次用的模型是这个

这次采用的是问卷了,我们从原始数据开始处理。
第一步 无效问卷处理
首先把无效问卷给删除了
网络调查的话,可以从填写问卷时间过短、来源于同一IP(这个可能不是很准),初步删除一些问卷。如果问卷设计有逻辑选项的话,再根据问卷设计逻辑判断。
纸质版的话,如果大面积都是同一个选项,或者大面积空白的,直接弃了吧。
问卷设计和筛选这一块资料很多,查一查就有了,不开坑。
1.删除unengaged responses
说一下如何查找大面积都是统一选项或者按照12344321这种随便填的这种unengaged responses
我们用Excel查找,公式=stdevp(单个样本需要跑的数据),这是基于给定的样本总体的标准偏差。


第一个样本的标准差计算出来以后,双击填满整列,就可以知道所有样本中的标准差为0或者接近0,意味着整个回答都是差不多的,整篇都是同一个数值,把他们删了,因为这些样本具有严重的偏性,会使得之后分析的时候数据不会成正态分布。
点击刷选把标准差为0的样本都删了,无效样本还挺多的,心痛。。。。

2.删除极端值或者异常值
看你的问卷有没有年龄要求或者其他的连续变量,看存不存在outlier
Excel画一下散点图就出来了,用检验和年龄画
第二步 检查一下是否有缺失值
第一种方法 Excel
需要amos处理的数据是不能有缺失值的,否则跑不出来结果的,所以如果缺失值过多的样本
这个在Excel里面操作比较好,用公式=countblank(单个样本需要跑的数据)


第一个样本的缺失值计算出来以后,双击填满整列,就可以知道所有样本中哪个样本有缺失值,缺失了多少个样本。

第二种方法 SPSS
点击分析-描述统计-频率,把需要判断是否有缺失值的样本选进去。

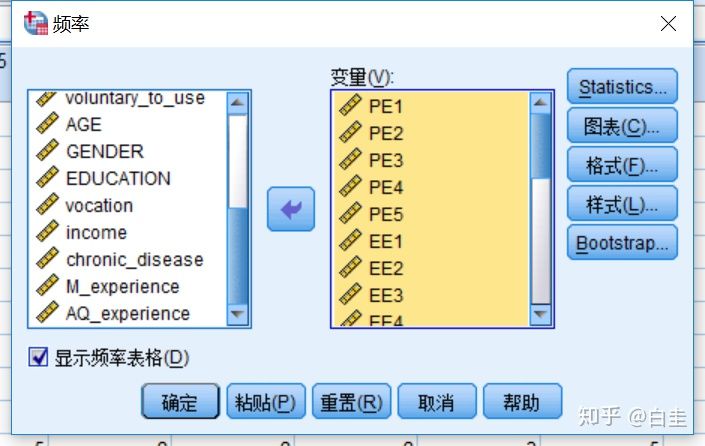

看结果可以知道是哪一个维度有缺失值


如果缺失值过多的,可视为无效值,直接将该样本删除(Listwise Deletion),如果只是缺了2个3个空(一般是问卷题量的5%),可以可以用插补的方式补全问卷。
第三步 缺失值插补
见下图,SPSS里面的插补方法有序列平均值、邻近点的平均值、邻近点的中位数、线性插值、线性趋势。缺失值的插补要根据该缺失值的性质来判断。
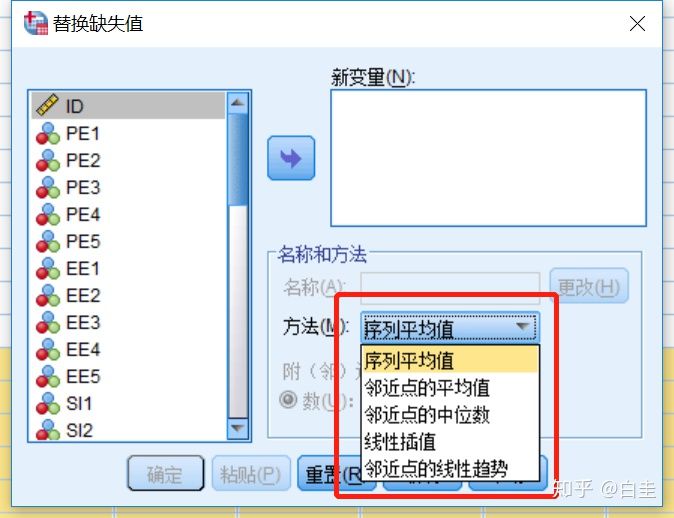

序列平均值:序列数据、连续数据(经验、年龄)可以用
邻近点的的平均值/中位数:建议是对量表有分为区块衡量的问卷数据使用
线性(回归)及趋势的:建议是明确知道某几个数据之间是有关系的
SPSS操作:选择转换–替换缺失值
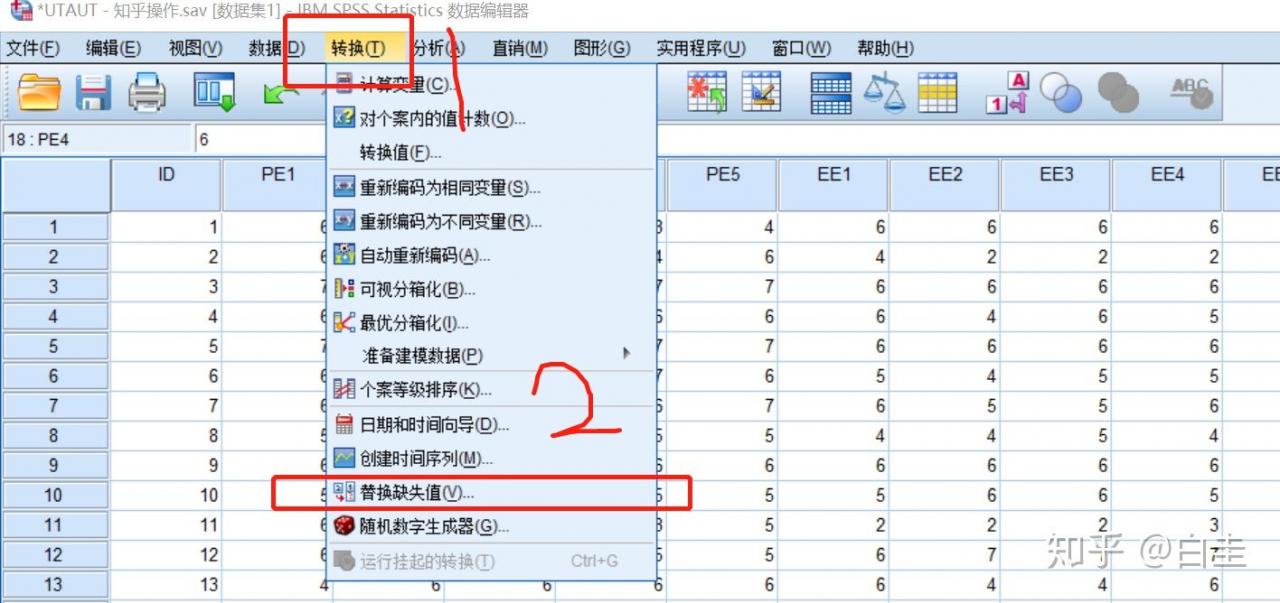

把刚才频率分析知道的存在缺失值的序列选进去
见下图,选择“临近点的中位数”,跨度选择“全部”,最后点击“更改”
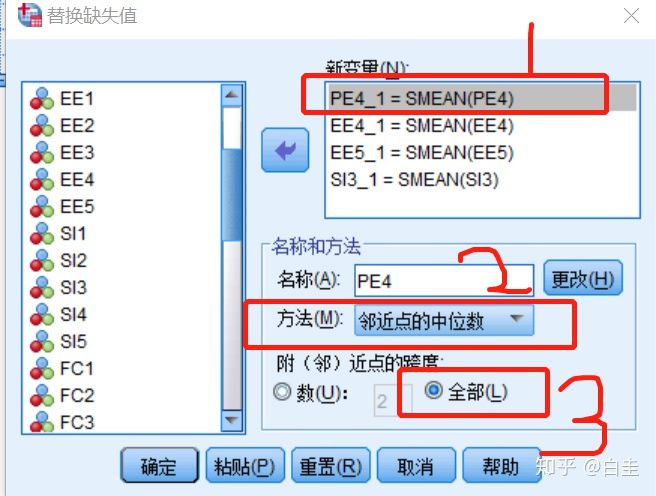

操作完的结果见下图,点击确定就可以了。
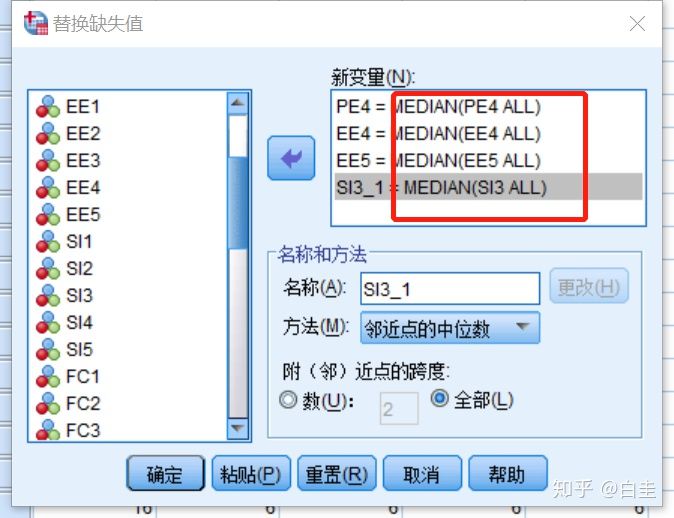

然后就都插补完了。
第四步 用因子分析去检验问卷的区分度
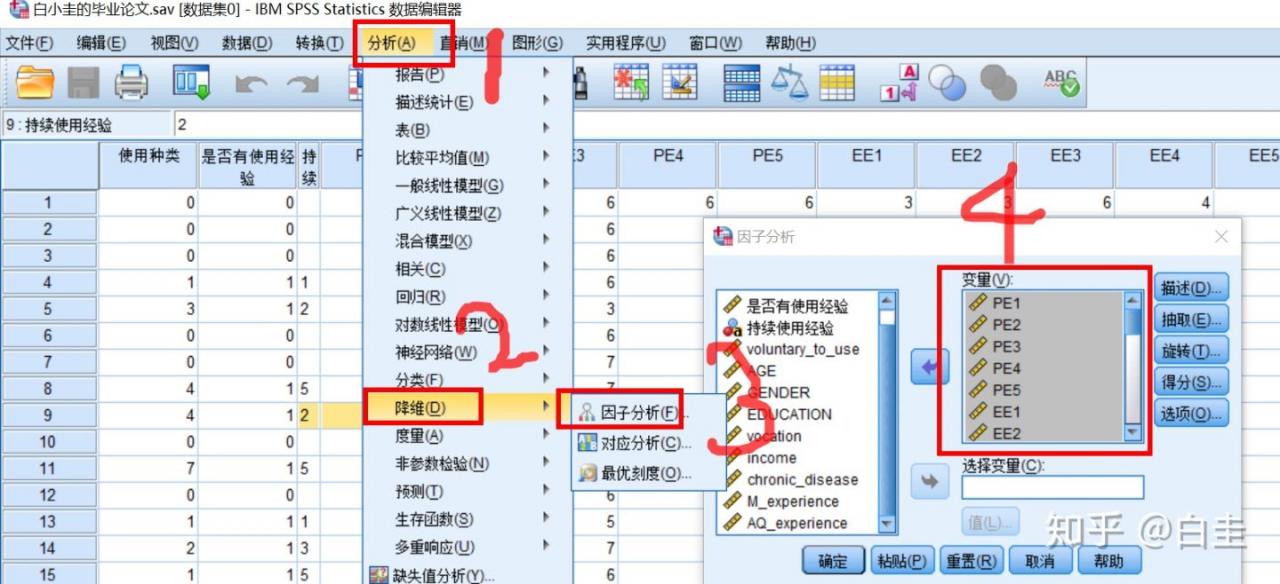
把测量潜变量的指标选进去因子分析
选择:分析–降维–因子分析—选入衡量潜变量的问卷条目
attention:不要把年龄、性别这些分类变量调节变量选进去,只要衡量潜变量维度的问卷条目

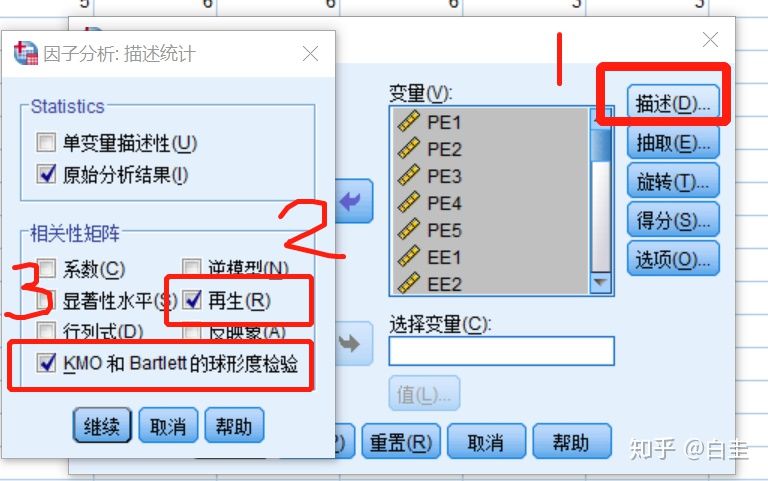
选择描述–把“再生”和“KMO和Bartlett球形度检验”选上

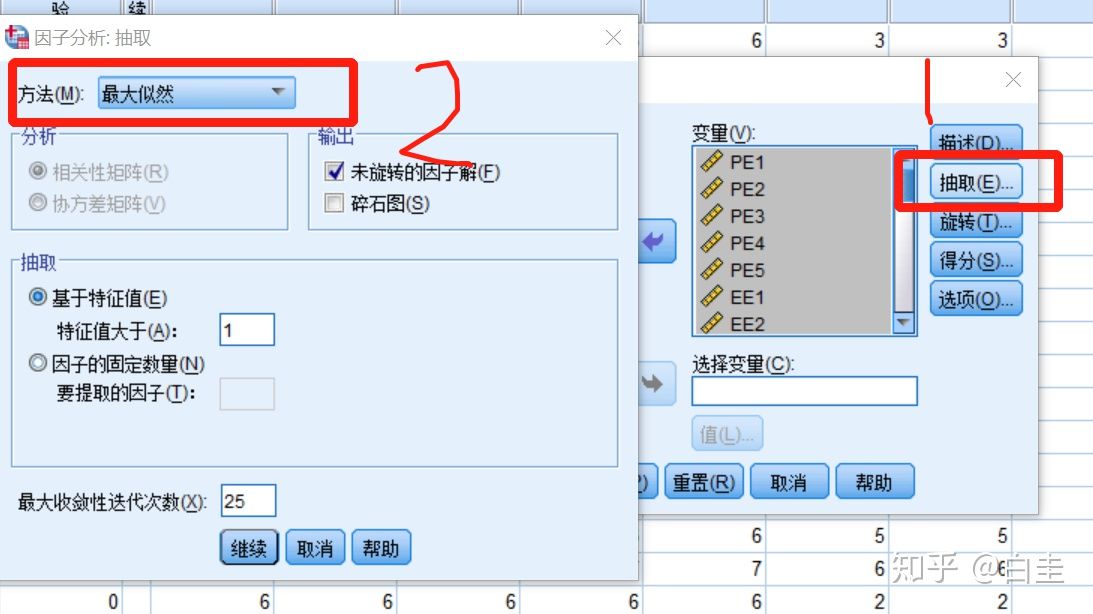
选择抽取–选择极大似然法进行估计

因子旋转我们选择Promax
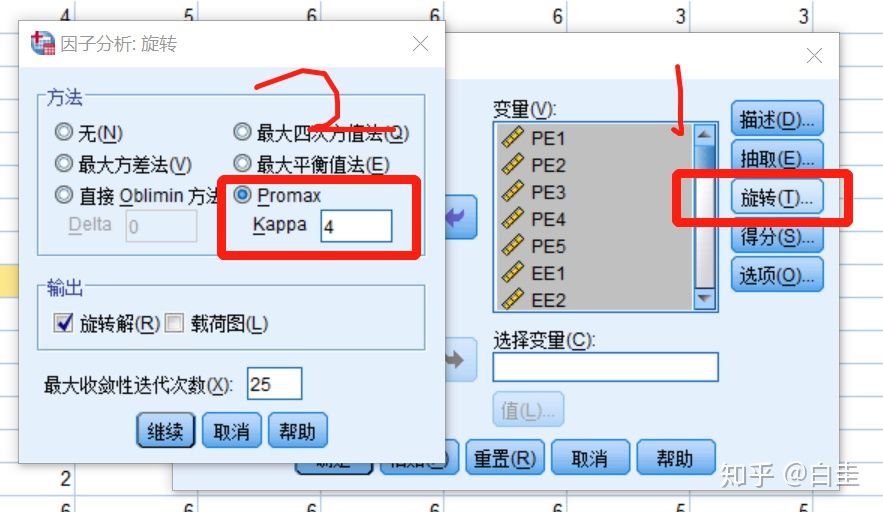

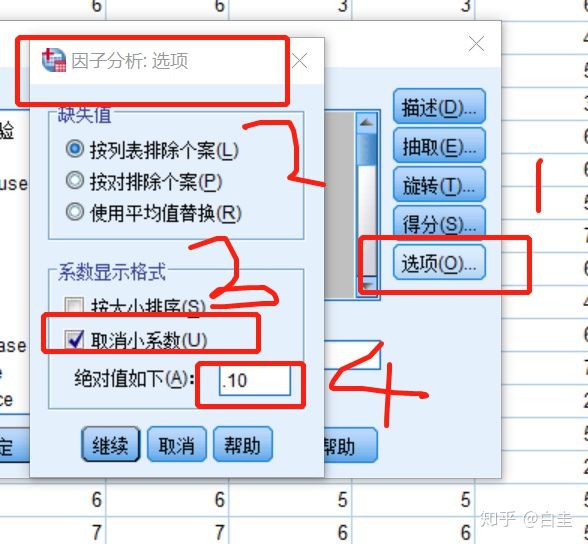
得分不用动,修改“选项”里面的系数显示格式,如改为取消小系数绝对值改为0.3。

最后就是点击OK啦,看output
首先看KMO值,这里是0.95,结果很nice,只要大于0.7就是理想哒


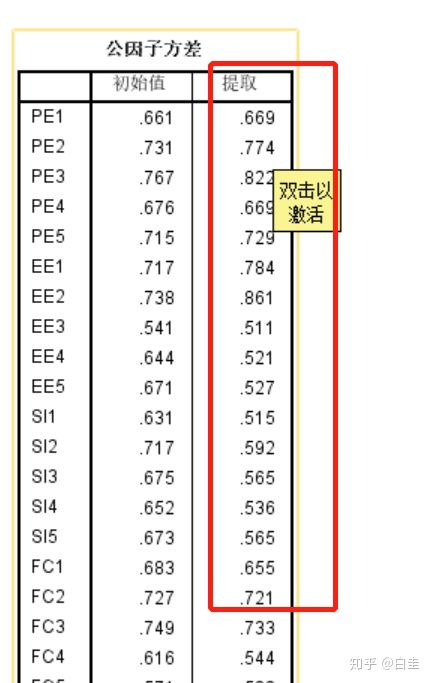
接下来看因子提取,检查一下是否存在提取存在小于0.3的,吼吼吼,都木有,果然亲生的问卷质量还是高

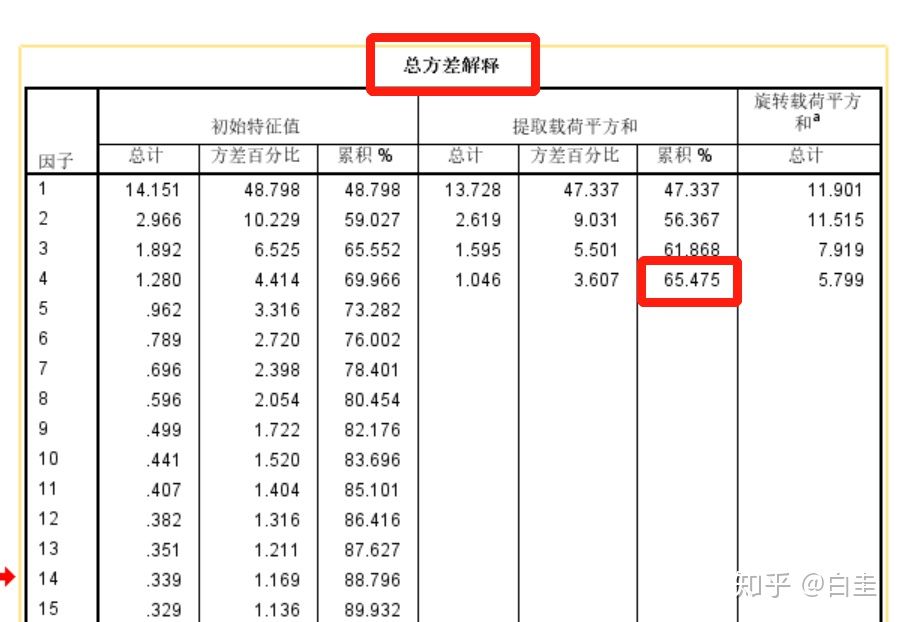
接下来是总方差解释的比例,见下图,可以累积解释65.475%,nice,只要高于60%就OK了(55%也能接受)。

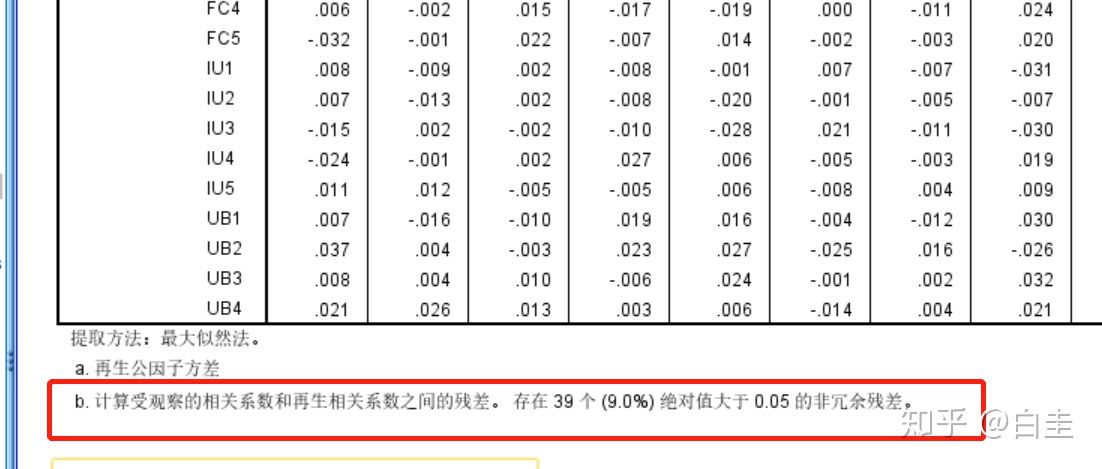
接下来是再生相关系数矩阵,看非冗余残差的占比,理想情况下要小于5%,我的是9%,呵,不理想,那就不报告这个结果就行了。。。

接下来是因子矩阵,这个是检验区分度的,不是特别理想,但是可以改,红色框起来的就是cross-loading,区分度不是很好。
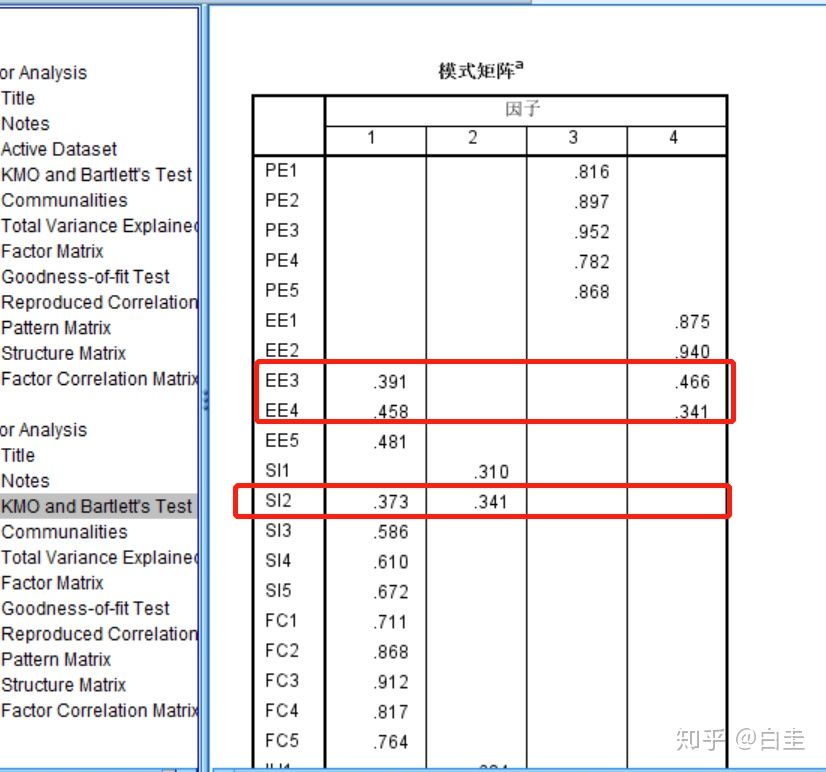

区分度的问题好像我还看见其他其他作者的报道(我文章读的少),没有文献我就不知道应该报道什么结果了。下次看见再说。
检验的话参照AMOS分析
本文来自zhihu,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhuanlan.zhihu.com/p/36711537
注意:本文归作者所有,未经作者允许,不得转载

