1.引言
随着统计科学的日益发展,其对其他学科的渗透作用日益增强,数据分析方法在医学、生物学、社会学等各个学科中得到了广泛的应用,本文试图对收集到的某个临床医学数据运用决策树、神经网络、支持向量机、随机森林等各种现代分类方法进行分析,以佐证数据挖掘对其他学科的重要意义;另一方面,就各种现代分类方法的实际效果进行对比。
笔者从网上收集到关于某个脊椎病变的临床医学数据,该数据集为真实公开的非人造数据,公布地址为:http://archive.ics.uci.edu/ml/datasets/Vertebral+Column。该数据集记录了病人的骨盆和形状位置特征,分别为盆腔炎的发病率,骨盆倾斜,腰椎前凸角度,骶骨倾斜,骨盆半径和品位滑脱(pelvic incidence, pelvic tilt, lumbar lordosis angle,sacral slope, pelvic radius and grade of spondylolisthesis),均为连续型变量。因变量为分类变量,用于甄别病人正常与不正常(Normal &Abnormal)。全数据集共包含310个样本,信息完整,无缺失值。
>weka2C<-read.csv(“F:\\column_2C_weka.csv”,header=TRUE)
>summary(weka2C)
2.现代分类方法分析
通过对数据集的观察,前210位病人均被检测为不正常(Abnormal),后100位病人被检测为正常(Normal)。为方便对模型效果进行评价并对不同的模型进行对比,本文将从两个群体中各随机抽取一半的样本作为训练集,另一半作为测试集。
>set.seed(2)
>samp<-c(sample(1:210,105),sample(211:310,50))
2.1 决策树算法
决策树是一种逼近离散函数值的典型分类算法,对于非离散变量,将连续型数据离散化同样可以进行决策树分析。决策树的本质是利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。以下就运用决策树算法对原始临床数据进行分析。
>library(rpart)
>weka2C.rp<-rpart(class2~.,weka2C[samp,])
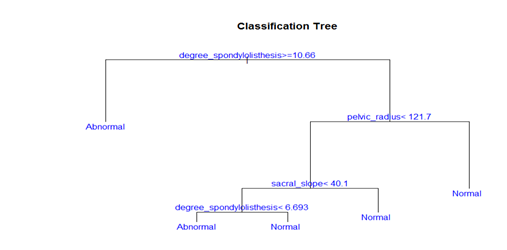
>plot(weka2C.rp,branch=1,margin=0.2,main=”ClassificationTree”)
>text(weka2C.rp,col=”blue”)
通过Plot函数可绘出训练的决策树模型。
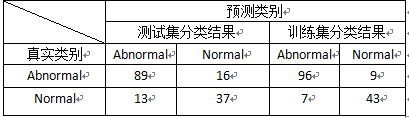
>tabe(weka2C$class2[-samp],predict(weka2C.rp,weka2C[-samp,],type=”class”))
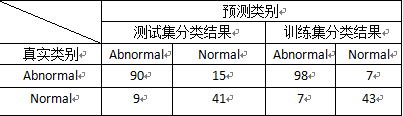
>table(weka2C$class2[samp],predict(weka2C.rp,weka2C[samp,],type=”class”))
通过的得到的决策树模型对测试集和训练集进行分类得到以下结果,测试集判错率为0.18709,训练集的判错率为0.10322。
2.2 bagging
Bagging利用了自助法(bootstrap)放回抽样。它对训练样本做许多次(比如k次)放回抽样,每次抽取和样本量同样的观测值,于是产生k个不同的样本。然后,对每个样本生成一个决策树。这样,每个树都对一个新的观测值产生一个预测,由这些树的分类结果的多数(“投票”)产生bagging的分类。
>library(adabag)
>ibrary(rpart)
>weka.bag=bagging(class2~.,data=weka2C[samp,],mfinal=25,control=rpart.control(maxdepth=5))
>weka.pred=predict.bagging(weka.bag,newdata=weka2C[-samp,])
>weka.pred[-1]
>weka.predt=predict.bagging(weka.bag,newdata=weka2C[samp,])
>weka.predt[-1]
最终得到bagging分类结果,其测试集判错率为0.15484,训练集判错率为0.09032。
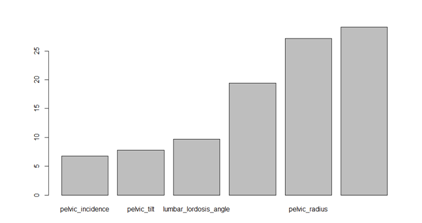
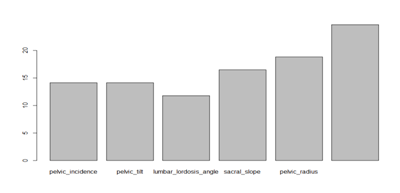
同时我们可以得到分类过程中变量的重要性,可看出,品位滑脱(grade of spondylolisthesis)是最重要的影响变量。
>barplot(weka.bag$importance)
2.3 Adaboost
Adaboost是一种迭代分类算法,不断地通过加权再抽样改进分类器,每一次迭代时都针对前一个分类器对某些观测值的误分缺陷加以修正,通常是在(放回)抽取样本时对那些误分的观测值增加权重(相当于对正确分类的减少权重),这样就形成一个新的分类器进入下一轮迭代。在每轮迭代时都对这一轮产生的分类器给出错误率,最终结果由各个阶段的分类器的按照错误率加权投票产生。
以下通过Adaboost对临床数据集进行分析:
>library(mlbench)
>library(adabag)
>library(rpart)
>weka.adab=boosting(class2~.,data=weka2C[samp,],mfinal=15,control=rpart.control(maxdepth=5)
>weka.pred<-predict.boosting(weka.adab,newdata=weka2C[-samp,])
>weka.pred[-1]
>weka.predt<-predict.boosting(weka.adab,newdata=weka2C[samp,])
>weka.predt[-1]
得到模型对数据集的分类情况,测试集的判错率为0.14193,训练集无判错。
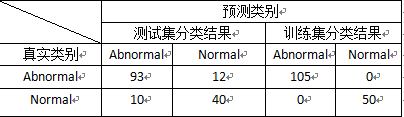
与Bagging类似,可以输出模型训练过程中得到的变量重要性,大致结果与Bagging类似,品位滑脱(grade of spondylolisthesis)是最重要的影响变量。
>barplot(weka.adab$importance)
2.4 神经网络算法
人工神经网络(ArtificialNeural Networks)是对自然的神经网络的模仿;它可以有效地解决很复杂的有大量互相相关变量的回归和分类问题,我们同样可以用之建立脊椎病变临床数据集的分类模型。
>library(nnet)
>weka.nn1=nnet(class2~.,data=weka2C,subset=samp,size=10,rang=0.1,decay=5e-4,maxit=1000)
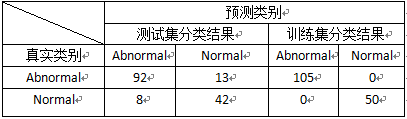
>table(weka2C$class2[-samp],predict(weka.nn1,weka2C[-samp,],type=”class”))
>table(weka2C$class2[samp],predict(weka.nn1,weka2C[samp,],type=”class”))
类似的,利用训练得到的神经网络模型对数据集重新进行分类,测试集判错率为0.13548。
2.5 k最近邻方法
K最近邻方法是经典的分类算法,其基本算法思想为以待测样本的k个最近距离的样本点的所属类别进行投票决定待分类样本点的类别。
>library(kknn)
>weka.knn<-kknn(class2~.,k=20,weka2C[samp,],weka2C[-samp,],distance=1,kernel=”triangular”)
>summary(weka.knn)
>fit<-fitted(weka.knn)
>table(weka2C[-samp,]$class2,fit)
用k最邻近方法得到的预测类别结果显示判错率为0.18065。

2.6 随机森林方法
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。随机森林的重要优点是可以解决多变量样本不足的问题,尽管此次临床数据样本足够,可依然可以尝试用随机森林进行分类。
>library(randomForest)
>weka.rf=randomForest(class2~.,data=weka2C[samp,],importance=TRUE,proximity=TRUE)
>rf.pre<-
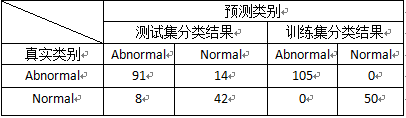
>table(weka2C[-samp,]$class2,predict(weka.rf,weka2C[-samp,]))
>table(weka2C[samp,]$class2,predict(weka.rf,weka2C[samp,])
通过得到的随机森林模型对测试集和训练集进行分类,测试集判错率为0.14193。
2.7 支持向量机
支持向量机是另一种现代分类方法,用支持向量机脊椎病变临床数据集进行分析基于R的实现代码如下:
>library(class)
>library(e1071)
>model<-svm(class2~.,data=weka2C[samp,],kernal=”sigmoid”)
>table(pred.train<-fitted(model),weka2C[samp,]$class2)
>table(predict(model,weka2C[-samp,-7]),weka2C[-samp,]$class2)
用得到模型对数据集进行分类,测试集判错率为0.18065,训练集判错率为0.13548。
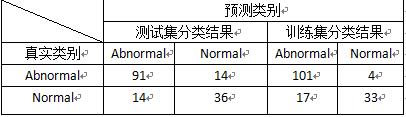
3.现代分类方法效果对比
为对以上的现代分类方法分类效果进行评价,重新对各个模型的预测情况进行整合。从每个模型的分类效果可以看出,Adaboost、神经网络和随机森林分类效果相对较好,测试集的准确率达到了85%以上。决策树、K最邻近方法、支持向量机的分类效果最差,但准确率也达到了80%以上,具有应用的价值。
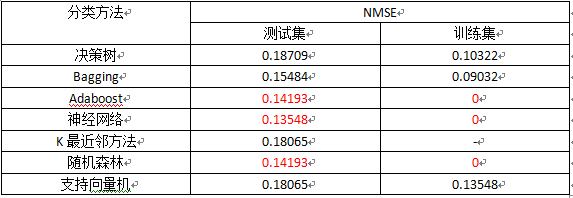
4.结语
通过不同的分类方法建立不同的脊椎病变诊断模型,其准确均达到了80%以上,对临床医学上的诊断具有一定的参考价值,在一定程度上可以通过盆腔炎的发病率,骨盆倾斜,腰椎前凸角度,骶骨倾斜,骨盆半径和品位滑脱程度等信息对病人进行诊断,证实了数据挖掘对其他学科的重要意义,数据科学时代即将到来。
另一方面,选择分类模型的过程中需要根据数据集情况尝试运用不同的分类方法,并用交叉验证的方法对模型进行检测,最后选择兼具准确性和稳定性的分类模型,以实现数据的最高利用价值。
来自 http://f.dataguru.cn/thread-2076-1-1.html
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e7%8e%b0%e4%bb%a3%e5%88%86%e7%b1%bb%e6%96%b9%e6%b3%95%e5%9c%a8%e5%8c%bb%e5%ad%a6%e8%af%8a%e6%96%ad%e4%b8%ad%e7%9a%84%e5%ba%94%e7%94%a8-%e5%9f%ba%e4%ba%8er%e7%9a%84%e5%ae%9e%e7%8e%b0/
注意:本文归作者所有,未经作者允许,不得转载

