from http://blog.163.com/zzz216@yeah/blog/static/16255468420121105146675/
1 用CLUSTER过程和TREE过程进行谱系聚类
一、CLUSTER过程用法
CLUSTER过程的一般格式为:
PROC CLUSTER DATA=输入数据集
METHOD=聚类方法 选项:
VAR 聚类用变量:
COPY 复制变量:
RUN;
其中的VAR语句指定用来聚类的变量。COPY语句把指定的变量复制到OUTTREE=的数据集中。
PROC CLUSTER语句的主要选项有:
·METHOD=选项,这是必须指定的,此选项决定我们要用的聚类方法,主要由类间距离定义决定。方法有AVERAGE,CENTROID,COMPLETE, SINGLE, DENSITY, WARD, EML, FLEXIBLE, MCQUITTY, MEDIAN, TWOSTAGE等,其中DENSITY,TWOSTAGE等方法还要额外指定密度估计方法(K=,R=或HYBRID)。
·输入DATA=数据集,可以是原始观测数据集,也可以是距离矩阵数据集。
·OUTTREE=输出谱系聚类树数据集,把谱系聚类树输出到一个数据集,可以用TREE过程绘图并实际分类。
·STANDARD选项,把变量标准化为均值0,标准差1。
·PSEUDO选项和CCC选项。PSEUDO选项要求计算伪F和伪t2统计量,CCC选项要求计算R2、半偏R2和CCC统计量。其中CCC统计量也是一种考察聚类效果的统计量,CCC较大的聚类水平是较好的。
二、TREE过程用法
TREE过程可以把CLUSTER过程产生的OUTTREE=数据集作为输入,画出谱系聚类的树图,并按照用户指定的聚类水平(类数)产生分类结果数据集。一般格式如下:
PROC TREE DATA=输入聚类结果数据集
OUT=输出数据集GRAPHICS
NCLUSTER=类数选项:
COPY复制变量:
RUN;
其中COPY语句把输入数据集中的变量复制到输出数据集(实际上这些变量也必须在CLUSTER过程中用COPY语句复制到OUTTREE一数据集)。PROC TREE语句的重要选项有:
- DATA=数据集,指定从CLUSTER过程生成的OUTTREE=数据集作为输入。
- OUT=数据集,指定包含最后分类结果(每一个观测属于哪一类,用一个CLUSTER变量区分)的输出数据集。
- NCLUSTERS=选项,由用户指定最后把样本观测分为多少个类。
- HORIZONTAL,画树图时横向画。
例:有三种不同鸢尾花(Setosa,、Versicolor、Virginica),种类信息存入了变量SPECIES,并对每一种测量了50棵植株的花瓣长(PETALLEN),花瓣宽(PETALWID),花萼长(SEPALLEN),花萼宽(SEPALWID)。这个数据己知分类,并不属于聚类分析的研究范围。这里我们为了示例,假装不知道样本的分类情况(既不知道类数也不知道每一个观测属于的类别),让SAS取进行聚类分析,为了进行谱系聚类并产生帮助确定类数的统计量,使用如下过程:

部分结果如下:
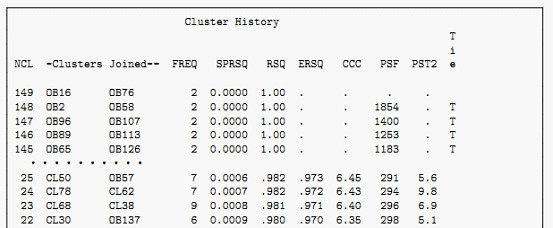
这个输出列出了把150个观测每次合并两类,共合并149次的过程。NCL列指定了聚类水平G(即这一步存在的单独的类数)。”-Clusters Joined-“为两列,指明这一步合并了哪两个类。其中OBxxx表示哪一个原始观测,而CLxxx表示在哪一个聚类水平上产生的类。比如,NCL为149时合并的是OB16和OB76,即16号观测和76号观测,NCL为1合并的是CL5和CL2,即类水平为5时得到的类和类水平为2时得到的类, FREQ表示这次合并得到的类有多少个观测。SPRSQ是半偏R2,RSQ是R2,ERSQ是在均匀零假设下的R2的近似期望值,CCC为CCC统计量,PSF为伪F统计量,PST2为伪t2统计量,Tie指示距离最小的候选类对是否有多对。
假设我们知道要分成3类,所以我们用如下的TREE过程绘制树图并产生分类结果数据集:

原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/sas%e8%81%9a%e7%b1%bb%e5%88%86%e6%9e%90/
注意:本文归作者所有,未经作者允许,不得转载

