本文以iris鸢尾花数据为例,实现各种聚类算法。
文章里理论部分很简略,主要是python实践。
没想到疫情期间度过了研一下学期,全在上网课,仍然是获益匪浅。
正好在上机器学习的课程做了结课报告,感谢华中师大张雄军老师,疯狂鞭笞我们去实践,小白上了一学期机器学习学到很多,终于入门了呜呜呜~~~
一、聚类算法
聚类算法即分类算法。分类的输入项是数据的特征,输出项是分类标签,它是无监督的。
为什么要聚类?对大量数据简化表示,寻找对数据结构的新见解。
聚类算法的重要概念:
不相似性:
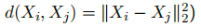

类间距离:
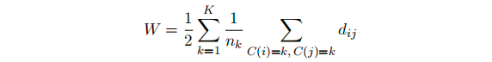

聚类算法希望类间距离越小越好。
聚类算法簇类数量K的确定:
(1)CH index; (2)Gap statistic
二、聚类算法分类介绍
常见的聚类规则包括:
1)基于原型的,例如有通过质心或中心点聚类,
常见算法:KMeans、kmediods;
2)基于图的,也就是通过节点和边的概念,形成连通分支的分类,
常见算法:hierarchical clustering;
3)基于密度的,根据数据密度的大小进行聚类,
常见算法:DBSCAN密度聚类;
4)基于统计的聚类,数据一般符合一种或几种概率分布,根据概率分布情况进行聚类。
常见算法:高斯混合模型;
三、理论介绍(很简略)
1. KMeans、Kmediods
原理比较简单,网上都有
2. 凝聚层次聚类Agglomerative hierarchical
又可以分为 linkage=single、complete、average、centroid
凝聚层次聚类中重要概念linkage:衡量两个group之间的不相似性


其中 ,主要有single、complete、average、centroid类型:
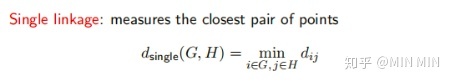

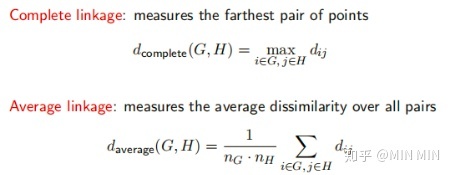

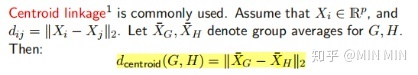

3. DBSCAN
以DBSCAN聚类为例,核心思想就是先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。如下图
算法实现:对每个数据点为圆心,以eps为半径画个圈,然后数有多少个点在这个圈内,这个数就是该点密度值。然后我们可以选取一个密度阈值MinPts,如圈内点数小于MinPts的圆心点为低密度的点,而大于或等于MinPts的圆心点高密度的点。如果有一个高密度的点在另一个高密度的点的圈内,我们就把这两个点连接起来,这样我们可以把好多点不断地串联出来。之后,如果有低密度的点也在高密度的点的圈内,把它也连到最近的高密度点上,称之为边界点。这样所有能连到一起的点就成一了个簇,而不在任何高密度点的圈内的低密度点就是异常点。
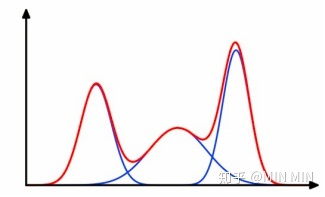
4. 高斯混合模型GMM
使用多个高斯分布的组合来刻画数据分布,如下图

高斯混合模型的概率分布为
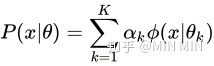

参数
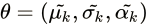

,也就是每个子模型的期望、方差(或协方差)、在混合模型中发生的概率。
聚类的思想即是数据属于哪一个单高斯模型。
经典EM算法求解GMM的参数,这个算法理论过程较复杂,可以网上找找看。
四、代码实现
以经典iris数据为例,经典数据集iris内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
初始条件设置:
考虑到已知真实分类为3类,初始设置超参数:簇类数量K=3;
DBSCAN密度聚类半径设为0.5,高密度阈值设为2。
以下为python代码
###Clustering###
#聚类算法集合#
import numpy as np
import matplotlib.pyplot as plt
from sklearn import cluster
from sklearn import datasets
#导入鸢尾花数据集
iris = datasets.load_iris()
np.random.seed(123456)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
为了实现高维数据可视化,应用TSNE模块
from sklearn.manifold import TSNE
data_TSNE = TSNE(n_components=2).fit_transform(iris.data[:,0:3]) # 进行数据降维原分类可视化
#原分类
x1_axis = data_TSNE[:,0]
x2_axis = data_TSNE[:,1]
real = iris.target
plt.scatter(x1_axis, x2_axis, c=real)
plt.title("真实分类")
plt.show()###kmeans预测
model = cluster.KMeans(n_clusters = 3, max_iter = 1000)
model.fit(iris.data)
predicted = model.predict(iris.data)
print('kmeans预测值',predicted)
plt.scatter(x1_axis, x2_axis, c=predicted)#marker='s', s=100, cmap=plt.cm.Paired)
plt.title("KMeans聚类分析")
plt.show()###kmediods预测
from pyclust import KMedoids
kmediods_model = KMedoids(n_clusters = 3, max_iter= 1000)
kmediods_predicted = kmediods_model.fit_predict(iris.data)
print('kmediods预测值',kmediods_predicted)
plt.scatter(x1_axis, x2_axis, c=kmediods_predicted)
plt.title("KMediods聚类分析")
plt.show()###凝聚层次聚类Agglomerative
#linkage=’single’
Agglomerative_single_model = cluster.AgglomerativeClustering(linkage='single',n_clusters = 3)
Agglomerative_single_model.fit(iris.data)
print('single预测值',Agglomerative_single_model.labels_)
plt.scatter(x1_axis, x2_axis, c=Agglomerative_single_model.labels_)
plt.title("Agglomerative single层次聚类")
plt.show()#linkage=’complete’
Agglomerative_complete_model = cluster.AgglomerativeClustering(linkage='complete',n_clusters = 3)
Agglomerative_complete_model.fit(iris.data)
print('complete预测值',Agglomerative_complete_model.labels_)
plt.scatter(x1_axis, x2_axis, c=Agglomerative_complete_model.labels_)
plt.title("Agglomerative complete层次聚类")
plt.show()#linkage=’average’
Agglomerative_average_model = cluster.AgglomerativeClustering(linkage='average',n_clusters = 3)
Agglomerative_average_model.fit(iris.data)
print('average预测值',Agglomerative_average_model.labels_)
plt.scatter(x1_axis, x2_axis, c=Agglomerative_average_model.labels_)
plt.title("Agglomerative average层次聚类")
plt.show()#Centroid linkage
import scipy.cluster.hierarchy as hcluster
Centroid_linkage = hcluster.linkage(iris.data, method='centroid')
p = hcluster.fcluster(Centroid_linkage, t=3, criterion='maxclust')
print('Centroid预测值',p)
plt.scatter(x1_axis, x2_axis, c=p)
plt.title("Agglomerative Centroid层次聚类")
plt.show()###密度聚类
#DBSCAN
DBSCAN_model = cluster.DBSCAN(eps = 0.5, min_samples = 2).fit(iris.data) #eps:在一个点周围邻近区域的半径
#minPts:邻近区域内至少包含点的个数
print('DBSCAN预测值',DBSCAN_model.labels_)
plt.scatter(x1_axis, x2_axis, c=DBSCAN_model.labels_)
plt.title("DBSCAN聚类")
plt.show()###高斯混合模型聚类GMM
#基于EM算法
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=3).fit(iris.data)
labels = gmm.predict(iris.data)
print('GMM预测值',labels)
plt.scatter(x1_axis, x2_axis, c=labels)
plt.title("GMM-EM聚类")
plt.show()最终聚类图像为
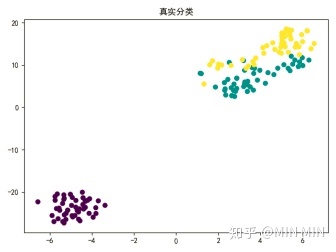

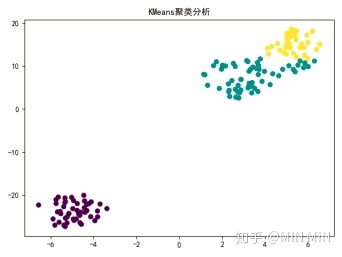

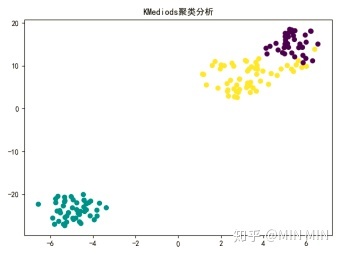

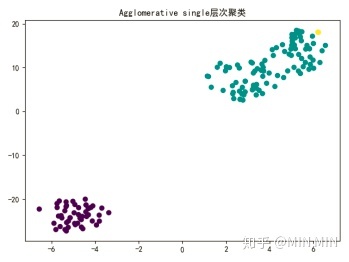

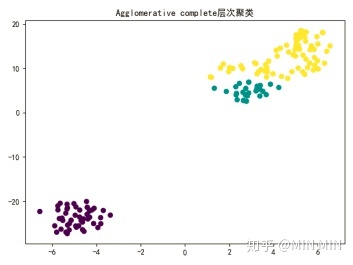

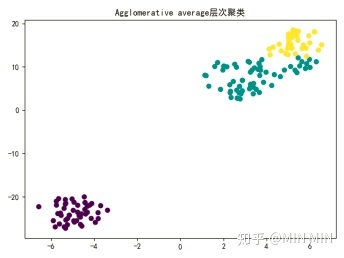

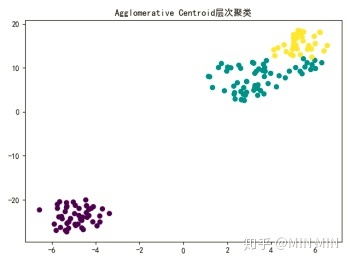

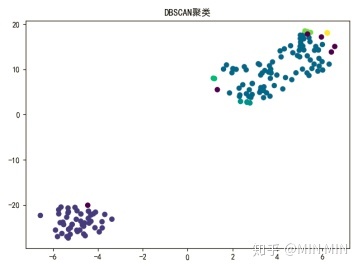

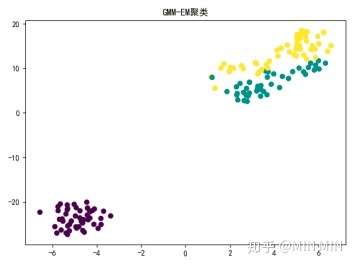

聚类算法作为一个无监督学习算法,是无法像监督学习那样计算精确度的。不过本题中已知iris的真实分类,笔者还是做了一个准确度的比较。(这部分代码没有放上来了,实践中用不到准确度。)
评价指标:purity(纯度),正确分类数据量占总数据量的比例。
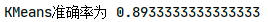

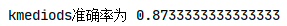

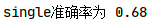

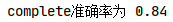

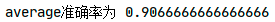

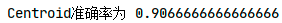

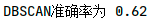

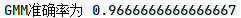

准确率排序:

可看出GMM最适用于此模型,准确率最高。
由于聚类是无监督学习方法,不同的聚类方法基于不同的假设和数据类型。由于数据通常可以以不同的角度进行归类,因此没有万能的通用聚类算法,并且每一种聚类算法都有其局限性和偏见性。
本文来自zhihu,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhuanlan.zhihu.com/p/150333968
注意:本文归作者所有,未经作者允许,不得转载

