docker pull cloudera/quickstart
// 或者在 cloudera 官网下载文件后使用 `docker import` 命令导入
// https://downloads.cloudera.com/demo_vm/docker/cloudera-quickstart-vm-5.13.0-0-beta-docker.tar.gz
添加 hosts
quickstart.cloudera 指向宿主机的 IP
vim /etc/hosts
xx.xx.xx.xx quickstart.cloudera
启动服务(宿主机要求 8G 内存)
docker run -d --name cdh --hostname=quickstart.cloudera --privileged=true -p 8020:8020 -p 8022:8022 -p 7180:7180 -p 21050:21050 -p 50070:50070 -p 50075:50075 -p 50010:50010 -p 50020:50020 -p 8890:8890 -p 60010:60010 -p 10002:10002 -p 25010:25010 -p 25020:25020 -p 18088:18088 -p 8088:8088 -p 19888:19888 -p 7187:7187 -p 11000:11000 -p 8888:8888 -p 2181:2181 -p 10000:10000 cloudera/quickstart /bin/bash -c '/usr/bin/docker-quickstart && /home/cloudera/cloudera-manager --express --force && service ntpd start && tail -F /var/log/*.log'
等待几分钟后,打开
http://quickstart.cloudera:7180
用户名密码均为 cloudera
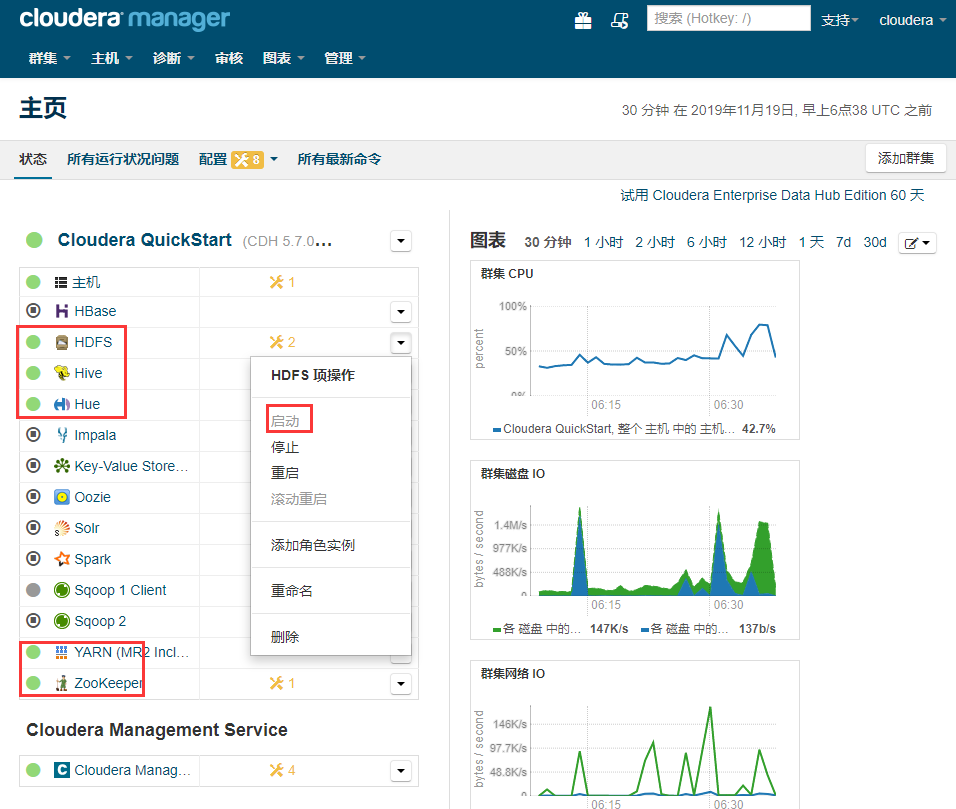
在网页上启动 HFDS Hive Yarn zookeeper Hue 这些服务
等待全部启动完成后,打开
http://quickstart.cloudera:8888
用户名密码均为 cloudera
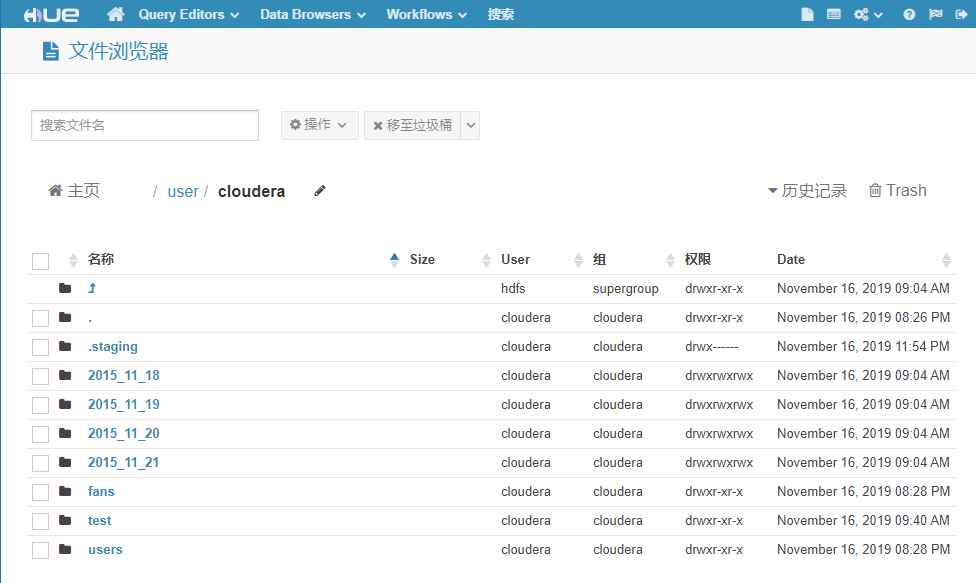
在这里就可以方便的查看 hdfs 文件以及通过 hive 查询数据了
HDFS UI: http://quickstart.cloudera:8888/filebrowser/
Hive UI: http://quickstart.cloudera:8888/beeswax/
使用 python 读写 hdfs 示例
编辑待上传的示例文件:
data1.csv
user_id,name,sex,age
10001,张三,1,20
10002,李四,0,18
10003,王五,1,27
10004,赵六,1,33
data2.csv
user_id,fans_id,time
10001,10002,2019-10-01
10001,10003,2019-11-03
10002,10003,2019-10-22
10002,10004,2019-11-02
10003,10001,2019-09-13
10004,10001,2019-09-08
10004,10002,2019-10-08
10004,10003,2019-11-15
安装 hdfs 模块
pip install hdfs
python 脚本
import hdfs
client = hdfs.InsecureClient('http://quickstart.cloudera:50070', user='cloudera')
# 浏览目录
print(client.list('/'))
# 创建目录
client.makedirs('/user/cloudera/users')
client.makedirs('/user/cloudera/fans')
# 上传文件
client.upload('/user/cloudera/users/data.csv', './data1.csv', overwrite=True)
client.upload('/user/cloudera/fans/data.csv', './data2.csv', overwrite=True)
print('upload success!')
# 读取 hdfs 文件内容
with client.read('/user/cloudera/users/data.csv') as r:
print(r.read())
Hive 操作示例
打开页面 http://quickstart.cloudera:8888/beeswax/
输入脚本创建外部表
create external table users
(user_id int, name string, sex int, age int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
location '/user/cloudera/users'
tblproperties("skip.header.line.count"="1");
create external table fans
(user_id int, fans_id int, time string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
location '/user/cloudera/fans'
tblproperties("skip.header.line.count"="1");
点击 执行 按钮,完成表创建
再输入查询脚本
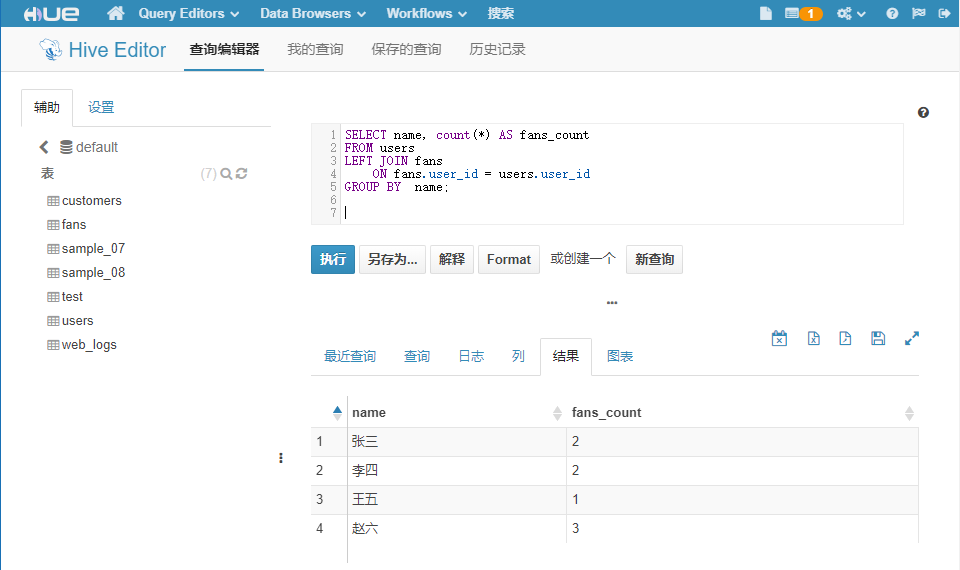
SELECT name, count(*) AS fans_count
FROM users
LEFT JOIN fans
ON fans.user_id = users.user_id
GROUP BY name;
点击 执行 按钮,等待一段时间后查看到统计结果
使用 python 进行 hive 查询
安装 PyHive模块
apt-get install libsasl2-dev -y
pip install sasl
pip install thrift
pip install thrift-sasl
pip install PyHive
python 脚本
from pyhive import hive
conn = hive.Connection(host='quickstart.cloudera', port=10000, username='cloudera', database='default')
cursor = conn.cursor()
cursor.execute('select * from users;')
print(cursor.fetchall())
cursor.execute('select count(*) from users;')
print(cursor.fetchone())
cursor.close()
conn.close()作者:taojy123
链接:https://www.jianshu.com/p/5ecf73668b4d
本文来自简书,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://www.jianshu.com/p/5ecf73668b4d
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

