学习交流数据分析、挖掘可以加QQ群 76354029 本贴主要为2015年12月19号晚上8点半的分享交流准备。
内容:
理论、应用、练习
理论:
什么是聚类分析?
聚类分析属于探索性的数据分析方法。通常,我们利用聚类分析将看似无序的对象进行分组、归类,以达到更好地理解研究对象的目的。聚类结果要求组内对象相似性较高,组间对象相似性较低。在用户研究中,很多问题可以借助聚类分析来解决,比如,网站的信息分类问题、网页的点击行为关联性问题以及用户分类问题等等。
聚类分析的基本过程是怎样的?
- 选择聚类变量
- 聚类分析
- 找出各类用户的重要特征
- 聚类解释&命名
常用算法:
kmeans是最简单的聚类算法之一,但是运用十分广泛。
kmeans的计算方法如下:
1 随机选取k个中心点
2 遍历所有数据,将每个数据划分到最近的中心点中
3 计算每个聚类的平均值,并作为新的中心点
4 重复2-3,直到这k个中线点不再变化(收敛了),或执行了足够多的迭代
算法收敛
从kmeans的算法可以发现,SSE其实是一个严格的坐标下降(Coordinate Decendet)过程。设目标函数SSE如下:
![]()
![]()


采用欧式距离作为变量之间的聚类函数。每次朝一个变量Ci
 的方向找到最优解,也就是求偏倒数,然后等于0,可得
的方向找到最优解,也就是求偏倒数,然后等于0,可得
![]()
![]()

 其中m是c_i所在的簇的元素的个数
其中m是c_i所在的簇的元素的个数
也就是当前聚类的均值就是当前方向的最优解(最小值),这与kmeans的每一次迭代过程一样。所以,这样保证SSE每一次迭代时,都会减小,最终使SSE收敛。
由于SSE是一个非凸函数(non-convex function),所以SSE不能保证找到全局最优解,只能确保局部最优解。但是可以重复执行几次kmeans,选取SSE最小的一次作为最终的聚类结果。
0-1规格化
由于数据之间量纲的不相同,不方便比较。举个例子,比如游戏用户的在线时长和活跃天数,前者单位是秒,数值一般都是几千,而后者单位是天,数值一般在个位或十位,如果用这两个变量来表征用户的活跃情况,显然活跃天数的作用基本上可以忽略。所以,需要将数据统一放到0~1的范围,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。具体计算方法如下:
![]()
![]()
其中
 属于A。
属于A。
轮廓系数
轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。具体计算方法如下:
- 对于第i个元素x_i,计算x_i与其同一个簇内的所有其他元素距离的平均值,记作a_i,用于量化簇内的凝聚度。
- 选取x_i外的一个簇b,计算x_i与b中所有点的平均距离,遍历所有其他簇,找到最近的这个平均距离,记作b_i,用于量化簇之间分离度。
- 对于元素x_i,轮廓系数s_i = (b_i – a_i)/max(a_i,b_i)
- 计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数
从上面的公式,不难发现若s_i小于0,说明x_i与其簇内元素的平均距离小于最近的其他簇,表示聚类效果不好。如果a_i趋于0,或者b_i足够大,那么s_i趋近与1,说明聚类效果比较好。
K值选取
在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。
应用:聚类分析在用户分类中的应用
|| 选择聚类变量
在设计问卷的时候,我们会根据一定的假设,尽可能选取对产品使用行为有影响的变量,这些变量一般包含与产品密切相关的用户态度、观点、行为。但是,聚类分析过程对用于聚类的变量还有一定的要求:
- 这些变量在不同研究对象上的值具有明显差异;
- 这些变量之间不能存在高度相关。
因为,首先,用于聚类的变量数目不是越多越好,没有明显差异的变量对聚类没有起到实质意义,而且可能使结果产生偏差;其次,高度相关的变量相当于给这些变量进行了加权,等于放大了某方面因素对用户分类的作用。
识别合适的聚类变量的方法:
- 对变量做聚类分析,从聚得的各类中挑选出一个有代表性的变量;
- 做主成份分析或因子分析,产生新的变量作为聚类变量。
|| 聚类分析
相对于聚类前的准备工作,真正的执行过程显得异常简单。数据准备好后,丢到统计软件(通常是spss)里面跑一下,结果就出来了。
这里面遇到的一个问题是,把用户分成多少类合适?通常,可以结合几个标准综合判断:
- 看拐点(层次聚类会出来聚合系数图,如右图,一般选择拐点附近的几个类别)
- 凭经验或产品特性判断(不同产品的用户差异性也不同)
- 在逻辑上能够清楚地解释
|| 找出各类用户的重要特征
确定一种分类方案之后,接下来,我们需要返回观察各类别用户在各个变量上的表现。根据差异检验的结果,我们以颜色区分出不同类用户在这项指标上的水平高低。如下图,红色代表“远远高于平均水平”,黄色代表“平均水平”,蓝色代表“远远低于平均水平”。其他变量以此类推。最后,我们会发现不同类别用户有别于其他类别用户的重要特征。
|| 聚类解释&命名
在理解和解释用户分类时,最好可以结合更多的数据,例如,人口统计学数据、功能偏好数据等等(如下图)……最后,选取每一类别最明显的几个特征为其命名,就大功告成啦!


||结果应用(略)
练习题目:对酒相关的指标进行聚类分析
几点说明:
聚类分析是无监督的过程,所以需要多次运行并观察分类的结果。练习中只运行一个结果做演示。
在评估不同的k的表现时,实际上应该固定k,多次运行聚类分析,并计算平均的组间方差或者Silhouette Coefficient,但是练习中只用固定的随机数运行了一个结果做演示,所以也不一定出来非常合理的结果。
实际工作中做聚类分析之前都会进行变量的选择,可以是降维(因子分析),也可以是直接舍弃相关性比较高的变量(相关或者变量聚类), 本练习中只是简单用相关进行了变量选择,比较粗糙,只是告诉大家有这么一个过程,具体工作中,这一步非常重要的,而且需要跟业务人员一起讨论确定。
开动:
library(ggplot2) #作散点图
##数据连接 http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/
#读取数据 白酒和红酒的一些指标
red <- read.csv(“C:\\r\\winequality-red.csv”,sep = “;”)
white <- read.csv(“C:\\r\\winequality-white.csv”,sep = “;”)
red$type <- ‘red’
white$type <- ‘white’
head(red)
head(white)
td <- rbind(red,white)
corr <- cor(td[,1:12]) #用相关系数矩阵做变量的选择
corr
#相关系数矩阵是很多数字,想更好的观察结果,可以尝试可视化技术。
#参考 相关矩阵的可视化及其新方法探究 http://cos.name/2009/03/correlation-matrix-visualization/
circle.cor=function(cor,axes=FALSE, xlab=”,ylab=”, asp=1,title=”Taiyun’s cor-matrix circles”,…){
n=nrow(cor)
cor=t(cor[n:1,]) ##先上下倒转,再转置
par(mar = c(0, 0, 2, 0), bg = “white”)
plot(c(0,n+0.8),c(0,n+0.8),axes=axes, xlab=xlab, ylab=ylab, asp=1, type=’n’)
segments(rep(0.5,n+1),0.5+0:n, rep(n+0.5,n+1),0.5+0:n,col=’gray’)
segments(0.5+0:n, rep(0.5,n+1), 0.5+0:n, rep(n+0.5,n),col=’gray’)
for(i in 1:n){
for(j in 1:n){
c=cor[i, j]
bg=switch(as.integer(c>0)+1,’white’,’black’)
symbols(i,j,circles=sqrt(abs(c))/2, add=TRUE, inches=F, bg=bg)
}
}
text(rep(0,n),1:n,n:1,col=’red’)
text(1:n,rep(n+1),1:n,col=’red’)
title(title)
}
circle.cor(corr
,title=’Cor-matrix’
)

#然而这图看起来有点费劲呀,没有变量的名字,对不上号。
#Excel中有个不错的功能,就是条件格式,可以根据数值的大小着不同的色,很容易有所发现。
#其实类似热力图,所以下面用热力图来看下结果。
#参考 R应用:制作3D热力图
cor <- as.data.frame(corr)
library(d3heatmap)
d3heatmap(cor, scale = “column”, colors = “Spectral”)
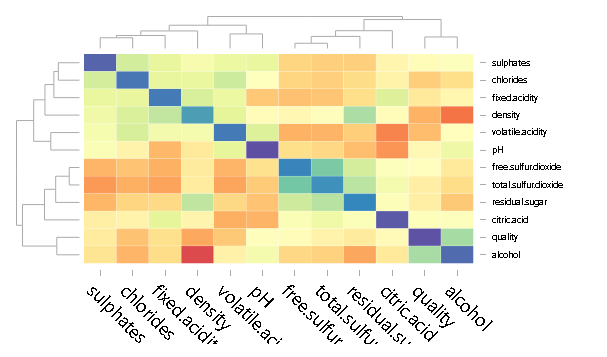
在R中还可以通过鼠标悬停的方式看到每个数字的具体大小。
##删除一些与其他多个变量相关度都比较高的变量,在这里删掉了residual sugar ,density 和 total sulfur dioxide。
##至于alcohol和quality,查了一下相关的资料如下:
##红酒:在一定程度上有关系。酒精度的高低决定与糖度的高低,也就是说在一定程度上能够反映成熟度的好坏。因此在某一个地区,尤其是旧世界,如果酒精度相对比较高,说明该酒的成熟度比较好,质量很有可能比较高。但是对于新世界,尤其是相对比较炎热的产地,就不一定了,过高的酒精度也可能是糖度积累过快,芳香物质积累不足,导致酒质粗糙,不平衡。
##白酒:酒的度数越高,口感越好;酒的度数越低,技术含量越高。
##从上面的描述可以判断,酒精度和质地还是有很强的关系的,但也不是绝对的,比如低度的白酒或者新世界的红酒.所以后面的分析中同时引入了两个酒精度和质地两个变量;
#抽样建模 (实际工作并不一定要抽样)
library(“sampling”)
table(td$type)
s <- strata(td, stratanames=”type”,size=c(1000,1000), method=”srswor”) #分层抽样
train <- getdata(td,s) #训练数据
test <- td[-train$ID_unit,]#测试数据 (本例中没有用到,用EM算法做预测的时候可以对新样本进行类别的预测)
#删掉不分析的变量
train <- train[,c(“fixed.acidity”,”volatile.acidity”,”citric.acid”,”chlorides”,”free.sulfur.dioxide”,”pH”,”sulphates”,”alcohol”,”quality”,”type”)]
test <- test[,c(“fixed.acidity”,”volatile.acidity”,”citric.acid”,”chlorides”,”free.sulfur.dioxide”,”pH”,”sulphates”,”alcohol”,”quality”,”type”)]
set.seed(123) # 设置随机值,为了得到一致结果(前提是训练样本不变,因为在分层抽样阶段,每次抽样的结果都是不一样的)。
library(fpc)#动态聚类
kmeans <- kmeans(na.omit(subset(train, select = -type)), 2)
#查看聚类分析的结果
kmeans$centers
kmeans$withinss
kmeans$totss
kmeans$tot.withinss
kmeans$betweenss
kmeans$betweenss/kmeans$totss
plotcluster(na.omit(subset(train, select = -type)), kmeans$cluster) # 生成聚类图
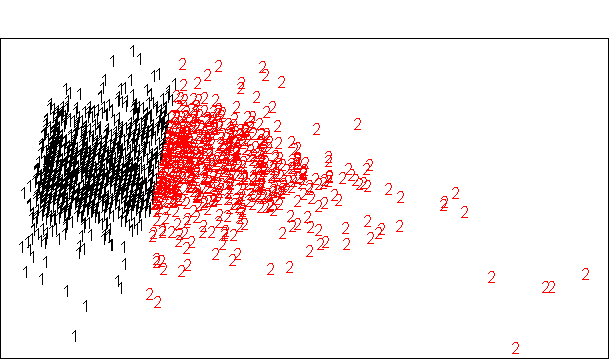
上面这个图好像分的很清晰,实际上图中的1,2是预测的结果,并不是真实的酒的分类。下面用酒的种类来着色。
plotcluster(na.omit(subset(train, select = -type)), kmeans$cluster,col=train$type) # 生成聚类图
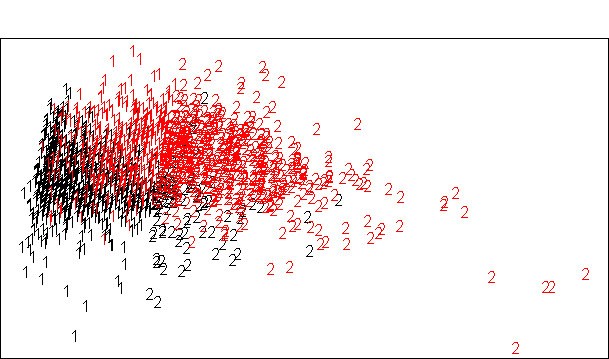
从图中看,效果并不是非常好,中间有很多点混在一起。
table(kmeans$cluster, train$type)
#red white
#1 894 415
#2 106 585
从上面的矩阵中可以看到,效果并不是非常好。
聚类分析完成后需要做profiling(实际工作中会从多个维度去观察不同分类之间的不同,这样才可以对不同的类的特征有更好的把握和利用,本练习中只看下不同分类在多个指标之间的差异):
d3heatmap(kmeans$centers, scale = “column”, colors = “Spectral”)
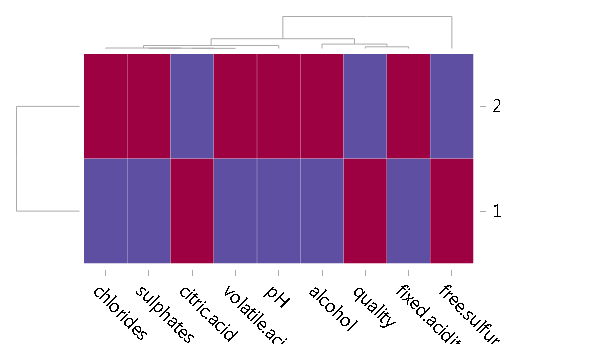
一般情况下,聚类分析结束后,并对每类进行了合理的描述,就可以结合业务需求对结果进行落地应用了。
疑问1:如何选K
虽然聚类分析是无监督的,但是还是有些指标能够在K值的选择上给我们一些参考。
下面我们一起看下理论上怎么选择较优的K:
组间方差:
numofc <- c()
bssp <- c()
for (i in (2:15)){
kmeans <- kmeans(na.omit(subset(train, select = -type)), i)
numofc[i-1] <- i
bssp[i-1] <- kmeans$betweenss/kmeans$totss
}
result <- data.frame(numofc[],bssp[])
qplot(numofc, bssp, data = result,geom = c(“point”,”smooth”))
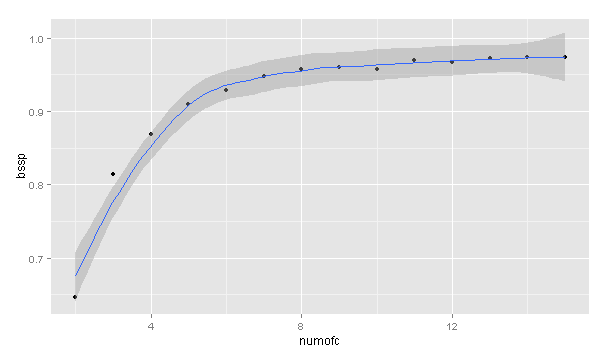
直观上看,可能5-6类就已经不错了。8类之后就非常平稳了。
下面观察下Silhouette Coefficient:
#通过Silhouette Coefficient评估较优K值
library(cluster)
numofc <- c()
Silhouette <- c()
for (i in (2:15)){
kmeans <- pam(na.omit(subset(train, select = -type)), i);
numofc[i-1] <- i
Silhouette[i-1] <- kmeans$silinfo$avg.width;
}
result <- data.frame(numofc[],Silhouette[])
qplot(numofc, Silhouette, data = result,geom = c(“point”,”smooth”))
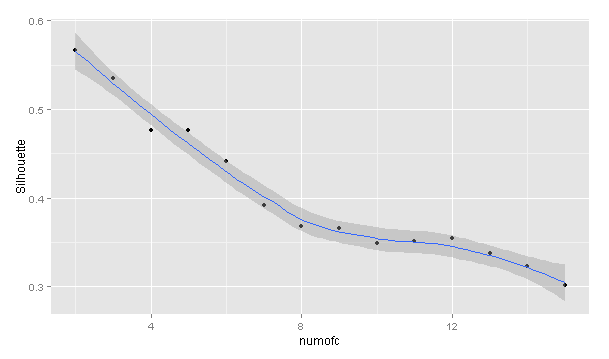
从上图并没有看到非常明显的变化点。8类之前变化都比较明显。所以在尝试不同的k时,可以限制在8类之内。
疑问2:是否需要标准化
大家自己对比下标准化前后的结果,应该就有自己的判断了。
train[,1:9] <- scale(train[,1:9])
test[,1:9] <- scale(test[,1:9])
kmeans <- kmeans(na.omit(subset(train, select = -type)), 2)
plotcluster(na.omit(subset(train, select = -type)), kmeans$cluster,col=train$type) # 生成聚类图
table(kmeans$cluster, train$type)
#red white
#1 286 952
#2 714 48
比标准化前貌似好些,当然这个结果并不是绝对的。所以实际工作中要多尝试。
疑问3:是不是所有类型的数据都可以用kmeans?
实际上kmeans对以下数据就是无效的:
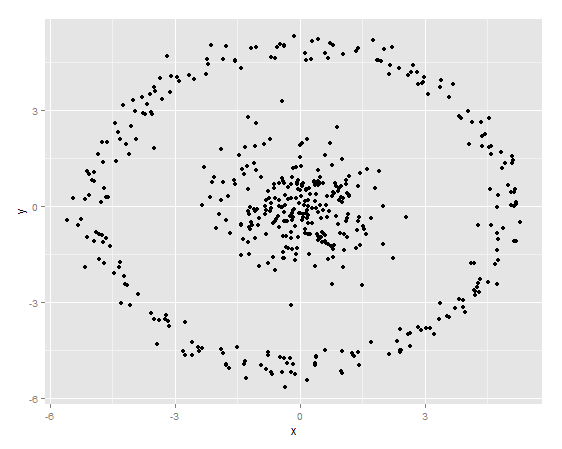
kmeans会得到如下的结果:

但是利用谱系聚类或者dbscan就可以比较合理的区分:

另外说明下EM算法也是可以做聚类的,并能对新数据进行预测,之前测试过,在数据比较随机,也就是代表性很强的情况下,分类的结果比kmeans好。好的定义是跟原始的分类比较匹配。
最优K选择部分参考:使用R评估kmeans聚类的最优K http://www.cnblogs.com/bourneli/archive/2012/11/08/2761120.html
疑问3参考大数据分析之——k-means聚类中的坑 http://blog.sciencenet.cn/blog-556556-860647.html
李双 于 2015年12月17日,转载请注明作者和链接。
注:本站有很多聚类分析相关的文章,大家可以多学习下。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/r%e8%81%9a%e7%b1%bb%e5%88%86%e6%9e%90%e7%bb%83%e4%b9%a0/
注意:本文归作者所有,未经作者允许,不得转载

