1. 用来干啥
根据搜索关键词,读头条搜索,获取百度下拉结果,读取搜狗下拉,获取百度知道搜索,获取新浪爱问,获取搜狗问问的答案聚合到一个html页面中,可以用了生成伪原创文章,做聚合检索网站等等,想咋用咋用。
2. 破解后脚本
#!usr/bin/env python
# -*- coding: utf-8 -*-
#!文件类型: python
#!创建时间: 2021-11-10 17:13
#!作者: SongBin
#!来源网站: https://www.daxueyiwu.com
#!文件名称: jhsearch.py
#!简介:聚合问答
# uncompyle6 version 3.8.0
# Python bytecode 3.7.0 (3394)
# Decompiled from: Python 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]
# Embedded file name: 20210718问答聚合加图片\__init__.py
# Compiled at: 1995-09-28 00:18:56
# Size of source mod 2**32: 257 bytes
import requests, time, os, re, random
from lxml import etree
from urllib.parse import quote
import threading, json
from queue import Queue
import configparser, base64
from urllib import request
config = configparser.RawConfigParser()
config.read('peizhi.ini')
ZHANGHAO = config.get('KUANDAI', 'ZHANGHAO')
MIMA = config.get('KUANDAI', 'MIMA')
IP = int(config.get('KUANDAI', 'IP'))
KD_QUEUE = Queue(1000000)
web_ck = config.get('KUANDAI', 'web_ck')
with open('替换词库.txt', 'r', encoding='utf8') as (f):
tihuan_list = f.read().split('\n')
def connect():
cmd_str = 'rasdial %s %s %s' % ('宽带连接', ZHANGHAO, MIMA)
os.system(cmd_str)
print('拨号')
time.sleep(2)
def disconnect():
cmd_str = 'rasdial 宽带连接 /disconnect'
os.system(cmd_str)
print('断开链接')
time.sleep(2)
def get_connect():
header_baidu = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
try:
code = requests.get('http://apps.game.qq.com/comm-htdocs/ip/get_ip.php', headers=header_baidu, timeout=5).status_code
if code != 200:
connect()
else:
disconnect()
time.sleep(2)
connect()
except:
disconnect()
time.sleep(2)
connect()
def get_toutiao_urls(wd):
url = 'https://so.toutiao.com/search?keyword=' + wd + '&pd=question&source=search_subtab_switch&dvpf=pc&aid=4916&page_num=0'
headers = {'Cache-Control':'no-cache',
'Connection':'keep-alive',
'Cookie':web_ck,
'Host':'so.toutiao.com',
'Pragma':'no-cache',
'Referer':'https://so.toutiao.com/search?keyword=seo&pd=question&source=search_subtab_switch&dvpf=pc&aid=4916&page_num=0',
'sec-ch-ua-mobile':'?0',
'Sec-Fetch-Dest':'document',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-Site':'same-origin',
'Sec-Fetch-User':'?1',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
res = requests.get(url=url, headers=headers)
res.encoding = 'utf8'
title_list = re.findall('"title":"(.*?)",', res.text)
title_list = [i for i in title_list if '\\' not in i]
url_list = re.findall('"url":"(.*?)","', res.text)
url_list = [i for i in url_list if 'wukong' in i]
return ([i.replace('http:', 'https:') for i in url_list], title_list)
def get_wukong_content(url):
headers = {'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,zh-TW;q=0.8,en-US;q=0.7,en;q=0.6',
'cache-control':'no-cache',
'pragma':'no-cache',
'sec-ch-ua-mobile':'?0',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'none',
'sec-fetch-user':'?1',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
res = requests.get(url=url, headers=headers)
if res.status_code == 200:
res.encoding = 'utf8'
wenzhang_list = json.loads(re.findall('INITIAL_STATE__=([\\s\\S]*?)</script><script>', res.text)[0])['qData']['data']['ans_list']
wenzhang = [i['content'] for i in wenzhang_list]
return wenzhang
return
except Exception as e:
try:
print(e)
return
finally:
e = None
del e
def wukong(wd):
res = ''
uu, tt = get_toutiao_urls(wd)
title_two = random.sample(tt, 2)
url = random.choice(uu)
contents_list = get_wukong_content(url)
contents = random.sample(contents_list, 2)
for index, i in enumerate(contents):
i = i.replace('</p>', '\n')
i = re.sub('<.*?>', '', i)
if len(i) >= 4:
res = i.startswith('{') or res + '<h2>' + title_two[index] + '</h2>' + '\n' + i + '\n'
return res
def get_xiala_bd(wd):
try:
url = 'https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=%s&json=1' % wd
text = requests.get(url).text.replace('window.baidu.sug(', '').replace(');', '')
text_json = json.loads(text)
return wd + '(%s)' % random.choice(text_json['s'])
except:
try:
res = requests.get(url=f"http://www.baidu.com/s?wd={wd}&rsv_spt=1&rsv_iqid=0xcab0d69f000cf3cf&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_dl=ib&rsv_enter=1&rsv_sug3=31&rsv_sug1=15&rsv_sug7=100")
list_A = re.findall('c-font-medium new-inc-rs-item" href="/[\\s\\S]*?">(.*?)</a>', res.text)
return wd + '(%s)' % random.choice(list_A)
except Exception as e:
try:
pass
finally:
e = None
del e
return wd
def get_xiala_sogou(wd):
try:
url = 'https://www.sogou.com/suggnew/ajajjson?key=%s&type=web&ori=yes&pr=web&abtestid=0&ipn=&t=1584098135513&suguuid=d74c8137-d92b-4941-a64b-00e0fcac9a0b&ip=180.110.15.100&iploc=3201&suid=43DD6EB44B238B0A5CE7ECB4000BC889&yyid=null&pid=sogou&policyno=null&mfp=null&hs=https&mp=1&prereq_a=dhahdhhad.com&sugsuv=005FC078B46EDD435CFDF9C25D63C464&sugtime=1584098144455' % wd
res = requests.get(url)
res = res.text.replace('window.sogou.sug(', '')
res = re.findall(',\\[(.*?)\\]', res.replace(')', ''))[0].split('","')
if len(res) == 0:
return wd
for x in res:
if x != '':
return wd + '(%s)' % random.choice(res).replace('"', '').replace('()', '')
return wd
except:
return wd
def get_zhidao_urls(wd):
url = f"http://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&&word={wd}"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
try:
res = requests.get(url=url, headers=headers, timeout=10)
res.encoding = res.apparent_encoding
if '安全验证' in res.text:
print('zhidao出验证码了~~~~')
return ''
questions_list = re.findall('zhidao.baidu.com/question/(.*?).html', res.text)
questions_list = [f"http://zhidao.baidu.com/question/{i}.html" for i in questions_list]
random.shuffle(questions_list)
return questions_list[1:3]
except:
return []
def get_zhidao_answer(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
req = request.Request(url, headers=headers)
request2 = request.urlopen(req)
content = request2.read().decode('gbk')
request2.close()
html = etree.HTML(content)
title = re.findall('<title>(.*?)_百度知道</title>', content)[0]
contents = html.xpath(".//div[@class='bd answer']//text()")
cc = contents
contents = [re.sub('[\\s]+', '', i) for i in contents]
contents = '\n'.join([i for i in contents if len(i) >= 5])
if len(cc) <= 10:
bst_list = html.xpath("//div[@class='line content']/div[@accuse='aContent']//text()")
cc_li = []
for i in bst_list:
if i != '' and i != '\n' and len(i) >= 8:
cc_li.append(i.strip())
contents = ''.join(cc_li)
return f"<h2>{title}</h2>\n{contents}"
except:
pass
return ''
def zhidao(wd):
res = ''
uu = get_zhidao_urls(wd)
random.shuffle(uu)
for x in uu:
c = get_zhidao_answer(x)
res = res + c.strip() + '\n'
res = res.replace('你对这个回答的评价是?', '')
return res
def get_sina_urls(wd):
headers = {'pragma':'no-cache',
'referer':f"https://iask.sina.com.cn/search?searchWord={quote(wd)}&record=1",
'sec-ch-ua-mobile':'?0',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'?1',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
url = f"https://iask.sina.com.cn/search?searchWord={wd}&page=1"
for i in range(4):
res = requests.get(url=url, headers=headers, timeout=10)
res.encoding = res.apparent_encoding
if res.status_code == 200:
break
time.sleep(2)
if res.status_code == 403:
return ''
url_list = ['https://iask.sina.com.cn' + i for i in re.findall('<p class="title-text"><a href="(.*?)"', res.text)]
return url_list
def get_sina_answer(url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
try:
res = requests.get(url=url, headers=headers, timeout=10)
res.encoding = 'utf8'
html = etree.HTML(res.text)
title = re.findall('<title>(.*?) 爱问知识人</title>', res.text)[0]
pre_list = html.xpath("//pre[@class='list-text']/text()")
content = sorted(pre_list, key=(lambda i: len(i)), reverse=False)[(-1)]
content = f"<h2>{title}</h2>\n{content}"
except:
content = ''
return content
def sina(wd):
res = ''
t = 0
uu = get_sina_urls(wd)
random.shuffle(uu)
for x in uu:
c = get_sina_answer(x)
if len(c) >= 10:
res = res + c.strip() + '\n'
t += 1
if t >= 2:
break
res = res.replace('你对这个回答的评价是?', '')
return res
def get_sogou_urls(wd):
headers = {'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Mobile Safari/537.36'}
url = f"https://m.sogou.com/web/searchList.jsp?keyword={wd}&insite=wenwen.sogou.com&pid=sogou-waps-fd2ae8ec902471d8&rcer=uNz_alvVqvzeAE_5"
try:
res = requests.get(url=url, headers=headers)
res.encoding = res.apparent_encoding
id_list = re.findall('&url=http%3A%2F%2Fwenwen.sogou.com%2Fz%2F(.*?).htm&vrid', res.text)
url_list = [f"https://wenwen.sogou.com/z/{i}.htm" for i in id_list][1:]
except:
url_list = []
return url_list
def get_sogou_answer(url):
headers = {'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Mobile Safari/537.36'}
try:
res = requests.get(url=url, headers=headers, timeout=10)
res.encoding = 'utf8'
html = etree.HTML(res.text)
title = re.findall('<title>(.*?)</title>', res.text)[0]
pre_list = html.xpath("//h3[@class='ask-fresh-con answerContent']//text()")
pre_list2 = html.xpath("//h3[@class='ask-fresh-con']//text()")
pre_list.extend(pre_list2)
content = ''.join(pre_list)
content = content.replace('\u3000', '')
content = f"<h2>{title}</h2>\n{content}"
except:
content = ''
return content
def sogou(wd):
res = ''
t = 0
uu = get_sogou_urls(wd)
random.shuffle(uu)
for x in uu:
c = get_sogou_answer(x)
if len(c) >= 10:
res = res + c.strip() + '\n'
t += 1
if t >= 2:
break
res = res.replace('你对这个回答的评价是?', '')
return res
def result_tihuan(text):
for x in tihuan_list:
text = text.replace(x, '')
text = re.sub('[a-zA-z]+://[a-zA-Z0-9\\.\\-\\/_]+', '', text)
result = '\n'.join(['<p>' + i + '</p>' for i in text.split('\n') if len(i) >= 5])
result = result.replace('<p><h2>', '<h2>')
result = result.replace('</h2></p>', '</h2>')
return result
with open('关键词.txt', 'r', encoding='utf8') as (f):
kd_list = f.read().split('\n')
def get_baidu_pic(wd):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=7941037868480343284&ipn=rj&ct=201326592&is=&fp=result&queryWord=' + wd + '&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=' + wd + '&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&nojc=&pn=30&rn=30&gsm=1e&1626606839586='
res = requests.get(url=url, headers=headers)
pic_list = []
for i in res.json()['data']:
try:
pic_list.append(f"<img src='{i['thumbURL']}' alt='{wd}'>")
except:
pass
return pic_list
def get_content_main(wd):
wd = re.sub('[\\s]+', '', wd)
try:
tt = get_xiala_bd(wd)
if tt == wd:
tt = get_xiala_sogou(wd)
except:
tt = wd
tt = re.sub('[?.!!]', '', tt)
print(f"[INFO:当前生成内容:{tt}]")
rr_jieguo = ''
temp = zhidao(wd)
rr_jieguo = rr_jieguo + temp + '\n'
temp = sina(wd)
rr_jieguo = rr_jieguo + temp + '\n'
temp = sogou(wd)
rr_jieguo = rr_jieguo + temp + '\n'
try:
temp = wukong(wd)
rr_jieguo = rr_jieguo + temp + '\n'
except Exception as e:
try:
pass
finally:
e = None
del e
result_cc = result_tihuan(rr_jieguo)
try:
pic_list = get_baidu_pic(wd)
except:
pic_list = []
try:
result_cc_h2 = result_cc.split('<h2>')
result_con = ''
for index, mwy in enumerate(result_cc_h2):
if len(mwy) >= 5:
if index % 2 == 0:
result_con = result_con + '<p>' + random.choice(pic_list) + '</p>' + '\n' + '<h2>' + mwy
else:
result_con = result_con + '\n' + '<h2>' + mwy
except:
result_con = result_cc
result_con_ll = result_con.split('\n')
result_con_ll = [re.sub('\\s{3,}', '', i) for i in result_con_ll]
result_con_ll = [i for i in result_con_ll if len(i) > 3]
result_con = '\n'.join(result_con_ll)
with open((os.path.join('d:/文章', tt + '.txt')), 'w', encoding='utf8') as (f):
f.write(result_con)
print(f"[SUCCESS:当前内容:{tt}]--------生成成功!")
def main():
for x in kd_list:
KD_QUEUE.put(x)
ci = 40
xiancheng = int(input('选择线程:'))
real_huan_ip_ci = int(ci / xiancheng)
real = 0
while True:
if KD_QUEUE.empty():
break
if IP != 0:
if real % real_huan_ip_ci == 0:
print('该换IP了~~~~~')
get_connect()
thread_list = []
for i in range(xiancheng):
if KD_QUEUE.empty():
break
wd = KD_QUEUE.get()
t1 = threading.Thread(target=get_content_main, args=(wd,))
thread_list.append(t1)
for t in thread_list:
t.setDaemon(True)
t.start()
for t in thread_list:
t.join()
real += 1
print('任务完成!')
main()3. 4个配置文件
关键词.txt
替换词库.txt
peizhi.ini
4. 使用方法
设置 peizhi.ini
web_ck 代表头条cookie
关键词填入目标词
替换词库填入近义词词库
python jhsearch.py
直接运行就可以了。
5. 运行结果
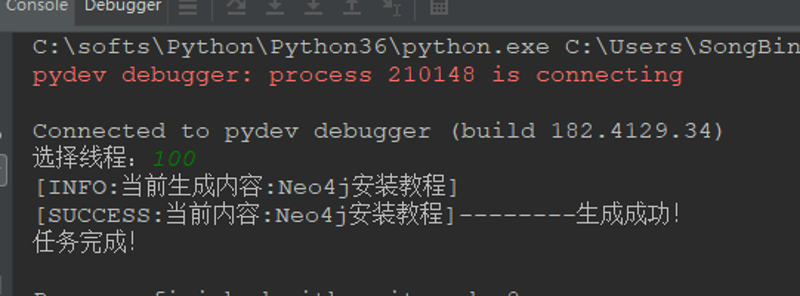
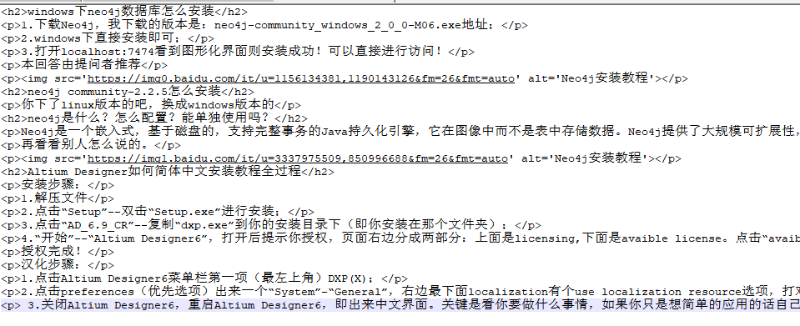
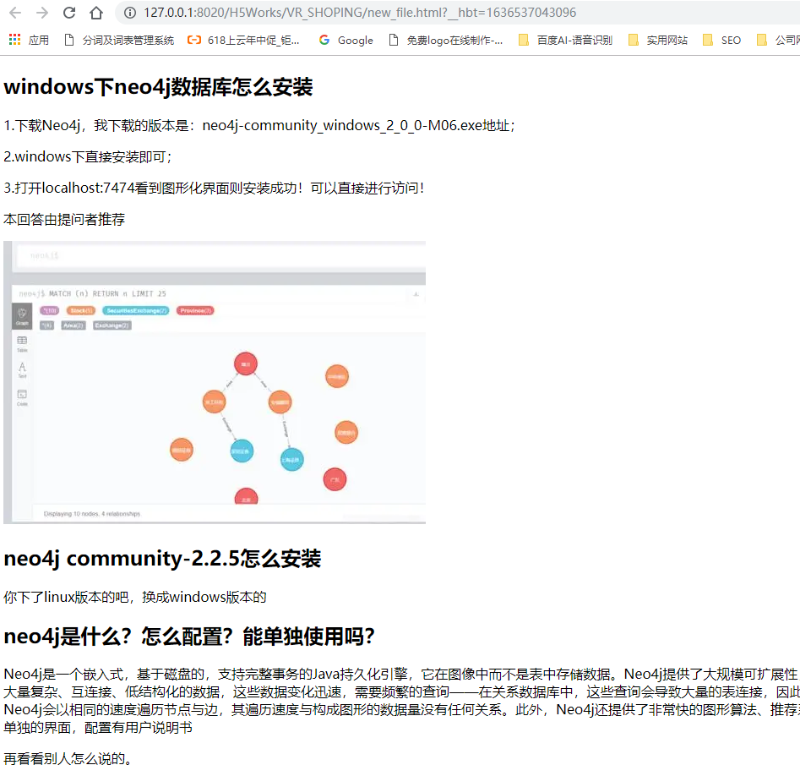
6. 附加
1)打包后的exe可运行文件
2)脚本文件
3)配置文件
可在文章后附加内下载。
注意:本文归作者所有,未经作者允许,不得转载

