联合分析(conjoint analysis)是市场研究常用分析方法,70年代以来在实际应用范围很广,具体做法可见参考文献中Aaker等合著的《营销研究》,国内有中文翻译版,这里主要介绍使用R和SAS来实现基本的联合分析方法。
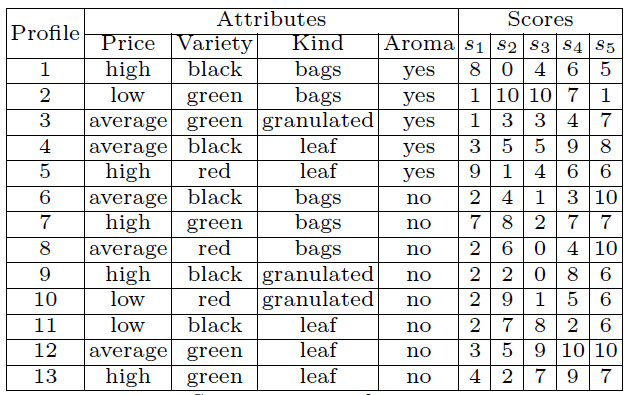
R中能够实现联合分析的包不止一个,包括homals, psychoR , bayesm, faisalconjoint, conjoint等,这里使用conjoint包,主要是参考文档比较好,有案例,有解释,便于学习。包中自带了数据,这里使用名字为tea的数据来演示联合分析的具体实现方法,tea数据是关于茶市场吸引力的调查结果,共有price variety kind aroma等四个因素,price variety kind各有3个水平,aroma有2个水平,全因素排列的话应该有3*3*3*2=54种组合方式,实际真实做调查时无法将54种都一一展现出来,用实验设计的方法,挑选13种组合来进行调查,评分如下,评分越高代表越有吸引力:
首先加载conjoint包,装入tea数据:
library(conjoint),
data(tea)
tea数据中包括4个数据集,tprof是13种组合的样例,得到的结果为tpref和tprefm,这个两个数据内容相同,排列不同,都是这13种组合的调查结果,对应了不同的分数,数值越大代表越好,tlevn各个因素不同水平的名称,用于输出结果比较容易理解。下面通过conjoint函数来进行分析:
Conjoint(y=tprefm[1,], x=tprof, z=tlevn)
这里看到y代表分数,只取tperfm的第一行,有13个值,对应于s1中13种组合的评分情况,x为每个组合的因素属性,z代表每个属性水平的名称,结果为:
")
")
输出结果中,intercept代表模型常系数,接下来的三个low medium high对应的是price的三个水平,其中high是最高的,说明价格高的比低的更有吸引力,接下来是茶的种类,其中红茶最受欢迎,绿茶最不受欢迎,以此类推,从中可以推断出那种组合是最受欢迎的,就是每个因素都取系数最的水平的组合。
接下来是这几个因素的重要性对比,数值的含义是每个因素在顾客评价考虑因素的占比,综合为100%,price为43%是最重要的,aroma是最不重要的,占13%,通过这个结果,我们可以了解各个因素中,那些是在产品设计中最应该注意的。
接下来使用SAS来进行相同的分析,先把这个数据存入mysql数据库,以便供SAS调用,具体SAS和R连接mysql的方法参见前面文章:
mydb = odbcConnect(“marketing”, uid=”root”, pwd=”aaa”)
y=t(tprefm[1,])
names(y)=”y”
x=tprof
tea_data=cbind(y,x)
sqlSave(mydb, tea_data, append = FALSE, rownames = FALSE, colnames = FALSE)#回写mysql数据库
odbcClose(mydb)
在SAS系统中,首先建立一个逻辑库,连到刚才R进行输出的mysql库中,可以使用transreg过程步来进行联合分析,其中y代表不同茶组合的分数,aroma
libname mkt odbc user=root password=aaa
proc transreg data=mkt.tea_data maxiter=50 utilities short;
run;
")
")
从结果可以看到和R相同的输出结果,不过这里的系数和R中正好相反,系数越小代表越好,说明排位越靠前,从重要性来看,四个变量占的百分比和R中结果是相同。
对于传统的联合分析可以用哑元变量的线性回归来实现,下面在SAS中重新来尝试做一下,首先是生成各个因素的哑元变量:
data tea_data;
set mkt.tea_data;
y=10-y;
price_1=(price=1);
price_2=(price=2);
price_3=(price=3);
variety_1=(variety=1);
variety_2=(variety=2);
variety_3=(variety=3);
kind_1=(kind=1);
kind_2=(kind=2);
kind_3=(kind=3);
aroma_1=(aroma=1);
aroma_2=(aroma=2);
run;
这里对y进行了变换,代表y值越小代表评价越好,对于各个因素的水平使用0-1哑元变量来代替,回归时用哑元变量,特别注意的是,一个变量生成n个哑元变量,在回归时只使用n-1个变量,因为这个n个变量是完全线性相关的,不能同时进入模型。
进行回归后,对回归系数进行一下变换,就能得到联合分析的结果了,带有ca后缀的为联合分析中的系数,这里的主要想法让在一个变量的多个系数和等于0,同时他们的距离又不变,进行简单的数学变换,就可以得到最终的结果。
")
")
以上是我们用两种方法进行比较传统的联合分析,采用的是最基本的算法,联合分析在后来的应用中又发展出了不同的算法,大家可以进一步深入研究,在实际工作中更好的使用联合分析方法。
参考文献:
(1) Conjoint analysis method and its implementation in conjoint R package, W Pociecha J., Decker R.
(2) SAS Technical Report R-l 09 Conjoint Analysis Examples
(3) Marketing Research, David A. Aaker, V. Kumar, George S. Day, Robert Leone
本文来自blog.sina.com.cn,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:http://blog.sina.com.cn/s/blog_648ca2350101nm33.html
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

