作者 刘强 来自 消费者研究(微信公众号)
我们将用一个系列介绍MaxDiff这种新的测量和建模技术,主要聚焦在它可以解决什么样的问题,以及如何解决问题。我们先从两个故事开始。
瑟斯顿的故事

路易斯.列昂.瑟斯顿博士(Louis Leon Thurstone)早在上世纪20年代就已经是心理测量学领域的先驱人物。他通过大量测试和评估,建立了一套关于测度的理论方法,他将其称为“比较性判断准则(Law of Comparative Judgement)”。这套准则通过让人们每次比较多个对象中的两个,而最终可以计算出每个对象的测量分数(定距尺度)。后来的学者根据这种方法的特点将其命名为“成对比较法”。瑟斯顿博士在心理学测量领域,以及因子分析方法上都做出了极大的贡献。
瑟斯顿在上世纪20年代任教于芝加哥大学。彼时芝加哥犯罪频发,黑道大哥艾尔.卡彭呼风唤雨。因此,当时不少芝加哥大学的研究学者开始关注犯罪现象,他们想知道应该如何减少犯罪,犯不同罪行的人应该如何量刑惩处。

瑟斯顿当时最关注的一个问题是如何量化不同罪行的严重程度。事实上,他非常喜欢这个问题,并且一辈子(直到去世)都致力于这项研究。也许瑟斯顿这一生最著名的研究就是试图去量化不同罪行的严重程度,去从定距尺度上了解哪些罪行会比其他一些罪行更为严重。他挑选了19种当时最普遍的犯罪行为,并且希望通过调查来获取人们对这些罪行严重程度的看法。以下是他挑选的19种罪行。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果是您,您会如何测评这些罪行的严重程度呢?
对于大多数人来说,也许首先会想到采用打分评测的方法。那么相应的问题会长成这个样子

瑟斯顿没有采用评分的方法,因为打分的方法得到的结果往往在不同罪行上缺乏足够的差异度(不同罪行的严重程度平均分相差不大),而且很容易受到受试者个体评分尺度使用偏差的影响(有些人倾向于打高分,有些人倾向于打低分;有些人只打6/7分,有些人会愿意使用1-7分中的任何分数)。
或者,你会想到用排序的方法。这样一来应该可以克服打分评价的一些不足了。那么相应的测试问题会是这个样子。

但瑟斯顿也没有选择这种方法。这是因为需要测评的罪行比较多,受试者很难准确地完成排序。事实上,有研究表明,当需要排序的对象超过7个时,受试者就很难做出准确的判断了,何况这里有19种罪行需要排序。另外一个原因是即便受试者可以做出准确的排序,我们也很难量化不同罪行的严重程度。因为我们得到的是有序型数据,而这种数据并不能直接进行加减乘除,如果某个人把杀人罪排在第1严重,而另外一个人把杀人罪排在第5严重,我们如何汇总这两个人在杀人罪上的评价以得一个数量意义上的测量值?
瑟斯顿最终采用的方法是成对比较法。19种罪行如果进行两两比较的话,总过有171(19*(19-1)/2=171)次成对比较。下图是他的成对比较问题的部分展示:

瑟斯顿为此制作了几套不同的卡片集,每套卡片集里有171张卡片,每张卡片上出示两种罪行。每套卡片集里均有171张卡片,但是每套卡片集里卡片出现的顺序是不同的。为此,瑟斯顿还专门用圆环把每个卡片集的卡片串在一起以免搞错次序。当受访者需要完成比较时,他们一边翻动卡片集,一边将自己的比较答案记在答题纸上。这的确挺费时间的,据瑟斯顿记录,平均每个人需要花费近20分钟以完成这171张卡片的成对比较。
尽管需要更长的时间完成更多这样的问题,但受试者并不会觉得乏味和困难。因为直接比较两个对象相比打分(缺乏直接比较)或排序(需要比较的内容过多)更加简单,而且受访者会觉得这是一个有趣的过程,他们的主动参与度更高,而疲劳度更低,因此会容忍更长的访问时间。而且瑟斯顿相信对这种数据的分析会更加有效和准确,能获得更有意义的具有显著差异性的结果。
瑟斯顿把这些成对比较的调查问题交给了266名芝加哥大学的学生去完成。根据这266名受访者的答案,瑟斯顿计算出了每种罪行的严重程度(0-100,定距尺度)。看看当时瑟斯顿计算得到的最终结果。
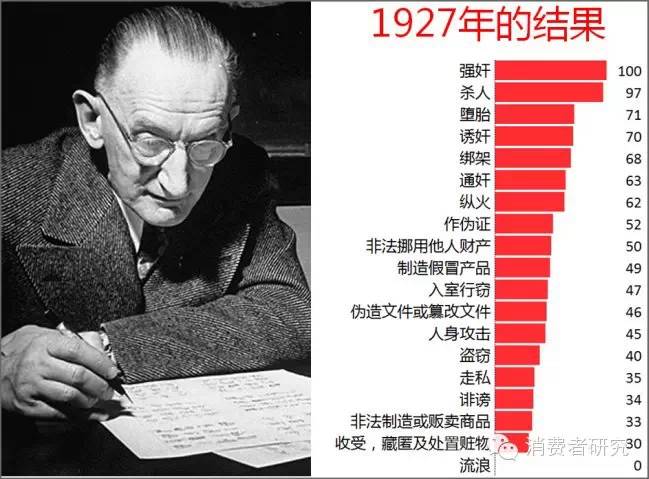
现在我们不仅可以知道罪行严重程度的排序,还能知道某个罪行比其他的罪行严重多少。现在来看看1927年人们对罪行的看法还是挺有趣的,我们也可以想想当前我们对这些罪行的判断是否和80多年前有多大差别呢?
如果需要了解更多关于瑟斯顿关于这项研究的细节,可以参阅http://www.brocku.ca/MeadProject/Thurstone/Thurstone_1927a.html
Facemash的故事

最近20年来,互联网最大的事件无疑是社交网络的盛行。而让社交网络真正盛行起来的人无疑是facebook的创始人马克·扎克伯格。他的传奇故事于2010年被搬上了银幕–《社交网络》。电影《社交网络》的前15分钟记录了这样的场景。2003年,在哈佛大学读二年级的马克·扎克伯格刚从一次失败的约会中回到宿舍,不爽的他从冰箱里拿出啤酒解闷,同时想着需要做点什么。他编写了一个好玩的网站Facemash,可以将任意两个女生的头像照片随机组合在一起(为此他黑进了不少宿舍楼或学院的服务器,下载了大量女生的头像照片),让网页浏览者选择哪一个“更性感”。下图是《社交网络》电影介绍这段往事的一些截屏。




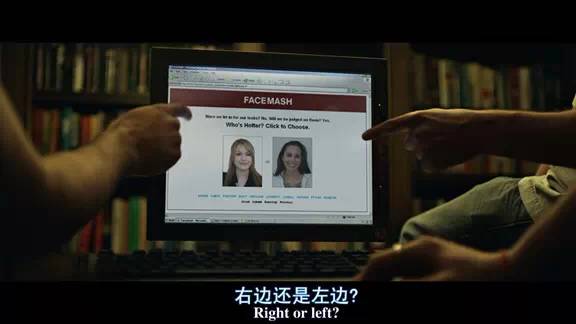

扎克伯格当时还把自己开发这个小程序的想法和做法都实时记录在了自己的博客上。可以看到,他认为用直接评分的方式来评价女孩子的“热辣”程度并不好,而通过成对比较方式得到的排序则更好,显得更“聪明”。关键的是,对于评测者而言,这种成对比较足够简单,好玩。这款小程序在极短的时间内风靡整个校园,facemash的点击率非常之高,甚至一度导致哈佛校园服务器的过载。
多说一句,在获得了成对比较数据后,扎克伯格使用一种叫做Elo rating system的算法实时计算女孩的“热辣度”以进行排序。这种算法是当今对弈水平评估的公认权威规则,已被广泛应于国际象棋、围棋、足球和篮球等体育运动以及游戏中。当然,能帮助扎克伯格解决女孩子热辣度排序问题的算法不止这一种。问题的关键在于,扎克伯格意识到了采用成对比较法是进行评测和获取数据的最佳方式。
对我们的启示
不论是瑟斯顿的关于罪行严重程度的社会看法的研究,还是扎克伯格的facemash网站,都体现出一个共同点,即需要比较的对象非常多。瑟斯顿需要比较19项罪行,而扎克伯格的facemash更是需要比较成百上千的女孩头像。瑟斯顿和扎克伯格不约而同地选择了成对比较这种方式,他们都注意到了评测者的因素,更多的是考虑到如何让参与评测的人能够顺利地,轻松地给出准确的评价。他们都意识打分评测方式在面对多对象评测时的缺点,因此宁愿用更长的时间成对比较方式以换来有趣得多的评测体验以及更准确的结果。
在日常生活中,也往往会遇到多个对象评价的情形,这时我们是否也需要用更有趣的方式帮我们做出准确的决策呢?在市场研究领域,客户也往往需要了解消费者对多个对象(例如多个产品,多种产品属性,多个版本的广告,抑或多种不同的生活态度倾向等)的偏好。传统的打分或排序方式往往对受访者来说是种挑(zhe)战(mo),他们很难做出准确的回答,这导致最终的研究结果经常体现不出对象间明显的差异(尽管可能体现出某种有意义的模糊趋势),客户往往对把这种结果运用于营销和管理满怀疑虑。是否我们也可以借鉴上面瑟斯顿和扎克伯格的思路去解决实际的问题呢?
传统的打分方式的问法到底存在什么问题,而成对比较法是否也有不足之处呢?
打分评测方式的主要问题:
在上一篇瑟斯顿和Facemash的故事里,我们提到了他们都意识到传统的评分方式在评价多个对象时的不足之处。这种不足体现主要体现在三个方面。
先看看通常的打分方式对不同对象评价的例子,通常的问题类似这种样子:

打分方式的第一个不足之处在于,我们会受到受访者使用量表习惯的影响。有些受访者总是倾向于打高分(或打低分)。再如有些人会有意识地使用1-5分中的各种分值,而有些受访者则仅仅使用少数几种分值。尽管这看起来的确揭示了受访者的某些个性,但这种尺度使用上的“个性”对分析人员而言可不是福音。如果是一个涉及到多个地区/国家的研究,我们往往还会发现不同地区或国家的受访者在使用打分尺度上存在着很大的差异。

其次,受访者还会以不同的方式理解量表的含义。有些受访者会将这种量表理解为一种等比的形式,譬如4分的重要性是2分的两倍,有些受访者可能会将这种量表理解为有序的形式,即4分优于2分,但并不认为4分是2分的两倍。这使得这种打分评价答案的数据特性并不适合进行一些统计分析,例如方差分析,回归,聚类,因子分析等。对于受教育程度较低的人群或儿童来说,他们很难理解这种量表的意义。下面这个小漫画很形象的描绘了尺度使用的差异性。

最后,也是最重要的一个问题是,打分方式得到的结果在被测的各个对象上缺乏差异,尤其是当测度的对象较多时。感受一下一个较多属性的重要性测量题目,以及我们经常看到的结果(见下图):
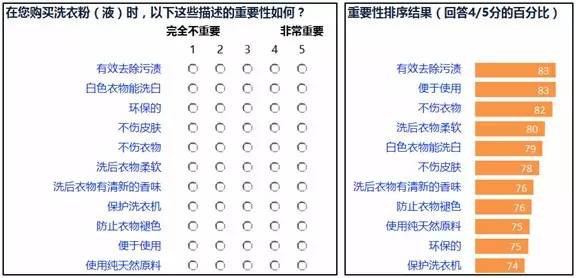
当然,也可以采用排序或者定和分配(Constant Sum)的方法来进行测量。这样做的确可以解决一些上面提到的问题。但是当需要测量的对象很多时,无论是排序或者定和分配仍然会变得很困难,很难想象受访者能在几十个对象中进行正确的排序或定和分配。因此这两种测量方法的使用仍然受到一定的条件限制。
成对比较方法的优缺点:
这个系列第一篇里瑟斯顿和扎克伯格使用的成对比较法可以简单的表述如下。
假设我们有很多个对象,我们可以让其中两个对象PK,看看人们会偏爱哪一个。

每次PK后,我们会再引入另外两个对象进行PK,并且依次进行很多轮的PK。这有点像体育比赛里的循环赛,每两只队伍都要交手一次。
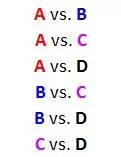
假设有4个对象: A, B, C, D。那么一共有6种可能的成对比较:

(这里假设A vs. B与B vs. A是等价的,如果把这4个对象想象成球队,也就是说A和B的比赛是在中立的场地,因此可以忽略各自的主场优势)。
更一般的,假设有t个对象,那么对应有t(t-1)/2个可能的成对比较。
但是问题又来了,假设需要测量10个对象,那么理论上需要进行45次成对比较。似乎太多了点?是不是我们一定要遍历完成所有可能的成对比较呢?
赫尔伯特.大卫(Herbert Aron David)在上世纪60-70年代在瑟斯顿的工作基础上对多重成对比较方法进行了大量的研究和发展,并提出了成对比较法的环状设计(cyclical design)。他发现,通过环状设计,只需要进行1.5t次成对比较就可以收集足够的信息进行模型估算。下图是一个6个对象的环状设计示意图:
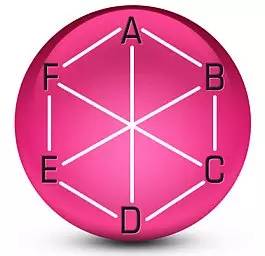
这张示意图表达了9种成对比较:AB, BC, CD, DE, EF, FA, AD, BE, CF。也即只需要进行这9种成对比较,就足够进行一些模型运算以计算每个对象的偏好度了。可以看到,在环状设计里,尽管没有遍历所有的成对比较,但是每两个对象之间都存在直接或间接比较(例如B和F虽然没有直接比较,但是我们可以通过A/C/E这些“桥梁”进行间接比较),我们把这种现象称为具有连接性。通常我们都期望所选取的成对比较具有连接性这个特征,以保证我们获得更准确的对象间比较信息。
但是细心的读者会发现,即便使用环状设计,还是需要完成很多次的成对比较(如下图所示)。
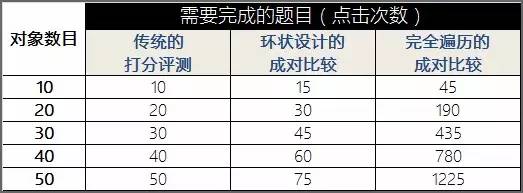
当有20个对象需要评价时,环状设计需要进行30次的成对比较;而当需要比较的对象达到50时,环状设计需要进行75次成对比较。这对受试者来说无疑仍是不小的挑战。那么还有更有效的方法么?
答案是:有的!
Jordan Louviere在上世纪90年代初介绍了一种被称为 “最大差异测量” (也被称作“最好/最差测量”) 的新方法。其做法是让受访者从一组对象中指出能表明最大差异偏好的对象。例如受试者需要在几个对象中同时选出“最好的”和“最差的”。这种方法既保留了成对比较法的优点,又极大程度地改进了成对比较法的效率。
这种方法名为Maximum difference scaling,通常被简称为MaxDiff。
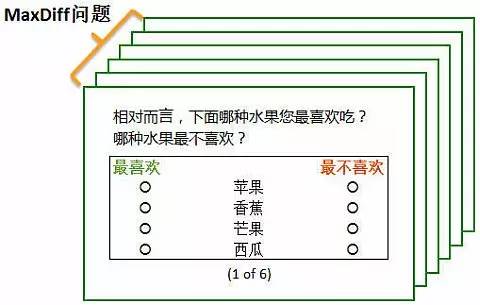
在具体介绍之前,先看看下面这个简单的MaxDiff问题:

在这里,受试者需要指出“最重要”和“最不重要”的因素。那么,为什么需要同时指出“最重要”和“最不重要”的因素呢?
这是因为这么做可以使我们更快速,更高效地获得所需要的成对比较信息。
现在考虑一个一般的情形,假设我们要对四个对象(A/B/C/D)做出比较。如果沿用成对比较的思路,那么总共有6种可能的成对比较,分别是:
如果采用Maxdiff的问法,假设某个受访者认为这4个对象中A是最好的,而D是最差的。我们那么我们可以很容易且快速地得到以下结论:
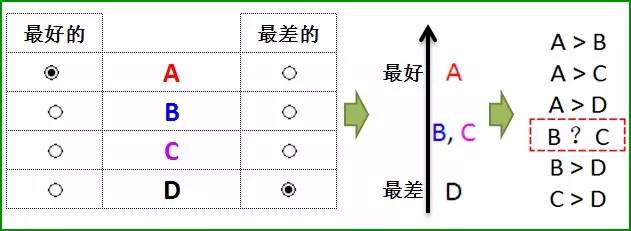
这里,受访者仅仅通过两次“点击”(一次选出最好的,一次选出最差的),我们就能获得所有6对可能的成对比较中的5对比较的结果(仅有B和C的关系未确定),即两次点击获得高达83.3%(=5/6)的成对比较信息量。相比传统的成对比较方式,我们一共要比较6次,每次成对比较仅获得16.6%(=1/6)的全部比较信息量。由此可见,MaxDiff的效率比成对比较高出太多了。在上面的购车考虑要素的例子中,我们通过MaxDiff方法,在一个题目中就可以从所有10对可能的成对比较中获得7对(70%)的比较结果。从这个角度看,Maxdiff极大程度的提升了成对比较法的效率,成对比较法所导致过多比较的缺点得到一个有效的解决方式。
但是有细心的读者又会发现,在上面的MaxDiff问题中,仍有少部分的比较信息是没有获得的(例如B和C的比较信息),难道这部分信息我们就不需要测量了么?
我们当然不会放弃获取这些未确定的比较信息,但是我们通过一个巧妙地方法来解决—多次测量。在MaxDiff中,我们不会仅仅只问一个MaxDiff问题,而是问多个类似的问题,例如在购车因素例子里,我们总共会问12道这样的题目,每次出现的5个属性不尽一致。这样一来,单次MaxDiff问题未能确定的某些对象间的比较信息就可以从其他的MaxDiff题目中获得,而单次测量中已经确定的比较信息会通过多次测量获得更稳健的结论,从而使得我们获得的比较信息量的测量误差更小。
讲到这里,我们不妨综合比较下打分评测,环状成对比较和Maxdiff的效率。
假设有n个对象需要测量,Maxdiff题目每次呈现其中的5个对象。同时,为了实现多次测量以降低测量误差的目的,Maxdiff题目不止一个,而是3n/5个,这样可以保证每个对象在所有的Maxdiff问题中至少出现3次。
我们首先看看成对比较和Maxdiff所需完成的题目数量:
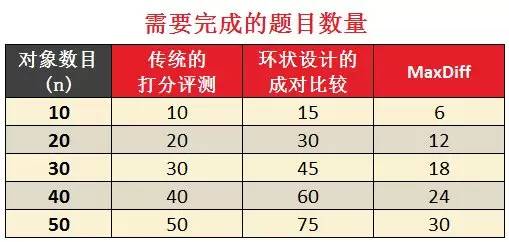
可以很明显的看到,Maxdiff所需的题目数量比环状设计成对比较所需要的题目少很多,甚至少于传统打分评测。
需要注意的是,在回答传统的打分评测以及成对比较的每道题目时,受试者只需要给出一个答案,如果是网络问卷的话,即只需要鼠标点击一下就完成一道题目。而MaxDiff的每道题目上,受访者需要给出两个答案,鼠标需要点击两下。因此,还需要对比下完成相应题目所需要的点击次数。
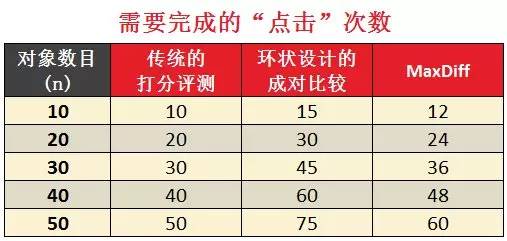
从点击次数上比较,完成Maxdiff题目的点击次数略高于传统的打分评测,但是优于环状设计的成对比较。当然,在样本量较大时,我们无需严格满足Maxdiff中每个对象至少出现3次的要求。这时,无论Maxdiiff的题目数还是点击次数都会低于传统的打分评测。这涉及到一些试验设计和模型运算方面的考量,我们会在后续文章中做进一步的介绍。
最后,我们还可以看看环状设计的成对比较和Maxdiff题目实际可获得的直接成对比较信息量的大小。还是假设有n个对象需要测量,Maxdiff题目每次呈现其中的5个对象,MaxDiff问题数目为3n/5个。不难得知,环状设计的成对比较总共会产生1.5n个成对比较,并且获得1.5n个直接比较的结果。而MaxDiff每个题目获得7个成对比较结果,总共获得7x3n/5=4.2n个直接比较信息。
以上这些比较发现,特别是最后一点,让我们非常惊喜。这意味着平均而言,Maxdiff用更少的题目,更少的回答,获得了接近3倍于环状设计成对比较的信息量。这种结果使我们后续的模型估算建立在更多,更准确的比较信息上,其稳健性和精度都得到了极大的改善。更为重要的是,这种时间和精力的大幅节省使得我们可以将MaxDiff方法推广到更一般的场合,以在某种程度上替代传统的打分的测量方式。
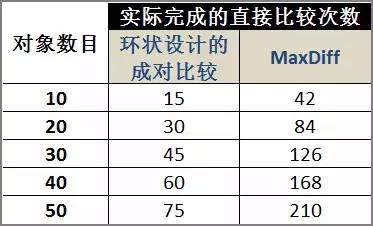
我们来看一个完整的Maxdiff的例子:
假设我们有某个产品(例如洗发水)的8种外观设计,我们这里用X1-X8和外观图片来表述。我们希望通过MaxDiff的方式来进行测量,看看消费者会最喜欢哪几种外观设计。那么我们会设计以下6个MaxDiff问题来让受访者做出回答。
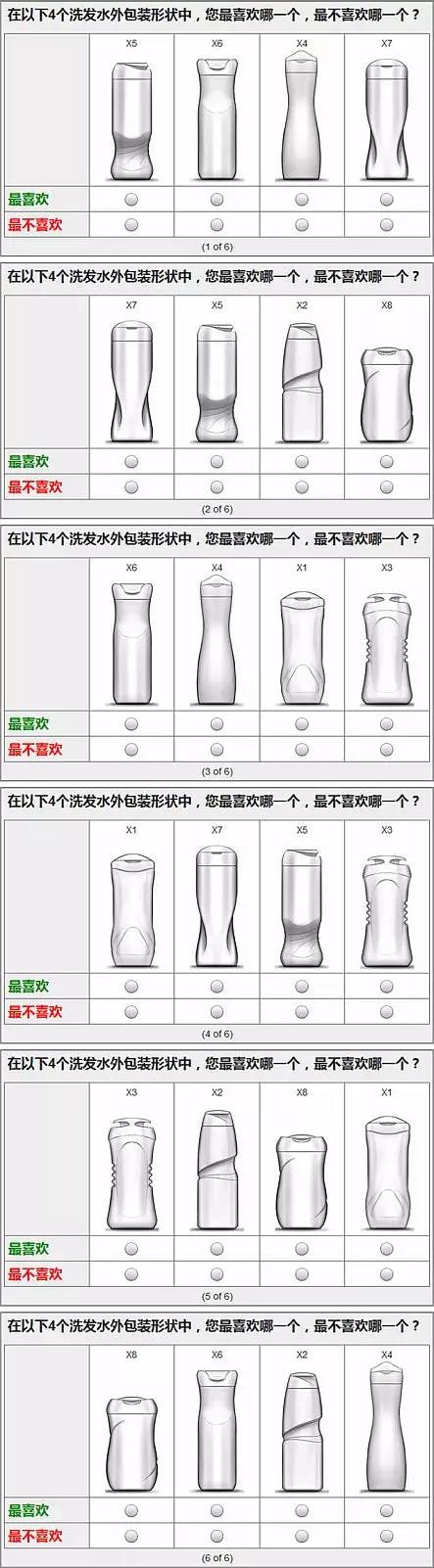
在这6个Maxdiff问题,可以看到每次只显示其中4个进行测量。但是,我们并不是每次随便地从8个外观中抽取4个进行测量。可以看到,每种外观设计都出现了3次,而且每个外观设计几乎均等的出现在每个位置上。这种设计实际上类似于实验设计中的平衡不完全区组设计(Balanced Incomplete Block Design,简称BIBD)。
通过这种巧妙地设计,我们既能获得单组MaxDiff测度不到的未确定对象比较信息,又保证了比较信息的稳定性(多组测量,且每个被测对象出现次数均等,位置随机),而且这种数据便于我们使用不同的统计方法进行分析,可谓一石多鸟。最重要的,这种方式使得受访者更容易理解和做出判断,试想一下子同时展示给你8个外观设计进行打分评价,还是很不容易完成的。

大家可以实际做一下这个Maxdiff的测试,http://survey.diagaid.com/Survey/SawtoothDemo/Maxdiff/DemoMaxdiff1/login.html
可能有读者又会有问题了,为什么这里需要问6个MaxDiff问题?每个问题里是只能出现4个对象还是可以更多?是否每个人都要完成一模一样的一组MaxDiff问题?
我们开始详细讲解如何设计MaxDiff。包括如何选择MaxDiff实验设计的参数,如何决定MaxDiff的样本量等实际操作问题以及如何评估一个MaxDiff设计是否良好!
在正式开始之前,我们先定义几个基础术语以便后文的阅读:
对象(Item)
需要在Maxdiff中进行比较的所有对象
任务(Task)
同时出示几个对象进行“最好/最差”的选择题。在这里,我们把每个这样的选择题称为一个任务
MaxDiff问题(MaxDiff question)
由多个Maxdiff任务所组成的一套题目
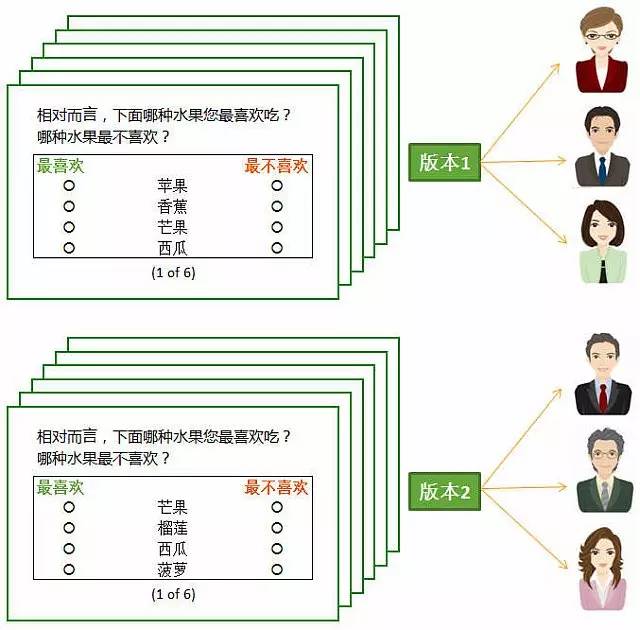
版本(version)
在具体调研时,我们不会让所有受试者都完成同一套MaxDiff题目。因此,我们会设计多个版本的MaxDiff问题,每个版本对应不同的受访者,以保证更好的随机性质。

MaxDiff的设计步骤
通常的MaxDiff设计步骤可以分为三步。
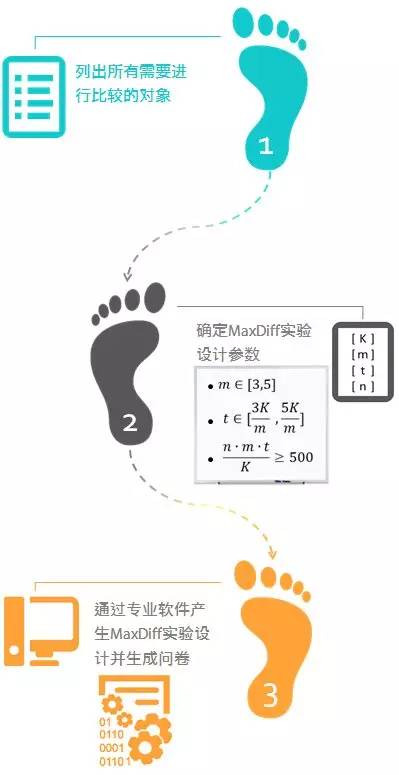
这里面最关键的是第二步,因为需要确定很多实验设计所需要考虑的参数,这里逐个说明下:


总的对象数目,即我们所有需要比较的对象总数。


每个任务中需出示的对象个数。笔者建议每个任务中出示3-5个对象,这是因为当每个任务里的对象超过5个时,受试者较难准确选出“最好/最差”的对象。比较下面两个任务,一个出示4个对象,另一个出示6个对象,您觉得哪个更容易完成呢?



每个MaxDiff问题需要包含的任务数量。理想状态下,我们希望在单个受试者层面的结果都尽可能的准确。为此,当受试者完成所有任务后,每个对象应至少出现了3-5次,那么可以很容易地推导出任务数(t)的公式:
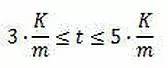
根据这个公式,我们可以很容易的编制一套任务数量的对照表,以便于我们在不同条件下快速确定所需要的任务数量:

例如,假设我们在MaxDiff中总共有8个对象(属性)需要比较,而且每个任务里出示4个对象,那么理想情况下,我们需要设计6~10个任务。


n即样本量。确定样本量大小的因素有很多,这里我们只谈谈针对MaxDiff这种特殊设计所涉及的样本量的考虑,至于其他一般性的基于抽样误差和非抽样误差的影响因素,这里就不赘述了。
RichardJohnson曾在1996年曾提出一种联合分析样本量的估算法,即必须满足每个属性水平(MaxDiff的各个对象)出现在MaxDiff里的总次数不少于500次。即
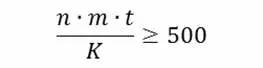
假设单个受访者层面上每个对象出现至少3次(mt/K=3),那么我们需要的最小样本量为167(=500/3)。从实际角度说,一般如果能够保证个体层面每个对象出现3次的话,样本量设为200是一个比较可行的选择。当然,如果为了进行一些分组分析或人群细分分析,我们需要确保每个组别或每个细分人群都能满足上述条件,假设最终的细分群为4-5个,且我们需要比较这些细分群之间MaxDiff计算结果的差异,那么相应的样本量应该是800-1000。
最后,还有一个参数需要注意一下,这个参数是MaxDiff问题的版本数。
版本数越多,我们可获得的比较信息越全面,因为每个人回答的 MaxDiff问题是不尽一致的,而且能使得实验设计更为均衡。但是,过多的版本数也没有必要。一般来说,通过计算机辅助的访问(无论是线上还是线下),可以将版本数控制在100-300,如果是纸笔问卷形式的访问,一般控制版本数4-10。
每个版本对应的样本数量不需完全一致。因为通过统计软件设计出来的每个版本的MaxDiff问题从统计学角度看都是等价的,但这只是一种“锦上添花”的行为,即便不完全满足,也影响不大。如今的调研越来越多的是计算机辅助的线上和线下调研,每个受访者完成的Maxdiff版本是随机派发的,这样就保证每个版本对应的样本数都非常接近。
讲到这里,大家可能会发现一个问题,当对象数目较多时,MaxDiff的任务数也变得很多,而且考虑到每个MaxDiff问题比直接比较和打分评测要更难一些,必然导致访问时间延长和受访者的疲惫及反感。那么是否一定要问那么多的任务以保证每个对象至少出现3次呢。答案是不一定,最近5年,有不少学者提出了一些很好的解决方案和思路,我们会在后续文章里单独予以介绍。
在设置好上面谈到的第一步和第二步确定的相应参数后,我们可以利用一些专门的软件生成实验设计和问卷。例如SAS,R等,但其中最权威,功能最丰富,最容易使用和最快速的软件无疑是SawtoothSoftware的MaxDiff模块。

在SawtoothSoftware里,你只需要输入对象列表,以及第二步谈到的诸多参数,软件就会自动生成设计和问卷(R和SAS等其他纯数学统计类软件仍需要将实验设计矩阵导出到其他软件里再编辑为问卷)。
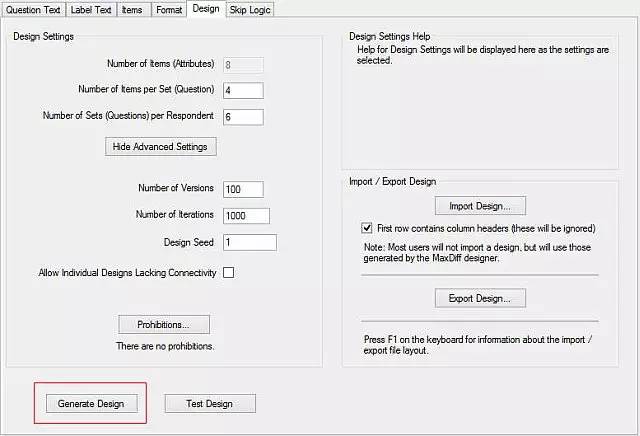
SawtoothSoftware的在线问卷设计和分析平台Discover(http://discover.sawtoothsoftware.com)在未来还将推出MaxDiff问卷设计工具,届时大家不用安装软件,直接用浏览器访问这个平台就可以定制自己的MaxDiff问题,发布问卷及在线分析MaxDiff数据了。
MaxDiff实验设计优劣判断标准
一个良好的MaxDiff实验设计应该满足以下4个条件。

以上这4个条件实际体现了两个核心要素——公平和效率。保证公平是为了测度结果准确,保证效率是为了节省时间和精力,两个都达到,就是“又快又准”。大家只要记住这两点就够了,这是实验设计最关键的统计思想。

被测对象出现的频率均等(FrequencyBalance):从测量误差的角度上说,如果不满足这个条件,将会导致“出镜率低”的对象的测量误差增大。这类似两个运动员比赛投篮,A运动员的成绩取其10次投篮的命中率,而B运动员取其2次投篮命中率,这显然容易导致不合理的结果出现。因此应该让A运动员和B运动员投掷相等的次数,然后再比较命中率的高低。
两两对象同时出现的频率一致(Orthogonality):这也是为了公平起见。我们在成长的过程中,往往都存在着一类特殊儿童—“别人家的孩子”。这些孩子品学兼优,多才多艺,身强体壮。家长往往拿自家孩子和“别人家的孩子”对比。自家的孩子经常会产生一种不公平的感觉。

这实际上就是一种家长对比孩子时两两对象比较频率不均等的现象。只有既把自己的孩子和特殊儿童对比,又和其他普通孩子比较,才能看到自己的孩子的真正位置。专业术语称这种特性为“正交(Orthogonality)”,当满足这个条件时,其设计矩阵里任意两列的乘积和恰好为0。这种正交性的好处在于可以准确估计每个对象的主效应(排除其他对象影响后的每个对象的自我效应)。有兴趣的读者可以找一些实验设计方面的书籍看看。
每个对象在MaxDiff题目中每个位置出现的频率相等(Positional Balance),是为了消除位置因素导致的影响。人在观察事物时,眼睛扫描对象存在一定的方向倾向,第一眼看到的内容的印象往往更加重要。所以,排在不同位置的对象往往会受到这种被关注次序的影响。比如体操比赛中,往往第一个上场的选手得分偏低。而在一些商业竞标中,第一次序出场的竞标者可能会得到更多的青睐。
所有对象均可“相连接”(Connectivity),我们曾在这个系列的第二篇介绍环状设计的成对比较时有过介绍。这实际指的是成对比较信息的可传递性问题。假设我们有只有2个Maxdiff问题,题目一需要你在A/B/C/D中指出“最好/最差”的对象,题目二需要你在“E/F/G/H”中指出“最好/最差”的对象。这时你会发现你无论如何也无法推算诸如A vs E的比较信息,因为第一题中4个对象的比较关系无法和第二题中4个对象的比较关系建立任何“连接”。
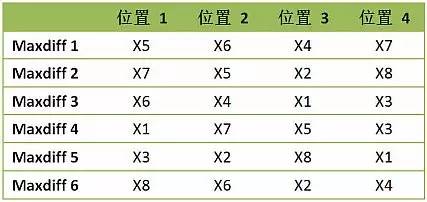
最后,我们回顾下上面提到的洗发水包装MaxDiff例子设计特性。这里我们有8种外包装类型,每个任务里出示4种外包装,总共6个任务(每个对象出现4X6/8=3次)。我让SawtoothSoftware的MaxDiff模块总共产生100个版本的MaxDiff问卷。假设这100个版本的问卷分别交由100个人完成,那么,其实验设计的检验表如下:

可以看到,上面这个MaxDiff的试验是非常好的,它满足了我们上面谈到的所有要求。
在估计Maxdiff题目中每个对象的偏好效用得分时,分层贝叶斯算法(Hierarchical Bayesian)是目前最普遍采用的方法,但这种方法比较耗时,且原理不太容易理解,很多人一看到分层贝叶斯这几个字,顿觉云里雾里(当然,在本节最后,我会简介这种方法的原理)。那么是否能够通过简单的方法来解释MaxDiff数据分析的原理呢?是否可以通过一些简单的计算方法也能保证较高的偏好估计准确性呢?
接下来我们会介绍一种常见的快捷计算方式。这个分析方式不但易于理解和计算,而且在很多情形下准确性也不亚于分层贝叶斯算法估算出来的偏好效用。
计数分析(Countinganalysis)
对于Maxdiff数据,最简单的分析方式无疑是计数分析。顾名思义,这种方法就是合计每个对象被选择为“最好”和“最差”的次数,然后进行推算的分析方法。
假设我们的MaxDiff里有8个对象,我们设置了6个任务,每个任务里随机出现4个对象,受访者每次从4个对象中选出一个“最好”和“最差”的对象。
基于上述条件,一个良好的设计能保证每个对象恰好出现3次(分别出现在3个任务中),例如下面的设计:
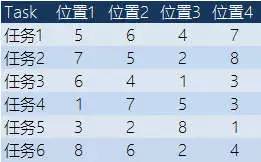
对于以上的设计而言,无论哪个对象,在这样的MaxDiff问题中被选择为“最好”或“最差”的情形都只能是以下10种结果之一。

我们也可以用一个表格来图示这10种可能结果。

如果要给每个结果一个对应的偏好度分数,很自然的,我们会想到用被选为“最好”的次数,减去被选为“最差”次数。那么上面的10种结果对应的分数就应该是
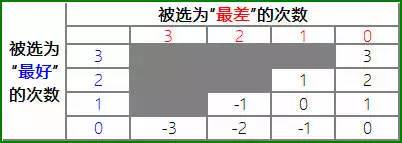
这里很清晰的看到,如果某个对象在其所出现的3个任务中均被选为“最好”,则其偏好分数被记为最高分3分,如果在其所出现的3个任务中均被选为“最差”,则其偏好分数被记为最低分-3。而且,最终的偏好分数只有(-3,-2,-1,0,1,2,3)这7种可能(7分量表?)。
更有意思的是,在这样的量表里,中间值0恰好代表无差异,且各个分值之间的差距是可比的(例如3分与2分间差异等同与2分与1分之间的差异,因为都代表着被选为“最好”次数比“最差”的次数多1次。这种量表的统计性质非常好。
比较下我们经常使用的7分量表

则无法保证中间值4分代表偏好无差异,也无法保证分值间的差距是可比的。
来看一个实际的计算例子,还记得本系列第三篇里提到的洗发水外包装的例子么,其中的某一个Maxdiff的任务是这样的(类似的任务总共有6个):

昨天晚上,我让我孩子做了一次上述的MaxDiff测试,并且我和老婆也各完成了一次测试。因此,我手上一共获得了3份有效的MaxDiff数据。
先来看看我孩子选择的结果:
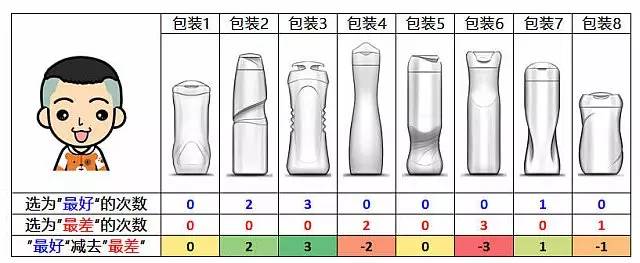
我儿最喜欢的是包装3,只要包装3出现,那么我儿子一定会把它选为“最好”,而他最不喜欢的无异是包装6,只要包装6出现,我儿会好不犹豫地把它选为“最差”。看来,我儿偏爱瓶型有纹路或凹槽的设计。
他的审美观和我及我老婆的很不一样,以下是我们一家三口的MaxDiff测试结果:

我老婆最爱包装4,这也好理解,作为女人,美好的事物往往是纤细苗条的。
尽管以上的Maxdiff计分方式产生了7个可能的分数,量表特性又非常好,那么会不会很多对象都会得到一样的高分或低分,从而导致无法凸显出最受欢迎/最不受欢迎的对象呢?
这个问题其实是关于以上计分(-3,-2,-1,0,1,2,3)的统计分布问题,通过计算机的随机模拟(让计算机随机产生500个受访者的答案,然后按以上计分准则计算每种分值出现的频率),我们很容易地可以得到这样的分布:
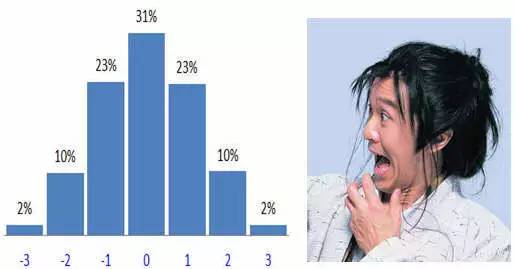
很多人看到这张分布图一定会泪流满面,因为这种分布形状是迄今为止概率统计学界上镜率最高(不是之一)的那个分布—正态分布。
也就是说,这种计数方式得到的MaxDiff分值是自带正态分布基因的。再说得通俗点,这种计分方式产生的分值,一定是要保证少数几个对象获得高分,少数几个对象获得低分,尽量拉开最好和最差的区别,也即Maximum Difference。这也是为什么这种测度方法最终被命名为Maximum Difference Scaling的原因。
再看一个实际的例子,笔者曾经执行过一个MaxDiff项目,正好也是8个对象的评测,总共需要完成6个任务,每个任务中出示4个对象进行“最喜欢”和“最不喜欢”的选择。样本量为303份。下图是按照上文所示计分方式得到的MaxDiff分析结果:
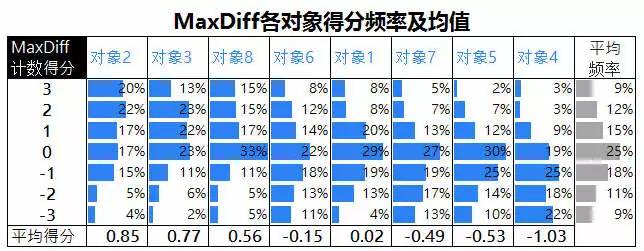
可以看到,尽管MaxDiff得分的平均频率(最后一列)是接近正态的,但在每个对象上的频率则有不同。对象2,对象3和对象8获得3分和2分的频率更高,那么相应的,其他对象获得高分的频率就肯定较低。
这种计数分析的结果,有时其精度并不亚于使用分层贝叶斯算法计算的MaxDiff得分。还是上面这个例子,我们来比较下最终的分层贝叶斯算法得到的MaxDiff得分与计数方式得到的MaxDiff得分有多大差异。
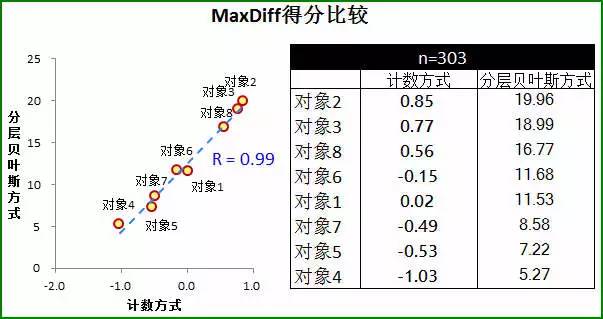
两者之间的相关性高达99%,几乎是一模一样的了。唯一的不同之处在于对象1和对象6,但是这两个对象间差异其实不大,且排名居中,并不影响我们判断出哪些是最受青睐和最不受青睐的对象。
令人吃惊的是,即便是在单个受访者层面,MaxDiff计数得分也和分层贝叶斯的计算结果具有极高的相似度。我们可以计算每个受访者通过这两种计算方法得到的MaxDiff得分的相关系数:

上述结果表明,所有受访者在两种方式测得的MaxDiff得分高度相似,最低相关系数都超过了0.9。这意味着在这个项目里,通过两种方式得到的MaxDiff得分几乎是相等的。
上面这些对比分析启发我们,当我们能保证每个受试者层面上,每个对象都能出现至少3次时,用计数分析就足够好了,又快又准。计算机辅助调查可以在受访者完成MaxDiff问题的几秒钟内就分析出该受访者对各个对象的偏好分值。
试想下前面的洗发水外包装MaxDiff,我们可以在受访者做完MaxDiff后,第一时间通过程序得知该受访者对所有8个对象的偏好排序,那么我们可以进一步的追问受访者为何最喜欢他最偏爱的对象。而不是在做完这个项目后再做一个项目去专门了解最受欢迎的对象/产品的具体原因。
最后,需要注意一下计数分析方式的使用局限性。当每个对象在Maxdiff问题中出现的频次无法达到3次时且不平衡时,那么,个体层面的准确性就会下降。但是这时总体层面(所有样本)的准确性仍然可以得到保证,只要样本量足够(保证在总体层面上每个对象至少出现500次或更多)。
分层贝叶斯分析(HierarchicalBayesian analysis)
最后,我给大家简单介绍下分层贝叶斯分析的原理。我们通过一个例子来说明。
大家一定有到餐厅吃饭的经历。点餐这个环节是很多人的痛,很多人都需要询问服务员的推荐。

假设有一家小餐厅新开业,有8道主打菜式,而且价钱都差不多。那么新开张的第一天,餐厅的老板如何预测每种菜式的被选择概率呢?
如果没有其他因素的帮助(譬如本地人爱吃辣),那么餐厅老板只能认为每个人对每道菜式的被选择概率是相等的,即假设食客对菜式无偏好。
餐厅开张营业了一个月,很多人都来这家餐厅用餐,老板在月底的时候统计最近了下这一个月的点餐单,发现菜式A/B/C最受青睐,而菜E/G/H的销量则差强人意。这个规律很重要,老板把这个发现告诉了所有的服务员。
在这家餐厅的所有顾客中,有两位经常来吃饭的食客,小强和小新。
小强每次来几乎都会选择B/D/E。某天小强又来消费了,这次他没有马上决定点什么菜,而是希望服务员能推荐几道菜式。服务员已经对小强有了印象,因为他差不多每次都点B/D/E,因此,这次她推荐B/D/E。
而小新每次来吃饭时对菜式的选择没有明显规律,尽管服务员看着她脸熟,但是却对她的偏好没有任何印象。因此,当小新希望服务员推荐几款菜式时。服务员只好推荐A/B/C,因为老板上个月底刚刚告诉她,过去一个月销量最好的是菜式A/B/C。
转眼一年过去了,餐厅老板在统计过去一年这8道菜式的销量时,发现A/C/E是销量最好的,和开业第一个月的菜式销量规律(第一个月A/B/C最畅销)有些不同了。他很重视这个发现,并且把这个规律告诉了负责点餐的服务员。
第二天,小强和小新又来餐厅吃饭。在过去这一年,小强还是偏爱B/D/E,不论是服务员推荐还是自己直接决定都是如此。而小新一如既往的无规律。这时,如果他俩希望服务员推荐菜式,服务员会如何推荐呢?
很明显,对于小强,服务员很可能还是推荐B/D/E,因为小强只喜欢这几个菜。
而对于小新,服务员最可能推荐的是A/C/E。因为小新点菜太随意,服务员完全记不住她到底最喜欢哪几道菜,而恰好昨天老板刚告诉她最近一年最受大众欢迎的是A/C/E。
这些逻辑看上去是如此地自然,如此地生活化,经常飘在外面吃饭的同学都深有体会。而其中隐藏的服务员对不同食客的菜式偏爱度的估算原理,正是分层贝叶斯估算原理:
最开始时,假设所有人对各个对象的偏好都相同(总体层面无偏好),但是迭代一段时间后(例如过了一个月),发现总体有偏好(A/B/C),而且这种总体偏好的改变是由不同个体(食客)的偏好导致的。
对于体现出明显偏好规律的个体,继续尊重和保留该个体的偏好。而对于没有体现出明显偏好规律的个体,则用总体偏好信息替代。个体偏好在不断修正总体偏好,而总体偏好也在不断修正个体偏好。这个过程不断地循环往复,直到达到一个可接受的稳定状态。
如果用数学语言描述,这个过程可以这样描述:
a = 每个对象偏好效用的样本总体均值向量
C = a的方差—协方差矩阵(即总样本偏好效用的变化幅度)
bi = 每个个体对每个对象的偏好效用,i = 1,2, …
为此,我们使用“吉布斯抽样(Gibbs Sampling)”:
我们从任意给定的 a, C和b的值开始
当我们知道这三者中任意两个时,我们就可以估算第三个
我们重复以下的循环迭代成千上万次:
1.给定b和C, 重新估计a
2.根据新的a和b, 重新估计C
3.根据新的a和新的C, 重新估计b
最初的几千次迭代只用于获得这个过程收敛特性,因此其结果不会被保存。当确保收敛后,后续的估计值可以被看成是从参数的后验分布里随机抽取的,并且可以用于分析。
特别的,每个个体在每个对象上最终偏好效用的“点估计”是成千上万次迭代过程中估计值的平均。
看明白了么?估计大多数人都不明白,但是也不需要大家对这个过程了解的那么清楚。复杂的演算过程交给计算机和软件吧,大家只要记住以下三点就可以了:
1.如果受访者的选择很有个性,那么个体层面的偏好效用估计值更多地依赖他们自己的规律,而受总体分布的影响较少(例如上文中的小强)。
2.如果受访者的选择没有个性(譬如他闭着眼睛随便选择),那么个体层面的偏好效用估计值更多地依赖总体信息,而受其自身回答的影响较小(例如上文中的小新)。
3.总体分布信息是随时会被个体影响的,譬如上文中第一个月大众最偏爱的菜式和第一年大众最偏爱的菜式是不同的。总体信息和个体信息在循环往复的影响下达到可接受的稳定状态。
通过SawtoothSoftware的HB模块,可以很轻松的进行分层贝叶斯估算,而且输出结果是每个受访者对每个对象的MaxDiff得分。下图是一个迭代运算的过程:
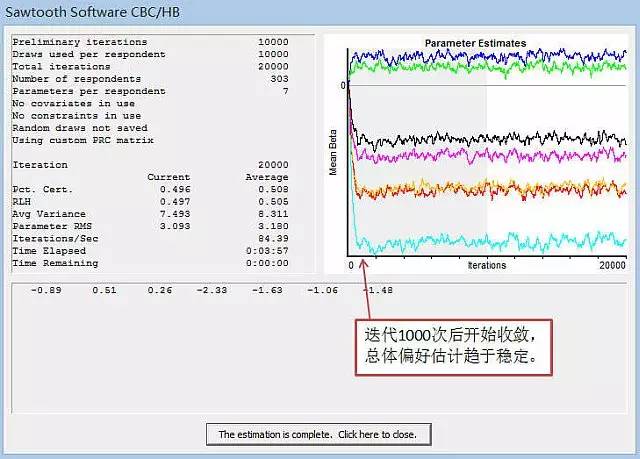
可以看到,总共进行了20000次迭代,且系统在1000次迭代后就开始收敛,总体层面的各对象偏好效用趋于稳定。而且每条线(代表每个对象的总体平均偏好)基本无交叉,且可以发现蓝绿线对应的对象最被看好,而最底下的浅蓝色线对应的对象最不被看好,中间的黄色和橙色线非常接近,说明这两个对象的偏好比较接近。
除了SawtoothSoftware,还有其他很多软件也可以进行分层贝叶斯估算。例如SAS的MCMC过程,R等。但SawtoothSoftware毫无疑问是操作最简便,功能最全面,且计算速度最快的。
本节是MaxDiff系列的最后一篇。希望这个系列能帮助大家提高对这项新的调研技术的认识。笔者水平有限,文章中如有错误和疏漏,敬请各位读者谅解!
未来我还会撰写一些最新的MaxDiff应用的简介文章。大家可以关注微信公众号“消费者研究”,第一时间阅读这些文章。
如有技术问题,可以通过fisherliu@diagaid.com进行咨询或切磋。或者访问SawtoothSoftware的官方网站,www.sawtoothsoftware.com获取关于联合分析和MaxDiff等技术的详细技术文档和软件。
注:以上文章欢迎转发分享,请注明出处;版权为大正市场研究公司所有,未经许可不得用于任何商业用途。
本文来自消费者研究,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:
注意:本文归作者所有,未经作者允许,不得转载

