Modeler 数据库内数据挖掘概述
当今一些主流的数据库(数据仓库)都提供了对联机分析处理(OLAP)和数据挖掘的支持,这是 由于 SQL 对大数据库进行的简单查询已经不能满足用户分析的需求,用户的决策分析需要对关系 数据库进行大量计算才能得到结果。OLAP 多维数据分析(切片、切块、钻取、旋转)和数据挖掘 (分类、预测、关联规则、聚类等)二者互为补充,为用户的决策分析提供了很好的帮助和支持。 IBM SPSS Modeler 除了自带有一套完整的数据挖掘算法以外,还整合了一些主流数据库提供商 (Oracle, DB2, SQL Server) 的数据挖掘算法,从而使得用户可以通过 Modeler 应用程序在数据库 中构建、评分和存储模型。这样做有以下几点好处:
- 将各数据库提供商的数据挖掘工具接口统一为 Modeler 简易的数据流风格界面;
- 数据库内数据挖掘的数据准备和数据处理工作可由 Modeler 完成;
- 当数据源位于数据库内部时,可以避免在数据库和 Modeler 之间来回移动数据带来的开销;
- 数据库内自带的算法常常与数据库服务器紧密结合,通常具有更高的性能;
- 在数据库内构建和存储的模型可由访问该数据库的应用程序共享。
此外,对数据库提供商新增加的数据挖掘算法,Modeler 会进行相应地同步,在新版本支持这些更新。
接下来分别对各数据库提供商的数据挖掘工具进行简单介绍:
Oracle Data Mining
Oracle 数据挖掘工具包含在 Oracle 数据库企业版中,该选项会随数据库自动安装并默认生效。详细步骤参见 Oracle 在线文档。
IBM InfoSphere Warehouse
IBM DB2 数据库本身不包含数据挖掘组件,该组件包含在 DB2 的数据仓库版本 InfoSphere Warehouse 中。 安装好 InfoSphere Warehouse 后,需要设置数据挖掘功能生效,可以通过 idmenabledb 命令进行设置。
SQL Server Analysis Services
与 SQL Server 中的任何组件一样,Analysis Services 既可以通过 SQL Server(2005 及以上版本)安装向导运行 SQL Server 安装程序 来安装,也可以通过在命令提示符下运行安装程序来安装。具体安装及配置步骤请参考 Micorosoft SQL Server 相关技术文档。
集成要求与启用
进行数据库建模,需要进行以下设置:
- 在已安装所需数据挖掘组件(Oracle Data Mining、IBM InfoSphere Warehouse 或 Microsoft Analysis Services)的 前提下,建立到相应数据库的 ODBC 连接
- 在 IBM SPSS Modeler 的“辅助应用程序”对话框(工具 > 选项 > 辅助应用程序)中启用数据库建模;
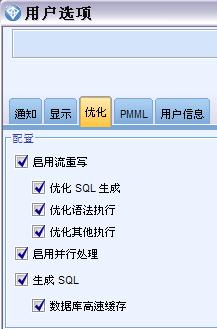
- 应该启用 IBM SPSS Modeler 以及 IBM SPSS Modeler Server(如果采用)中“用户选项”对话框(工具 > 选项 > 用户选项)内的生成 SQL 和 SQL 优化设置。详细信息请参阅 Modeler 帮助文档(帮助 > 帮助主题)中的服务器管理与性能 > SQL 优化。 注意,进行数据库 建模时不一定要启用 SQL 优化,但如果考虑到性能,则强烈建议启用此项。
图 1. 辅助应用程序对话框
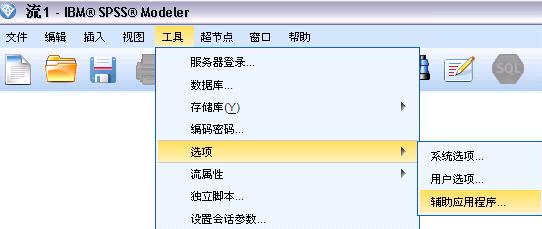
图 2. 用户选项对话框
根据各个数据库的具体环境,启用集成所需的步骤也不尽相同,具体请参考 IBM SPSS Modeler 帮助文档中的数据库内数据挖掘相关章节。
接下来的篇幅里,以 IBM InfoSphere Warehouse(简称 ISW)为例,说明如何进行数据库内的数据挖掘。
ISW 示例——启用集成
首先,在服务器上安好装 IBM InfoSphere Warehouse Server 相应版本(IBM DB2 Data Warehouse Edition Version 9.1 或者 IBM InfoSphere Warehouse Version 9.5 Enterprise Edition 及以上),并运行 idmenabledb 命令在数据库内创建数据挖掘相关对象。
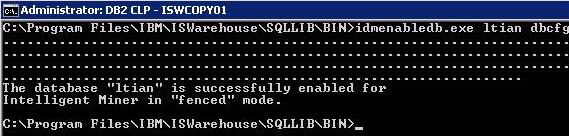
在安装好 IBM InfoSphere Warehouse Server 的机器上进入 DB2 命令窗口,进入 DB2 安装 BIN 目录(本例中为 C:\Program Files\IBM\ISWarehouse\SQLLIB\BIN), 对事先创建好的数据库(本例中为 ltian)执行 idmenabledb 命令 来生效该数据库内部的数据挖掘。
图 3. 运行 idmenabledb 命令
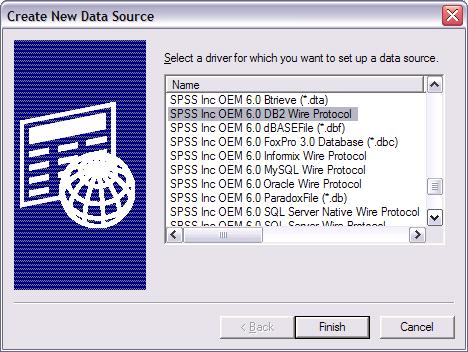
接下来回到 IBM SPSS Modeler Server 所在机器(如果使用 Modeler 桌面自带的 Server,则与 Modeler 桌面在同一台机器),配置 DB2 的 ODBC 数据源。 这里推荐使用 Modeler 附带的 IBM® SPSS® Data Access Pack(简称 SDAP)安装盘上的 ODBC 驱动程序,运行 setup.exe 文件以启动驱动程序安装,并选择 所有相关的驱动程序即可。以 Windows XP 为例,装好 SDAP 驱动程序后,从“开始”菜单中选择控制面板,双击管理工具,然后双击数据源 (ODBC),在打开 的对话框中选择系统 DSN 选项卡,然后单击添加, 选择 SPSS OEM 6.0 DB2 Wire Protocol 驱动程序,单击完成。
图 4. SDAP DB2 驱动程序
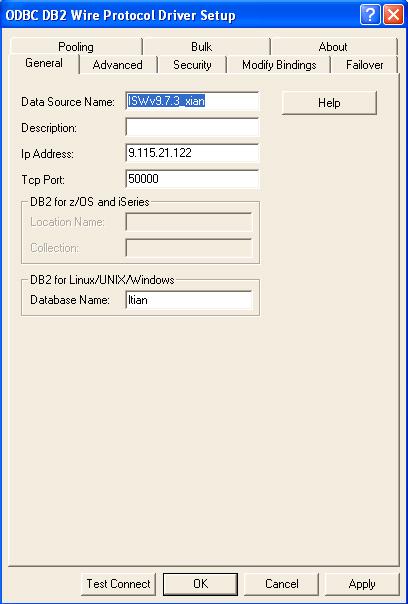
在“ODBC DB2 Wire Protocol 驱动程序设置”对话框中:
- 指定数据源名称;
- 对于 IP 地址,请指定 DB2 RDBMS 所在服务器的主机名;
- 接受默认的 TCP 端口 (50000);
- 指定要连接的数据库的名称;
- 单击测试连接。
在“登录 DB2 Wire Protocol”对话框中,输入数据库管理员提供给您的用户名和密码,然后单击确定。此时会显示连接已建立!的消息。
图 5. 配置 DB2 的 ODBC 数据源
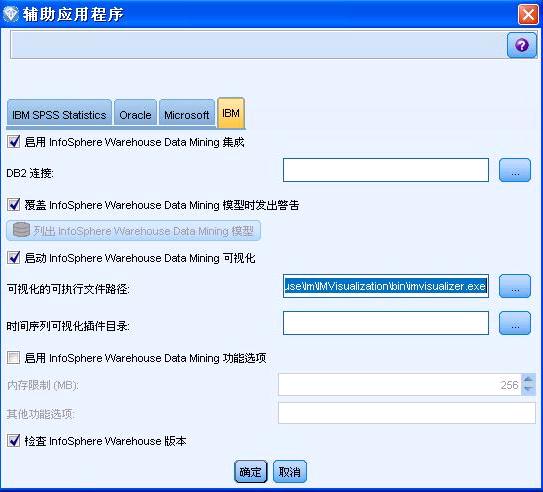
完成 ODBC 数据源配置后,按图 1 提示打开“辅助应用程序”对话框,点击“IBM”选项卡,进行如下设置:
- 启用 InfoSphere Warehouse Data Mining 集成。该选项在在数据库建模选项板中添加 ISW 算法建模节点, 其中包括决策树、关联、序列、聚类和回归。(启用之后,此选项板将与其他内容一起显示在 SPSS Modeler 窗口的底部。)
- DB2 连接。指定用于构建和存储模型的默认 DB2 ODBC 数据源。在单个模型建模和生成的模型节点上,此设置可以被覆盖。 单击省略号 (…) 按钮,选择数据源。
- 用于建模的数据库连接与数据源节点的数据库连接可以相同,也可以不相同。例如,可以有这样一个流,该流访问一个 DB2 数据库 ( 可以不是 InfoSphere Warehouse 数据仓库 ) 中的数据,将数据下载到 SPSS Modeler 进行清理或其他操作,然后再将数据上传 到另一个 DB2 数据库(必须是 InfoSphere Warehouse 数据仓库)用于建模。另外,原始数据可能会驻留在平面文件或其他(非 DB2)源 中,这种情况下也需要将数据上载到 DB2 用于建模。在所有情况下,如果需要,数据都将自动上载到在数据库中为建模而自动创建的 一个临时表中。
- 覆盖 InfoSphere Warehouse Data Mining 集成模型时发出警告。选中此选项,可确保只有在发出警告的情况下,数据库中存储的模型 才会被 Modeler 新生成的模型覆盖。
- 列出 InfoSphere Warehouse Data Mining 模型。通过此选项可列出和删除存储在 DB2 中的模型。
- 启动 InfoSphere Warehouse Data Mining 可视化。如果安装了可视化模块,则必须在此处启用才能用于 Modeler 查看模型。
- 可视化模块包含在 IBM InfoSphere Warehouse Client 版本中,可以与 Modeler 桌面安装在同一台机器上;
- 可视化的可执行文件路径。可视化模块的可执行文件(如已安装)的位置,例如 C:\Program Files\IBM\ISWarehouse\Im\IMVisualization\bin\imvisualizer.exe;
- 时间序列可视化插件目录。时间序列可视化 Flash 插件(如已安装)的位置,例如 C:\Program Files\IBM\ISWShared\plugins\com.ibm.datatools.datamining.imvisualization.flash_2.2.1.v20091111_0915。
- 启用 InfoSphere Warehouse Data Mining Power 选项。您可以针对数据库内挖掘算法设置内存使用限制,以命令行形式为特定模型 指定其他任意选项。通过内存限制,可以控制内存使用量,为功能选项 -buf 指定值。其他功能选项可以在此处以命令行形式指定, 并传递到 InfoSphere Warehouse Data Mining。
- 检查 InfoSphere Warehouse 版本。检查当前使用的 ISW 版本,如果您尝试使用当前版本不支持的数据挖掘功能,则报告错误。
图 6. InfoSphere Warehouse 集成设置
最后,跟据图 2 中所示,确定启用 SQL 生成和优化。
ISW 示例——建立模型
采用数据库算法构建模型的过程类似于 Modeler 自有算法的建模。唯一的不同是,模型构建实际上是在数据库内进行的。 建模前,首先需要准备好建模数据。
数据准备
采用数据库算法建模,如果原始数据存储在建模数据库中,为了提高性能,应尽可能将数据准备返回至数据库完成。这可以 通过 SQL 生成和优化来实现,目标就是通过确保所有需要的上游操作均可转换成 SQL 语句从而在数据库中执行。这样可以防止数据 被下载至 Modeler 并在处理完成后上传回数据库。通过以 SQL 形式在数据库中运行整个流,避免了移动数据的开销。
如果原始数据没有存储于数据库,则仍可使用数据库建模。此种情况下,将在 Modeler 中进行数据准备,准备好的数据集将自动 上载到建模数据库的临时表并进行模型构建。
下图显示了使用 SQL 生成和优化在数据库中完成数据库建模流的数据准备工作,紫色节点表示该节点的操作以 SQL 形式在数据库中执行。
图 7. SQL 生成和优化
ISW 数据挖掘算法集
接下来了解一下 ISW 数据挖掘算法集。ISW 提供了一系列数据挖掘算法,IBM SPSS Modeler 提供的节点支持对下列 ISW 算法的集成:
- 决策树
- 关联规则
- 聚类(人口统计、Kohonen)
- 序列规则
- 回归(变换、线性、多项式、RBF)
- Naive Bayes
- Logistic 回归
- 时间序列
图 8. ISW 数据挖掘算法集
![]()
![]()
通用的建模选项卡
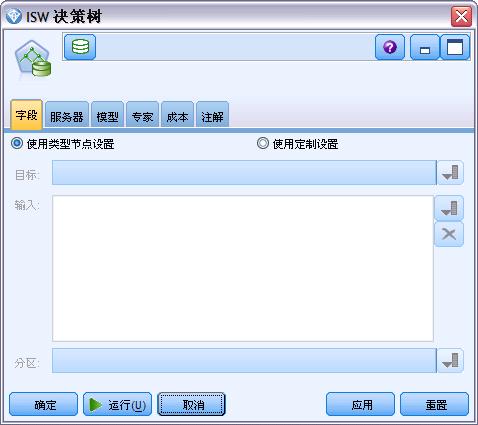
和 Modeler 内其他建模节点一样,可以通过字段选项卡指定目标和预测变量。
图 9. 字段选项卡
服务器选项卡指定用于建模的 ISW 连接。通过该选项卡可以为每个建模节点选择一个连接,以覆盖在“辅助应用程序”对话框 中指定的默认 ISW 连接。正如前面已经提到的,用于建模的连接可以与流的数据源节点中使用的连接相同,也可以不相同。
图 10. 服务器选项卡
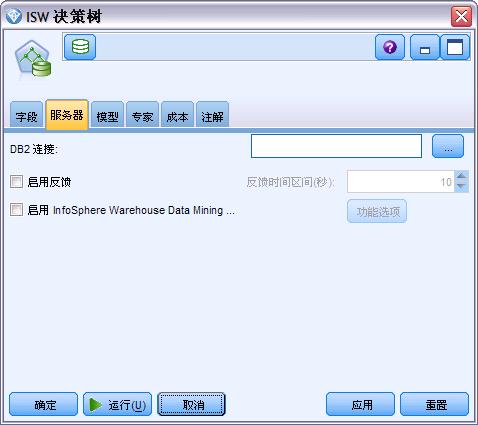
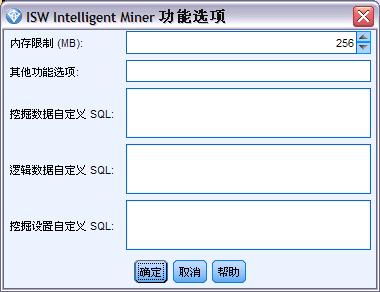
服务器选项卡都包含一个用于启用 ISW 建模功能选项的复选框。单击功能选项按钮时,将显示“ISW 功能选项”对话框,其中包括下列选项:
- 内存限制;
- 其它功能选项;
- 挖掘数据自定义(Mining data custom)SQL;
- 逻辑数据(Logical data custom)SQL;
- 挖掘设置(Mining settings custom)SQL。
如果熟悉 ISW 的数据挖掘 SQL 接口,对以上这些一定不会陌生,它使得用户可以通过 ISW 数据挖掘 SQL 接口的方法调用来修改 ISW 数据挖掘的相关对象, 比如 DM_MiningData 和 DM_LogicalDataSpec 对象。
图 11. ISW 功能选项卡
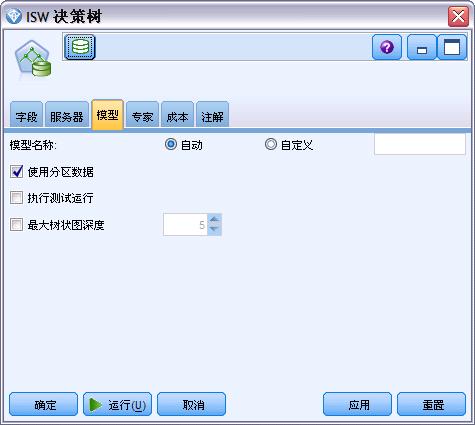
ISW 模型选项卡
服介绍完通用的建模选项卡,我们来看 ISW 模型选项卡。模型选项卡为相关节点提供主要建模参数的设置,不同的 ISW 建模节点,对应的模型选项卡 内容也不同。以 ISW 决策树为例,其模型选项如下:
- 模型名称。用户可根据目标或 ID 字段自动生成模型名称或指定一个自定义的名称。
- 使用分区数据。如果定义分区字段,请选择使用分区数据。
- 执行测试运行。选择此项将在训练分区上构建模型,之后在测试分区上执行测试运行以提升建立模型的质量。
- 最大树深度。您可以指定该参数,将树的深度限制为指定的级数。
图 12. ISW 决策树模型选项卡
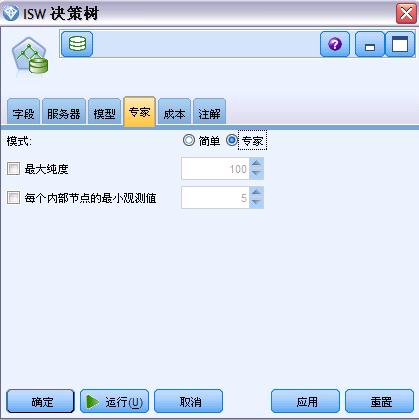
ISW 专家选项卡
ISW 专家选项为相关节点提供建模高级选项的设置,仍以 ISW 决策树为例,其专家选项如下:
- 最高纯度。此选项设置内部节点的最高纯度。如果分支某节点会导致其中一个子节点超过指定的纯度测量值 (比如,超过 95% 的观测值属于某个指定类别),则该节点不会分支。
- 每内部节点的最小观测值。如果分支某个节点会生成观测值数少于指定最小值的节点,将不会分支该节点。
图 13. ISW 决策树专家选项
ISW 示例——使用模型
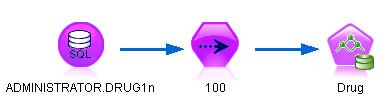
基于前面章节的介绍,我们已经可以在 Modeler 中使用 ISW 构建一个模型,仍以 ISW 决策树为例,构建模型的示例流如下图所示:
图 14. ISW 决策树建模示例
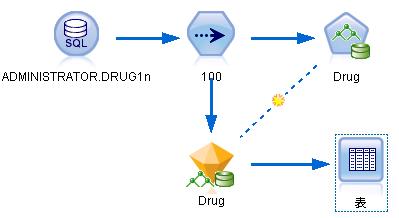
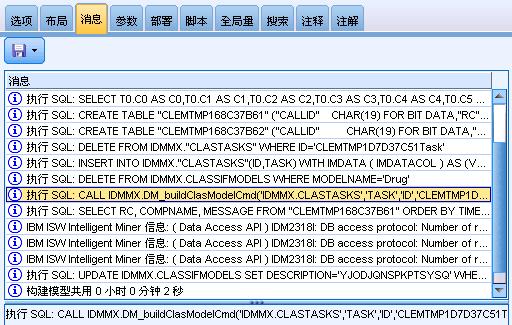
运行示例流中的建模节点生成模型后,点击 Modeler 桌面最底端中间偏右的按钮(或者从“打开”菜单中选择流属性)可以打开“流属性”对话框, 选择消息选项卡,可以轻松查看有关运行、优化、模型构建和评估所生成的 SQL 以及所用的时间等信息。
图 15. 查看流操作消息
模型评分
通过 Modeler 构建 ISW Data Mining 模型实际是保存在数据库服务器中的远程模型,在 Modeler 中所看到的其实是对这些远程模型的引用。 因此,对于数据库内数据挖掘,模型评分始终发生在数据库内部,并由 ISW Data Mining 执行。下表列出了模型评分生成的字段:
表 1. 模型评分字段
| 模型类型 | 得分列 | 含义 |
|---|---|---|
| 决策树 / 回归 / Naive Baye / Logistic 回归 | $I-field $IC-field |
field 的最佳预测 field 的最佳预测的置信度 |
| 聚类 | $I-model_name $IC-model_name |
model_name 输入记录的最佳聚类分配 输入记录的最佳聚类分配的置信度 |
| 关联 / 序列 | $I-model_name $IH-model_name $IHN-model_name $IS-model_name $IC-model_name $IL-model_name $IMB-model_name |
匹配规则的标识符 头项目 / 头项目集 头项目的名称 / 头项目集中项目的名称 匹配规则的支持度 匹配规则的置信度 匹配规则的提升值 匹配主体项目或主体项目集的数目 |
模型一致性检查
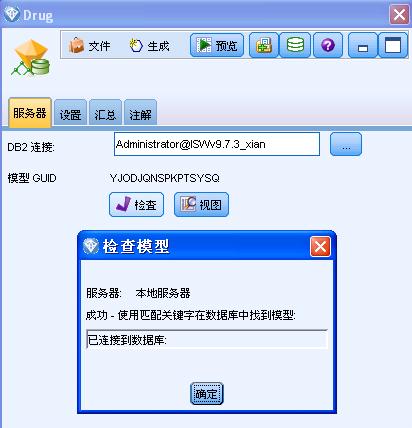
对于生成的每个数据库模型,Modeler 本地会存储一个模型说明,包含了远程数据库中所引用的模型的名称和关键字。其中,关键字 是 Modeler 创建模型时随机生成的,并同时存储于 Modeler 本地模型说明和远程所引用的模型中。这样,通过该模型关键字结合模型 名称,就可以完成本地和远程模型一致性的检查。ISW 模型块服务器选项卡中显示了该关键字(参见 图 16中 的“模型 GUID”),点击选项卡中的“检查”按钮可以执行模型一致性检查,如果在 ISW 中找不到具有相同名称的模型,或模型关键字不匹配, 说明数据库中的模型在构建之后被删除或重新构建。
图 16. ISW 模型块服务器选项卡
浏览模型
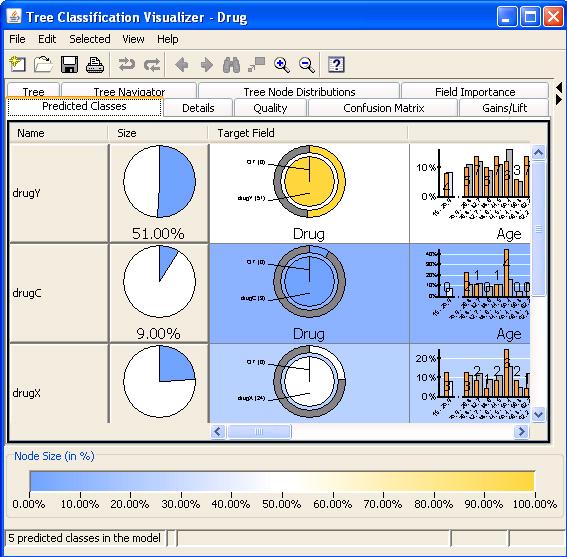
可视化工具是浏览 ISW Data Mining 模型的唯一方法。该工具随 InfoSphere Warehouse Client 一起安装。参见前面介绍的 ISW 启用集成示例。 ISW 模型块服务器选项卡提供了“视图”按钮用于浏览模型,单击“视图”可启动可视化工具。该工具显示的内容取决于生成的模型节点类型。 图 17显示了 ISW 决策树模型的可视化预测类视图,同时可以点击可视化工具的其他选项卡(比如 Field Importance – 变量 重要性)浏览模型更多的信息。
图 17. ISW 决策树模型可视化
结束语
通过本文,您已经对数据库提供商的数据挖掘工具有所了解,并且学会了如何在 IBM SPSS Modeler 中启用与它们的集成。这样,您就能够 使用 Modeler 简易的数据流风格界面方便快速进行数据库内数据挖掘。
本文中的 ISW 示例,从启用集成、建立模型和使用模型三个方面详细介绍了使用 Modeler 进行数据库内数据挖掘的相关操作。参考此示例, 您立刻就可以动手在数据库中构建您自己的模型。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e4%bd%bf%e7%94%a8-ibm-spss-modeler-%e8%bf%9b%e8%a1%8c%e6%95%b0%e6%8d%ae%e5%ba%93%e5%86%85%e6%95%b0%e6%8d%ae%e6%8c%96%e6%8e%98/
注意:本文归作者所有,未经作者允许,不得转载

