Selecting the right features in your data can mean the difference between mediocre performance with long training times and great performance with short training times.
The caret R package provides tools automatically report on the relevance and importance of attributes in your data and even select the most important features for you.
In this post you will discover the feature selection tools in the Caret R package with standalone recipes in R.
Remove Redundant Features
Data can contain attributes that are highly correlated with each other. Many methods perform better if highly correlated attributes are removed.
The Caret R package provides the findCorrelation which will analyze a correlation matrix of your data’s attributes report on attributes that can be removed.
The following example loads the Pima Indians Diabetes dataset that contains a number of biological attributes from medical reports. A correlation matrix is created from these attributes and highly correlated attributes are identified, in this case the age attribute is remove as it correlates highly with the pregnant attribute.
Generally, you want to remove attributes with an absolute correlation of 0.75 or higher.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# ensure the results are repeatable
set.seed(7)
# load the library
library(mlbench)
library(caret)
# load the data
data(PimaIndiansDiabetes)
# calculate correlation matrix
correlationMatrix <– cor(PimaIndiansDiabetes[,1:8])
# summarize the correlation matrix
print(correlationMatrix)
# find attributes that are highly corrected (ideally >0.75)
highlyCorrelated <– findCorrelation(correlationMatrix, cutoff=0.5)
# print indexes of highly correlated attributes
print(highlyCorrelated)
|
Rank Features By Importance
The importance of features can be estimated from data by building a model. Some methods like decision trees have a built in mechanism to report on variable importance. For other algorithms, the importance can be estimated using a ROC curve analysis conducted for each attribute.
The example below loads the Pima Indians Diabetes dataset and constructs an Learning Vector Quantization (LVQ) model. The varImp is then used to estimate the variable importance, which is printed and plotted. It shows that the glucose, mass and age attributes are the top 3 most important attributes in the dataset and the insulin attribute is the least important.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# ensure results are repeatable
set.seed(7)
# load the library
library(mlbench)
library(caret)
# load the dataset
data(PimaIndiansDiabetes)
# prepare training scheme
control <– trainControl(method=“repeatedcv”, number=10, repeats=3)
# train the model
model <– train(diabetes~., data=PimaIndiansDiabetes, method=“lvq”, preProcess=“scale”, trControl=control)
# estimate variable importance
importance <– varImp(model, scale=FALSE)
# summarize importance
print(importance)
# plot importance
plot(importance)
|
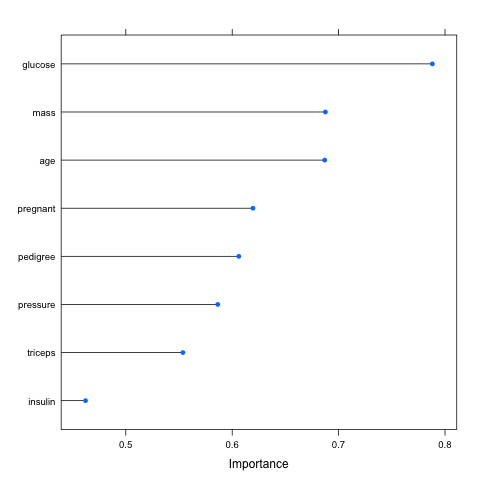
Rank of Features by Importance using Caret R Package
Feature Selection
Automatic feature selection methods can be used to build many models with different subsets of a dataset and identify those attributes that are and are not required to build an accurate model.
A popular automatic method for feature selection provided by the caret R package is calledRecursive Feature Elimination or RFE.
The example below provides an example of the RFE method on the Pima Indians Diabetes dataset. A Random Forest algorithm is used on each iteration to evaluate the model. The algorithm is configured to explore all possible subsets of the attributes. All 8 attributes are selected in this example, although in the plot showing the accuracy of the different attribute subset sizes, we can see that just 4 attributes gives almost comparable results.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# ensure the results are repeatable
set.seed(7)
# load the library
library(mlbench)
library(caret)
# load the data
data(PimaIndiansDiabetes)
# define the control using a random forest selection function
control <– rfeControl(functions=rfFuncs, method=“cv”, number=10)
# run the RFE algorithm
results <– rfe(PimaIndiansDiabetes[,1:8], PimaIndiansDiabetes[,9], sizes=c(1:8), rfeControl=control)
# summarize the results
print(results)
# list the chosen features
predictors(results)
# plot the results
plot(results, type=c(“g”, “o”))
|
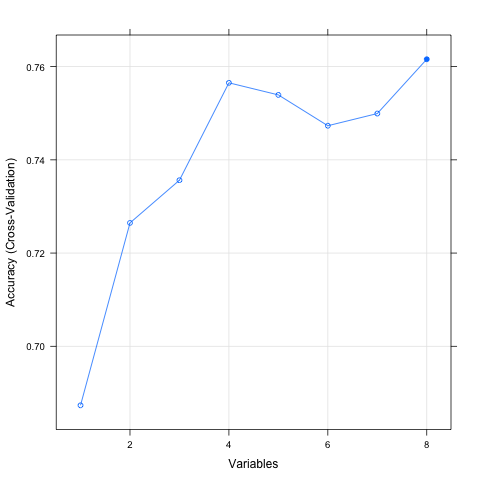
Feature Selection Using the Caret R Package
Summary
In this post you discovered 3 feature selection methods provided by the caret R package. Specifically, searching for and removing redundant features, ranking features by importance and automatically selecting a subset of the most predictive features.
Three standalone recipes in R were provided that you can copy-and-paste into your own project and adapt for your specific problems.
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/feature-selection-with-the-caret-r-package/
注意:本文归作者所有,未经作者允许,不得转载


