来自http://bbs.pinggu.org/thread-2448170-1-1.html
原始数据:
CUSTOMER TIME PRODUCT
0 0 hering
0 1 corned_b
0 2 olives
0 3 ham
0 4 turkey
0 5 bourbon
0 6 ice_crea
1 0 baguette
1 1 soda
1 2 hering
1 3 cracker
数据结构如上,共有三个字段:CUSTOMER TIME PRODUCT
libname emlib ‘C:\Users\Administrator\Desktop\emlib’;
proc dmdb batch data=emlib.assocs out=dmassoc dmdbcat=catassoc;
id customer time;
class product(desc);
run;
proc assoc data=emlib.assocs dmdbcat=catassoc
out=datassoc(label=’Output from Proc Assoc’)
items=5 support=20;
cust customer;
target product;
run;
proc rulegen in=datassoc
out=datrule(label=’Output from Proc Rulegen’)
minconf=75;
run;
proc print data=datrule;
run;
proc dmdb batch data=emlib.assocs out=dmassoc dmdbcat=catassoc;
id customer time;
class product(desc);
run;
proc assoc data=emlib.assocs dmdbcat=catassoc
out=datassoc(label=’Output from Proc Assoc’)
items=5 support=20;
cust customer;
target product;
run;
proc rulegen in=datassoc
out=datrule(label=’Output from Proc Rulegen’)
minconf=75;
run;
proc print data=datrule;
run;
关联分析代码如上,非常简单,主要用到两个过程PROC ASSOC和PROC RULEGEN1. PROC ASSOC 主要的作用为生成所有的K-项集,并统计其频率。格式如下:
PROC ASSOC <option(s)>;
CUSTOMER variable-list;
TARGET variable;
CUSTOMER variable-list;
TARGET variable;
option中最重要的两个分别为items=5 和support=20分别代表K项集的最大项目数阈值和支持度(support)
CUST statement 与TARGET statement分别代表你的标志变量和目标变量。
使用该过程的时候需要注意一点,引用SAS官方原文:
CUST statement 与TARGET statement分别代表你的标志变量和目标变量。
使用该过程的时候需要注意一点,引用SAS官方原文:
Processing an extremely large number of sets could cause your system to run out of disk and/or memory resources. However, by using a higher support level, you can reduce the item sets to a more manageable number.
如果你处理的是大数据,运行这个程序的时候可能会磁盘满或者内存溢出。为了避免这种情况的发生,在第一次运行的时候应该设置一个比较高的置信度。逐次递减。
2.PROC RULEGEN 主要的作用是生成关联规则,格式也非常的简单,如下:
2.PROC RULEGEN 主要的作用是生成关联规则,格式也非常的简单,如下:
PROC RULEGEN <option(s)>;
option主要是设置minconf:最小置信度(confidence)
3.运行后生成结果(部分)为:主要有:support(支持度)、confidence(置信度)、lift(梯度),rule(规则)
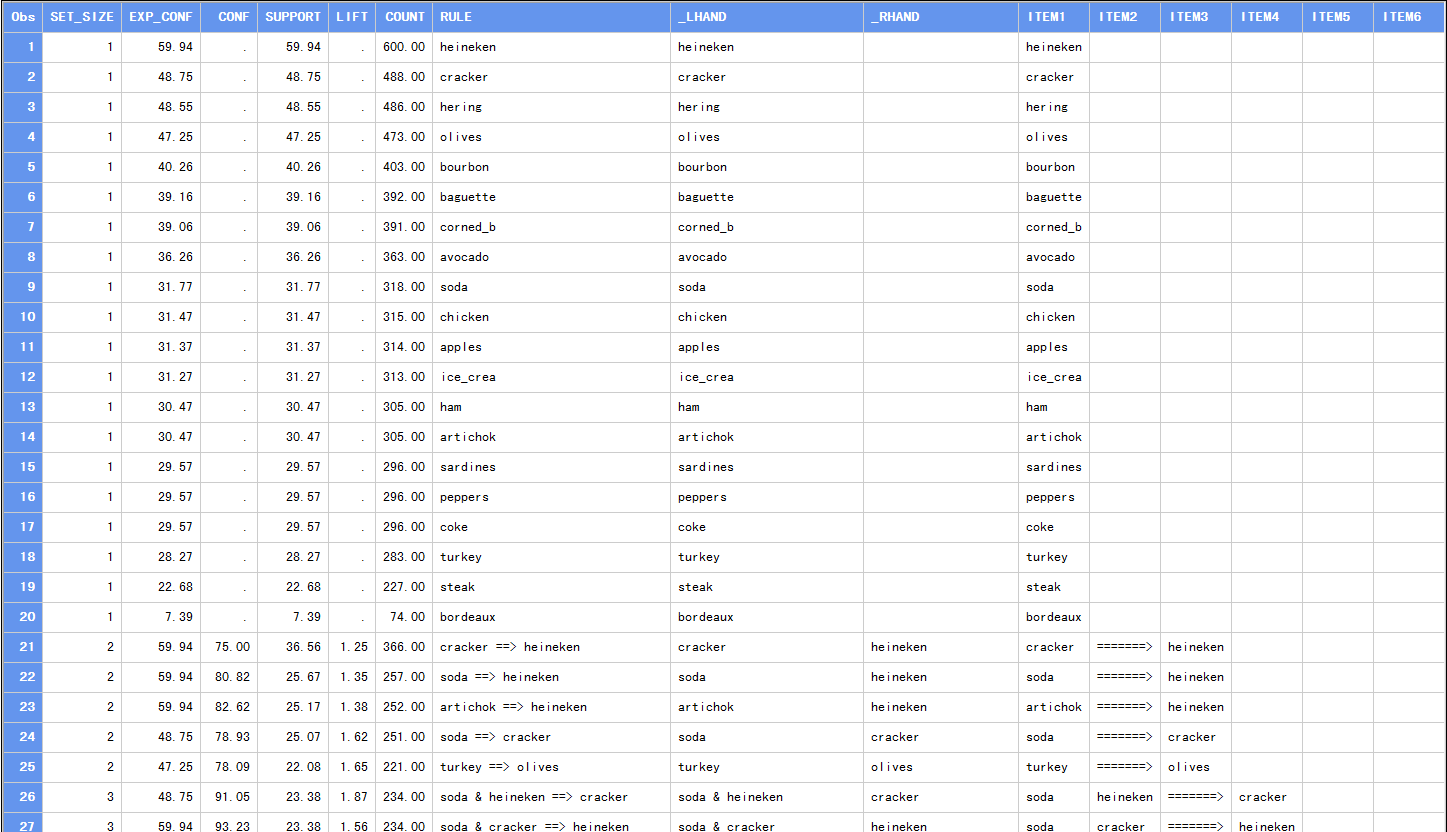
序列关联:
proc dmdb batch data=emlib.assocs out=dmassoc dmdbcat=catassoc;
id customer time;
class product(desc);
run;
proc sort data=datrule;
by descending lift;
run;
proc print data=datrule(obs=5) label;
var set_size exp_conf conf support lift count
rule _lhand _rhand;
title ‘Top Ten Rules based on Lift’;run;
proc sequence data=dmassoc dmdbcat=catassoc
assoc=datassoc out=sout(label=’output from proc sequence’)
nitems=4;
cust customer;
target product;
visit time/same=2;
run;
id customer time;
class product(desc);
run;
proc sort data=datrule;
by descending lift;
run;
proc print data=datrule(obs=5) label;
var set_size exp_conf conf support lift count
rule _lhand _rhand;
title ‘Top Ten Rules based on Lift’;run;
proc sequence data=dmassoc dmdbcat=catassoc
assoc=datassoc out=sout(label=’output from proc sequence’)
nitems=4;
cust customer;
target product;
visit time/same=2;
run;
时序关联唯一的区别是PROC DMDB(ps:这个过程在SAS/EM非常重要,基本所有数据挖掘过程运行前都必须运行这个过程。主要作用是为建模创建数据仓库)过程中加入标识变量为custom time。时间也加入标识变量之一。关键过程为PROC SEQUENCE
格式如下:
格式如下:
PROC SEQUENCE <option(s)>;
CUSTOMER variable(s);
TARGET variable;
VISIT variable /<visit-option(s)>;
CUSTOMER variable(s);
TARGET variable;
VISIT variable /<visit-option(s)>;
一起大数据提示您:
visit-option SAME and WINDOW specify the upper and lower timing limits of a sequence rule.SAME < time difference WINDOW. Visit-option can be as follows: SAME=same-number Specifies the lower time-limit between the occurrence of two events that you want to associate with each other. If the time difference between the two events is less than or equal to same-number (that is, it is ‘too soon’), then the two events are treated as occurring in the same visit, and the transaction is not counted. Default: 0 WINDOW=window-number Specifies the maximum time difference between the occurrence of two events that you want to be treated as the same visit. If the time difference is greater than window-number (that is, it is ‘too late’), then the transaction is treated as falling outside of the timing window, and the transaction is not counted. For NITEM-long sequence chain, WINDOW applies to the entire chain. Default: MAX
VISIT有两个参数,SAME 定义最小时间间隔,默认为0,也就是没次访问都看成独立的一次,如果设置为1,那么访问序列 1,2,3,4,5会被整合成 (1,2)(3,4)(5)三次。
WINDOW 定义最大的时间间隔,如果设置为3,那么访问序列1,5,不会生成任何有价值的序列,因为时间间隔太久了。
详情请参考 http://support.sas.com/documentation/onlinedoc/miner/em43/sequence.pdf
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e5%a6%82%e4%bd%95%e7%bc%96%e7%a8%8b%e8%b0%83%e7%94%a8em4-3%e4%b8%ad%e7%9a%84%e5%85%b3%e8%81%94%e5%88%86%e6%9e%90%e4%b8%8e%e6%97%b6%e5%ba%8f%e5%85%b3%e8%81%94%e8%bf%87%e7%a8%8b/
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

