算法简介
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。

算法过程如下:
1)从N个文档随机选取K个文档作为中心点;
2)对剩余的每个文档测量其到每个中心点的距离,并把它归到最近的质心的类;
3)重新计算已经得到的各个类的中心点;
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束。
算法优缺点:
优点:
- 对处理大数据集,该算法保持可伸缩性和高效性
- 算法快速、简单,易于理解;
缺点:
- 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的,具体应用中只能靠经验选取;
- 对噪声和孤立点数据敏感,导致均值偏离严重;
- 当数据量非常大时,算法的时间开销是非常大的;
- 初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果。
代码实现
第一步:读取文件,简单查看数据
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
from sklearn.cluster import KMeans
from sklearn.cluster import Birch
#读取文件
datafile = u'E:\\pythondata\\julei.xlsx'#文件所在位置,u为防止路径中有中文名称,此处没有,可以省略
outfile = u'E:\\pythondata\\julei_out.xlsx'#设置输出文件的位置
data = pd.read_excel(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件则用read_csv
d = DataFrame(data)
d.head()
assists height time age points 0 0.0888 201 36.02 28 0.5885 1 0.1399 198 39.32 30 0.8291 2 0.0747 198 38.80 26 0.4974 3 0.0983 191 40.71 30 0.5772 4 0.1276 196 38.40 28 0.5703
列名:助攻,身高,比赛时间,年龄,得分,根据这几项进行聚类。
第二步:聚类
#聚类
mod = KMeans(n_clusters=3, n_jobs = 4, max_iter = 500)#聚成3类数据,并发数为4,最大循环次数为500
mod.fit_predict(d)#y_pred表示聚类的结果
#聚成3类数据,统计每个聚类下的数据量,并且求出他们的中心
r1 = pd.Series(mod.labels_).value_counts()
r2 = pd.DataFrame(mod.cluster_centers_)
r = pd.concat([r2, r1], axis = 1)
r.columns = list(d.columns) + [u'类别数目']
print(r)
#给每一条数据标注上被分为哪一类
r = pd.concat([d, pd.Series(mod.labels_, index = d.index)], axis = 1)
r.columns = list(d.columns) + [u'聚类类别']
print(r.head())
r.to_excel(outfile)#如果需要保存到本地,就写上这一列第三步:可视化,简单的标注上分为哪一类怎么能满足?当然要看看可视化效果,毕竟注意一目了然的判断聚类的效果
#可视化过程
from sklearn.manifold import TSNE
ts = TSNE()
ts.fit_transform(r)
ts = pd.DataFrame(ts.embedding_, index = r.index)
import matplotlib.pyplot as plt
a = ts[r[u'聚类类别'] == 0]
plt.plot(a[0], a[1], 'r.')
a = ts[r[u'聚类类别'] == 1]
plt.plot(a[0], a[1], 'go')
a = ts[r[u'聚类类别'] == 2]
plt.plot(a[0], a[1], 'b*')
plt.show()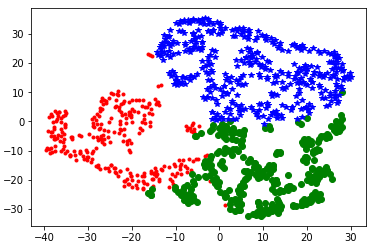
因为K-means 算法过于大众化,而且代码其实比较简单的,所以备注比较少,如果需要备注或者有任何疑问,欢迎留言。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/weixin_40683253/article/details/81288900
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e8%81%9a%e7%b1%bb%e5%88%86%e6%9e%90-k-means-python%e4%bb%a3%e7%a0%81%e5%ae%9e%e7%8e%b0/
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

