作者:凯文大哥
净推荐值(NPS)是测量客户忠诚度的一个常用指标,被认为可在一定程度上反映企业在当前和未来一段时间的持续盈利能力。企业开展NPS研究,往往包含至少两个方面的目的:1) 倾听客户反馈,从中得到洞察,以指导业务的不断改进和持续提升客户体验;2) 进行内部考核,因目前用户体验管理(CEM)已经被很多企业提升至最高运营目标之一,企业内各BU的用户体验提升绩效如何需要被定期监测和纳入奖惩机制。
将NPS用于考核目的,一个基本问题是:如何核定NPS分值之间的差距?简单粗暴地认定相差0.5、1或2个百分点即视为存在差距、并赋给不同排名,显然不能被接受,至少忽略了调查误差等因素。而引入统计学的显著性检验也明显不可行,一是因为检验结论与分值计算的样本量相关,从而难形成统一的排名规则(譬如,差值同为3个点,样本量足够时有统计显著性,而样本量不足够时则统计显著性得不到支持),二是这样形成的排名规则缺乏灵敏度,不具有实用性,譬如样本量在数百级别时,需要有5个点或更大差距才能得出分值间存在显著差异的结论、从而赋给不同排名。
那么,一个科学和严谨的做法应该是怎样的呢?我们的思路是:仔细检视调查得到的NPS分值的规律(即分布),然后尝试量化此分布,进而形成NPS得分的排名规则。其中,基本要求是:排名规则应具有适当的灵敏度,即在认知的一定差距(譬如2-3个点)下两个分值对应有不同的排名。
因为想要建立的量化分布与排序相关,自然很容易想到齐夫定律(Zipf’s law)。齐夫定律与人们熟知的帕累托法则(80-20法则)具有“统计等价性”,都用于描述同一种现象:多数,只能造成少许的影响;少数,往往会造成主要的、重大的影响。齐夫定律最早出现在词频分布中,之后在社会科学等诸多领域得到广泛重视。

就我们案例,借用上述齐夫定律,将NPS得分等同于频次F,则目标是得到对应的位序R ——而要达成此目标,只需确定公式中两个参数ɑ和C的取值。
调查针对智能手机,覆盖11个国家,每个国家关注4-6个品牌并区分高中低端市场,这样我们有约180个数据点(即NPS分值)可用。剔除掉样本量较小的,最终有效分析数据点约150个。如前面所述,仔细检视这些NPS分值的规律,譬如中位数、以及聚集在中部的大量分值,可以模拟推算出:

即,NPS分值与其位序相对应的量化分布得到确定,它能良好地反映当前的分析数据点的取值规律。
由此,我们也即形成NPS排名规则,如下示例:将品牌NPS得分代入公式,计算出对应位序、并调整后得到最终排名。
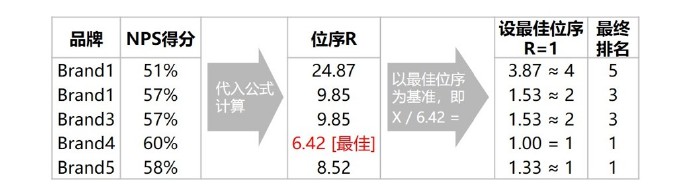
基于这样的量化NPS排名规则,企业可具体化其KPI考核标准,譬如要求NPS排名上升或是分值本身得到多大程度的提升。
需要注意的是,上述基于齐夫定律形成的NPS排名规则,其参数ɑ和C依赖于当期NPS分值的分布状况。如果不同期调查的NPS分值的分布状况差异较大,则排名规则需要相应调整以更准确地拟合当期数据集。
本文来自新浪博客,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:http://blog.sina.com.cn/s/blog_5e9798d30102yhw5.html
注意:本文归作者所有,未经作者允许,不得转载

