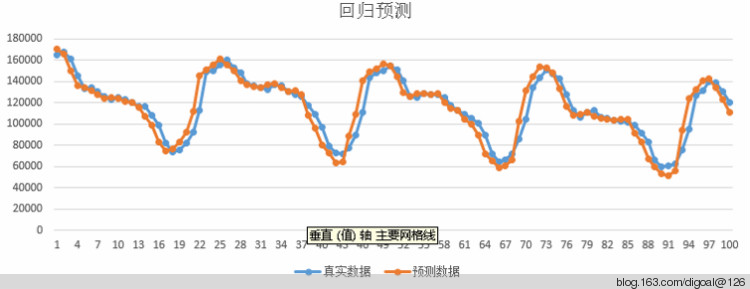
NOTICE: 样本数量436, 截距10109.8500, 斜率0.9573, 相关性0.9476
NOTICE: 真实数据165320, 预测数据170611, 本次预测偏差%3.2000
NOTICE: 样本数量436, 截距6909.3635, 斜率0.9872, 相关性0.9419
NOTICE: 真实数据167663, 预测数据165922, 本次预测偏差%1.0400
NOTICE: 样本数量436, 截距8151.8730, 斜率0.9754, 相关性0.9249
NOTICE: 真实数据161071, 预测数据150145, 本次预测偏差%6.7800
NOTICE: 样本数量436, 截距14388.5296, 斜率0.9135, 相关性0.9275
NOTICE: 真实数据145570, 预测数据136026, 本次预测偏差%6.5600
NOTICE: 样本数量437, 截距30451.0167, 斜率0.7726, 相关性0.9570
NOTICE: 真实数据133155, 预测数据133953, 本次预测偏差%0.6000
NOTICE: 样本数量446, 截距343.4262, 斜率1.0262, 相关性0.9785
NOTICE: 真实数据133962, 预测数据134241, 本次预测偏差%0.2100
NOTICE: 样本数量437, 截距31491.5019, 斜率0.7616, 相关性0.9494
NOTICE: 真实数据130484, 预测数据127596, 本次预测偏差%2.2100
NOTICE: 样本数量438, 截距48512.9273, 斜率0.6126, 相关性0.9484
NOTICE: 真实数据126182, 预测数据123864, 本次预测偏差%1.8400
NOTICE: 样本数量438, 截距50299.8161, 斜率0.5940, 相关性0.9526
NOTICE: 真实数据122998, 预测数据124578, 本次预测偏差%1.2800
NOTICE: 样本数量442, 截距33561.3690, 斜率0.7444, 相关性0.9983
NOTICE: 真实数据125052, 预测数据125119, 本次预测偏差%0.0500
NOTICE: 样本数量438, 截距50126.2968, 斜率0.5954, 相关性0.9475
NOTICE: 真实数据123000, 预测数据121572, 本次预测偏差%1.1600
NOTICE: 样本数量438, 截距52640.6564, 斜率0.5687, 相关性0.9400
NOTICE: 真实数据119991, 预测数据118710, 本次预测偏差%1.0700
NOTICE: 样本数量438, 截距55198.2911, 斜率0.5404, 相关性0.9301
NOTICE: 真实数据116182, 预测数据118363, 本次预测偏差%1.8800
NOTICE: 样本数量438, 截距43721.8498, 斜率0.6665, 相关性0.9845
NOTICE: 真实数据116887, 预测数据116082, 本次预测偏差%0.6900
NOTICE: 样本数量1, 截距4661.3951, 斜率0.9464, 相关性0.8978
NOTICE: 真实数据108562, 预测数据98517, 本次预测偏差%9.2500
NOTICE: 样本数量1, 截距4675.5276, 斜率0.9460, 相关性0.8979
NOTICE: 真实数据99168, 预测数据82725, 本次预测偏差%16.5800
NOTICE: 样本数量432, 截距39520.3078, 斜率0.4823, 相关性0.9201
NOTICE: 真实数据82505, 预测数据74942, 本次预测偏差%9.1700
NOTICE: 样本数量432, 截距31502.3387, 斜率0.5457, 相关性0.9985
NOTICE: 真实数据73450, 预测数据72804, 本次预测偏差%0.8800
NOTICE: 样本数量432, 截距30417.7790, 斜率0.5542, 相关性0.9989
NOTICE: 真实数据75681, 预测数据76143, 本次预测偏差%0.6100
NOTICE: 样本数量432, 截距31775.6232, 斜率0.5440, 相关性0.9992
NOTICE: 真实数据82509, 预测数据82187, 本次预测偏差%0.3900
NOTICE: 样本数量1, 截距4622.2503, 斜率0.9465, 相关性0.8993
NOTICE: 真实数据92670, 预测数据111447, 本次预测偏差%20.2600
NOTICE: 样本数量1, 截距4531.6850, 斜率0.9481, 相关性0.9003
NOTICE: 真实数据112865, 预测数据145539, 本次预测偏差%28.9500
NOTICE: 样本数量412, 截距19211.5611, 斜率0.8778, 相关性0.9590
NOTICE: 真实数据148731, 预测数据150848, 本次预测偏差%1.4200
NOTICE: 样本数量412, 截距18806.5399, 斜率0.8820, 相关性0.9580
NOTICE: 真实数据149961, 预测数据156169, 本次预测偏差%4.1400
NOTICE: 样本数量412, 截距17050.6057, 斜率0.8991, 相关性0.9603
NOTICE: 真实数据155748, 预测数据161289, 本次预测偏差%3.5600
NOTICE: 样本数量412, 截距14830.5241, 斜率0.9202, 相关性0.9607
NOTICE: 真实数据160430, 预测数据155939, 本次预测偏差%2.8000
NOTICE: 样本数量412, 截距16540.9704, 斜率0.9034, 相关性0.9574
NOTICE: 真实数据153344, 预测数据150240, 本次预测偏差%2.0200
NOTICE: 样本数量412, 截距17692.1060, 斜率0.8917, 相关性0.9532
NOTICE: 真实数据147997, 预测数据140772, 本次预测偏差%4.8800
NOTICE: 样本数量414, 截距41717.5731, 斜率0.6980, 相关性0.9736
NOTICE: 真实数据138023, 预测数据137013, 本次预测偏差%0.7300
NOTICE: 样本数量414, 截距42191.4454, 斜率0.6933, 相关性0.9722
NOTICE: 真实数据136535, 预测数据135075, 本次预测偏差%1.0700
NOTICE: 样本数量414, 截距42836.5141, 斜率0.6866, 相关性0.9716
NOTICE: 真实数据133978, 预测数据133909, 本次预测偏差%0.0500
NOTICE: 样本数量414, 截距42868.4919, 斜率0.6863, 相关性0.9698
NOTICE: 真实数据132634, 预测数据136891, 本次预测偏差%3.2100
NOTICE: 样本数量414, 截距39356.6117, 斜率0.7213, 相关性0.9849
NOTICE: 真实数据136998, 预测数据137674, 本次预测偏差%0.4900
NOTICE: 样本数量418, 截距-98886.5041, 斜率1.7965, 相关性0.9925
NOTICE: 真实数据136303, 预测数据136431, 本次预测偏差%0.0900
NOTICE: 样本数量414, 截距41274.0892, 斜率0.7011, 相关性0.9848
NOTICE: 真实数据130987, 预测数据130817, 本次预测偏差%0.1300
NOTICE: 样本数量414, 截距41537.1100, 斜率0.6983, 相关性0.9803
NOTICE: 真实数据127722, 预测数据129731, 本次预测偏差%1.5700
NOTICE: 样本数量414, 截距35567.9284, 斜率0.7625, 相关性0.9901
NOTICE: 真实数据126303, 预测数据124949, 本次预测偏差%1.0700
NOTICE: 样本数量414, 截距41599.7365, 斜率0.6944, 相关性0.9993
NOTICE: 真实数据117218, 预测数据117405, 本次预测偏差%0.1600
NOTICE: 样本数量413, 截距1686.3033, 斜率1.1262, 相关性0.8957
NOTICE: 真实数据109160, 预测数据110726, 本次预测偏差%1.4300
NOTICE: 样本数量412, 截距-126088.7154, 斜率2.7998, 相关性0.9671
NOTICE: 真实数据96823, 预测数据97097, 本次预测偏差%0.2800
NOTICE: 样本数量408, 截距36426.6219, 斜率0.5003, 相关性0.9205
NOTICE: 真实数据79716, 预测数据72776, 本次预测偏差%8.7100
NOTICE: 样本数量408, 截距29915.3284, 斜率0.5522, 相关性0.9813
NOTICE: 真实数据72658, 预测数据69530, 本次预测偏差%4.3100
NOTICE: 样本数量409, 截距30542.2158, 斜率0.5286, 相关性0.9970
NOTICE: 真实数据71739, 预测数据71377, 本次预测偏差%0.5100
NOTICE: 样本数量408, 截距21294.1724, 斜率0.6206, 相关性0.9985
NOTICE: 真实数据77243, 预测数据76786, 本次预测偏差%0.5900
NOTICE: 样本数量1, 截距4921.7169, 斜率0.9414, 相关性0.8898
NOTICE: 真实数据89412, 预测数据109386, 本次预测偏差%22.3400
NOTICE: 样本数量406, 截距-771730.9711, 斜率6.1383, 相关性0.9650
NOTICE: 真实数据110972, 预测数据112269, 本次预测偏差%1.1700
NOTICE: 样本数量388, 截距15580.3852, 斜率0.9001, 相关性0.9520
NOTICE: 真实数据144014, 预测数据149237, 本次预测偏差%3.6300
NOTICE: 样本数量388, 截距14377.9729, 斜率0.9129, 相关性0.9524
NOTICE: 真实数据148483, 预测数据151688, 本次预测偏差%2.1600
NOTICE: 样本数量388, 截距13455.2553, 斜率0.9226, 相关性0.9497
NOTICE: 真实数据150405, 预测数据156324, 本次预测偏差%3.9400
NOTICE: 样本数量402, 截距71505.3386, 斜率0.5561, 相关性0.9759
NOTICE: 真实数据154850, 预测数据155607, 本次预测偏差%0.4900
NOTICE: 样本数量388, 截距11270.4334, 斜率0.9451, 相关性0.9387
NOTICE: 真实数据151244, 预测数据144638, 本次预测偏差%4.3700
NOTICE: 样本数量388, 截距14060.3682, 斜率0.9147, 相关性0.9332
NOTICE: 真实数据141118, 预测数据129415, 本次预测偏差%8.2900
NOTICE: 样本数量390, 截距36957.1231, 斜率0.7099, 相关性0.9656
NOTICE: 真实数据126106, 预测数据125617, 本次预测偏差%0.3900
NOTICE: 样本数量390, 截距37150.1505, 斜率0.7077, 相关性0.9636
NOTICE: 真实数据124896, 预测数据128489, 本次预测偏差%2.8800
NOTICE: 样本数量390, 截距34760.7660, 斜率0.7330, 相关性0.9714
NOTICE: 真实数据129061, 预测数据128477, 本次预测偏差%0.4500
NOTICE: 样本数量390, 截距35229.1317, 斜率0.7280, 相关性0.9667
NOTICE: 真实数据127849, 预测数据128208, 本次预测偏差%0.2800
NOTICE: 样本数量392, 截距4342.9938, 斜率1.0018, 相关性0.9702
NOTICE: 真实数据127715, 预测数据129117, 本次预测偏差%1.1000
NOTICE: 样本数量393, 截距-32076.9878, 斜率1.3312, 相关性0.9964
NOTICE: 真实数据124554, 预测数据124206, 本次预测偏差%0.2800
NOTICE: 样本数量393, 截距-19541.0766, 斜率1.2152, 相关性1.0000
NOTICE: 真实数据117397, 预测数据117404, 本次预测偏差%0.0100
NOTICE: 样本数量390, 截距47549.0400, 斜率0.5872, 相关性0.9902
NOTICE: 真实数据112693, 预测数据111435, 本次预测偏差%1.1200
NOTICE: 样本数量390, 截距50098.4943, 斜率0.5560, 相关性0.9977
NOTICE: 真实数据108804, 预测数据108821, 本次预测偏差%0.0200
NOTICE: 样本数量390, 截距50042.2813, 斜率0.5567, 相关性0.9964
NOTICE: 真实数据105623, 预测数据105973, 本次预测偏差%0.3300
NOTICE: 样本数量1, 截距5273.1579, 斜率0.9358, 相关性0.8782
NOTICE: 真实数据100474, 预测数据89115, 本次预测偏差%11.3100
NOTICE: 样本数量1, 截距5280.4763, 斜率0.9354, 相关性0.8785
NOTICE: 真实数据89591, 预测数据72087, 本次预测偏差%19.5400
NOTICE: 样本数量384, 截距30325.0273, 斜率0.5354, 相关性0.9387
NOTICE: 真实数据71422, 预测数据64918, 本次预测偏差%9.1100
NOTICE: 样本数量386, 截距37631.4820, 斜率0.4029, 相关性0.9941
NOTICE: 真实数据64616, 预测数据64377, 本次预测偏差%0.3700
NOTICE: 样本数量384, 截距20707.7226, 斜率0.6191, 相关性0.9961
NOTICE: 真实数据66389, 预测数据65428, 本次预测偏差%1.4500
NOTICE: 样本数量384, 截距17341.5766, 斜率0.6472, 相关性0.9978
NOTICE: 真实数据72238, 预测数据72772, 本次预测偏差%0.7400
NOTICE: 样本数量1, 截距5202.6036, 斜率0.9363, 相关性0.8805
NOTICE: 真实数据85644, 预测数据102774, 本次预测偏差%20.0000
NOTICE: 样本数量382, 截距-211937.8855, 斜率2.3700, 相关性0.9232
NOTICE: 真实数据104207, 预测数据107341, 本次预测偏差%3.0100
NOTICE: 样本数量363, 截距10473.2297, 斜率0.9328, 相关性0.9381
NOTICE: 真实数据134716, 预测数据144319, 本次预测偏差%7.1300
NOTICE: 样本数量363, 截距8082.7467, 斜率0.9608, 相关性0.9426
NOTICE: 真实数据143484, 预测数据153571, 本次预测偏差%7.0300
NOTICE: 样本数量379, 截距90033.9242, 斜率0.4106, 相关性0.9539
NOTICE: 真实数据151426, 预测数据150648, 本次预测偏差%0.5100
NOTICE: 样本数量363, 截距3555.4288, 斜率1.0121, 相关性0.9344
NOTICE: 真实数据147628, 预测数据148068, 本次预测偏差%0.3000
NOTICE: 样本数量377, 截距-22855.0642, 斜率1.3040, 相关性0.9608
NOTICE: 真实数据142781, 预测数据143858, 本次预测偏差%0.7500
NOTICE: 样本数量363, 截距8135.3139, 斜率0.9564, 相关性0.9081
NOTICE: 真实数据127852, 预测数据116232, 本次预测偏差%9.0900
NOTICE: 样本数量363, 截距11650.2051, 斜率0.9095, 相关性0.9209
NOTICE: 真实数据113022, 预测数据107993, 本次预测偏差%4.4500
NOTICE: 样本数量366, 截距43850.9025, 斜率0.5911, 相关性0.9231
NOTICE: 真实数据105932, 预测数据109352, 本次预测偏差%3.2300
NOTICE: 样本数量366, 截距41459.4112, 斜率0.6193, 相关性0.9421
NOTICE: 真实数据110807, 预测数据111147, 本次预测偏差%0.3100
NOTICE: 样本数量366, 截距41099.7207, 斜率0.6234, 相关性0.9330
NOTICE: 真实数据112531, 预测数据107192, 本次预测偏差%4.7400
NOTICE: 样本数量366, 截距45144.8340, 斜率0.5733, 相关性0.9910
NOTICE: 真实数据106011, 预测数据105444, 本次预测偏差%0.5400
NOTICE: 样本数量366, 截距45652.0542, 斜率0.5670, 相关性0.9907
NOTICE: 真实数据105170, 预测数据104365, 本次预测偏差%0.7600
NOTICE: 样本数量368, 截距57233.9599, 斜率0.4495, 相关性0.9969
NOTICE: 真实数据103554, 预测数据103401, 本次预测偏差%0.1500
NOTICE: 样本数量368, 截距58816.4609, 斜率0.4327, 相关性0.9999
NOTICE: 真实数据102706, 预测数据102719, 本次预测偏差%0.0100
NOTICE: 样本数量366, 截距45837.1316, 斜率0.5648, 相关性0.9874
NOTICE: 真实数据101460, 预测数据101473, 本次预测偏差%0.0100
NOTICE: 样本数量366, 截距45788.3201, 斜率0.5655, 相关性0.9787
NOTICE: 真实数据98505, 预测数据97660, 本次预测偏差%0.8600
NOTICE: 样本数量1, 截距5430.0126, 斜率0.9322, 相关性0.8723
NOTICE: 真实数据91734, 预测数据83227, 本次预测偏差%9.2700
NOTICE: 样本数量1, 截距5423.3347, 斜率0.9320, 相关性0.8726
NOTICE: 真实数据83453, 预测数据66847, 本次预测偏差%19.9000
NOTICE: 样本数量360, 截距30435.2931, 斜率0.4928, 相关性0.9223
NOTICE: 真实数据65904, 预测数据59957, 本次预测偏差%9.0200
NOTICE: 样本数量360, 截距25313.6494, 斜率0.5394, 相关性0.9738
NOTICE: 真实数据59911, 预测数据58046, 本次预测偏差%3.1100
NOTICE: 样本数量360, 截距22789.5261, 斜率0.5623, 相关性0.9761
NOTICE: 真实数据60677, 预测数据57848, 本次预测偏差%4.6600
NOTICE: 样本数量360, 截距14289.6380, 斜率0.6383, 相关性1.0000
NOTICE: 真实数据62350, 预测数据62309, 本次预测偏差%0.0700
NOTICE: 样本数量1, 截距5349.6991, 斜率0.9328, 相关性0.8743
NOTICE: 真实数据75224, 预测数据94495, 本次预测偏差%25.6200
NOTICE: 样本数量1, 截距5276.8974, 斜率0.9345, 相关性0.8761
NOTICE: 真实数据95563, 预测数据124211, 本次预测偏差%29.9800
NOTICE: 样本数量339, 截距10611.8990, 斜率0.9248, 相关性0.9273
NOTICE: 真实数据127277, 预测数据132503, 本次预测偏差%4.1100
NOTICE: 样本数量339, 截距9346.7583, 斜率0.9398, 相关性0.9270
NOTICE: 真实数据131802, 预测数据141158, 本次预测偏差%7.1000
NOTICE: 样本数量354, 截距45602.8301, 斜率0.6964, 相关性0.9378
NOTICE: 真实数据140259, 预测数据142531, 本次预测偏差%1.6200
NOTICE: 样本数量354, 截距22118.2940, 斜率0.8984, 相关性0.9995
NOTICE: 真实数据139179, 预测数据139044, 本次预测偏差%0.1000
NOTICE: 样本数量339, 截距7066.6202, 斜率0.9646, 相关性0.9085
NOTICE: 真实数据130151, 预测数据123330, 本次预测偏差%5.2400
NOTICE: 样本数量352, 截距788258.5127, 斜率-6.1054, 相关性0.9259
NOTICE: 真实数据120531, 预测数据120243, 本次预测偏差%0.2400
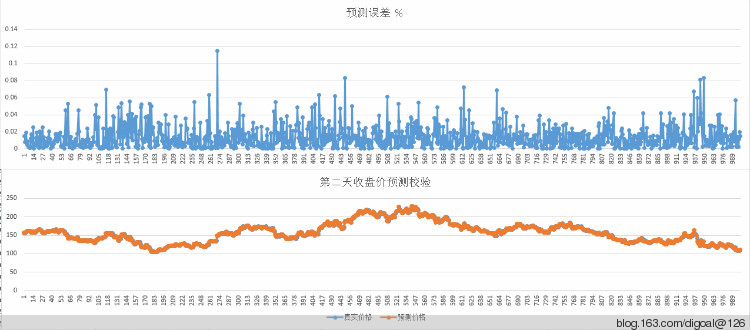
check_predict
————————
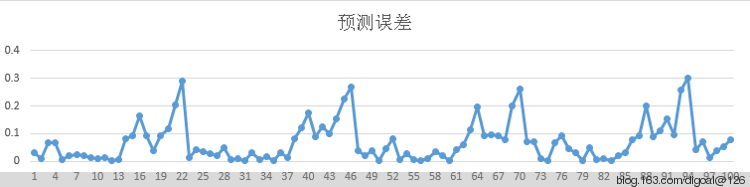
(165320,170611,0.0320)
(167663,165922,0.0104)
(161071,150145,0.0678)
(145570,136026,0.0656)
(133155,133953,0.0060)
(133962,134241,0.0021)
(130484,127596,0.0221)
(126182,123864,0.0184)
(122998,124578,0.0128)
(125052,125119,0.0005)
(123000,121572,0.0116)
(119991,118710,0.0107)
(116182,118363,0.0188)
(116887,116082,0.0069)
(108562,98517,0.0925)
(99168,82725,0.1658)
(82505,74942,0.0917)
(73450,72804,0.0088)
(75681,76143,0.0061)
(82509,82187,0.0039)
(92670,111447,0.2026)
(112865,145539,0.2895)
(148731,150848,0.0142)
(149961,156169,0.0414)
(155748,161289,0.0356)
(160430,155939,0.0280)
(153344,150240,0.0202)
(147997,140772,0.0488)
(138023,137013,0.0073)
(136535,135075,0.0107)
(133978,133909,0.0005)
(132634,136891,0.0321)
(136998,137674,0.0049)
(136303,136431,0.0009)
(130987,130817,0.0013)
(127722,129731,0.0157)
(126303,124949,0.0107)
(117218,117405,0.0016)
(109160,110726,0.0143)
(96823,97097,0.0028)
(79716,72776,0.0871)
(72658,69530,0.0431)
(71739,71377,0.0051)
(77243,76786,0.0059)
(89412,109386,0.2234)
(110972,112269,0.0117)
(144014,149237,0.0363)
(148483,151688,0.0216)
(150405,156324,0.0394)
(154850,155607,0.0049)
(151244,144638,0.0437)
(141118,129415,0.0829)
(126106,125617,0.0039)
(124896,128489,0.0288)
(129061,128477,0.0045)
(127849,128208,0.0028)
(127715,129117,0.0110)
(124554,124206,0.0028)
(117397,117404,0.0001)
(112693,111435,0.0112)
(108804,108821,0.0002)
(105623,105973,0.0033)
(100474,89115,0.1131)
(89591,72087,0.1954)
(71422,64918,0.0911)
(64616,64377,0.0037)
(66389,65428,0.0145)
(72238,72772,0.0074)
(85644,102774,0.2000)
(104207,107341,0.0301)
(134716,144319,0.0713)
(143484,153571,0.0703)
(151426,150648,0.0051)
(147628,148068,0.0030)
(142781,143858,0.0075)
(127852,116232,0.0909)
(113022,107993,0.0445)
(105932,109352,0.0323)
(110807,111147,0.0031)
(112531,107192,0.0474)
(106011,105444,0.0054)
(105170,104365,0.0076)
(103554,103401,0.0015)
(102706,102719,0.0001)
(101460,101473,0.0001)
(98505,97660,0.0086)
(91734,83227,0.0927)
(83453,66847,0.1990)
(65904,59957,0.0902)
(59911,58046,0.0311)
(60677,57848,0.0466)
(62350,62309,0.0007)
(75224,94495,0.2562)
(95563,124211,0.2998)
(127277,132503,0.0411)
(131802,141158,0.0710)
(140259,142531,0.0162)
(139179,139044,0.0010)
(130151,123330,0.0524)
(120531,120243,0.0024)
(100 rows)