http://www.analyticsvidhya.com/blog/2015/09/random-forest-algorithm-multiple-challenges/
Random Forest models have risen significantly in their popularity – and for some real good reasons. They can be applied quickly to any data science problems to get first set of benchmark results. They are incredibly powerful and can be implemented quickly out of the box.
Please note that I am saying first set of results and not all results. Because they have a few limitations as well. In this article, I’ll introduce you to the most interesting aspects of applying Random Forest in your predictive models.
Table of Contents
- History of Random Forest
- What is Random Forest?
- How to implement Random Forest in Python and R?
- How does it work?
- Pros and Cons associated with Random Forest
- How to tune Parameters of Random Forest?
- Practice Problem
History of Random Forest
The history began way back in 1980s. This algorithm was a result of incessant team work by Leo Breiman, Adele Cutler, Ho Tin Kam, Dietterich, Amit and Geman. Each of them played a significant role in early development of random forest. The algorithm for actuating a random forest was developed by Leo Breiman and Adele Cutler. This algorithm is register in their (Leo and Adele) trademark. Amit, Gemen, Ho Tim Kam, independently introduced the idea of random selection of features and using Breiman’s ‘Bagging’ idea constructed this collection of decision trees with controlled variance. Later, Deitterich introduced the idea of random node optimization.
What is Random Forest?
Random Forest is a versatile machine learning method capable of performing both regression and classification tasks. It also undertakes dimensional reduction methods, treats missing values, outlier values and other essentialsteps of data exploration, and does a fairly good job. It is a type of ensemble learning method, where a group of weak models combine to form a powerful model.
In Random Forest, we grow multiple trees as opposed to a single tree in CART model (see comparison between CART and Random Forest here, part1 and part2). To classify a new object based on attributes, each tree gives a classification and we say the tree “votes” for that class. The forest chooses the classification having the most votes (over all the trees in the forest) and in case of regression, it takes the average of outputs by different trees.
Python & R implementation:
Random forests have commonly known implementations in R packages and Python scikit-learn. Let’s look at the code of loading random forest model in R and Python below:
Python
#Import Library from sklearn.ensemble import RandomForestClassifier #use RandomForestRegressor for regression problem #Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset # Create Random Forest object model= RandomForestClassifier(n_estimators=1000) # Train the model using the training sets and check score model.fit(X, y) #Predict Output predicted= model.predict(x_test)
R Code
library(randomForest) x <- cbind(x_train,y_train) # Fitting model fit <- randomForest(Species ~ ., x,ntree=500) summary(fit) #Predict Output predicted= predict(fit,x_test)
Now that you know how to run random forest (I bet, that wasn’t difficult), let’s understand how random forest algorithm works?
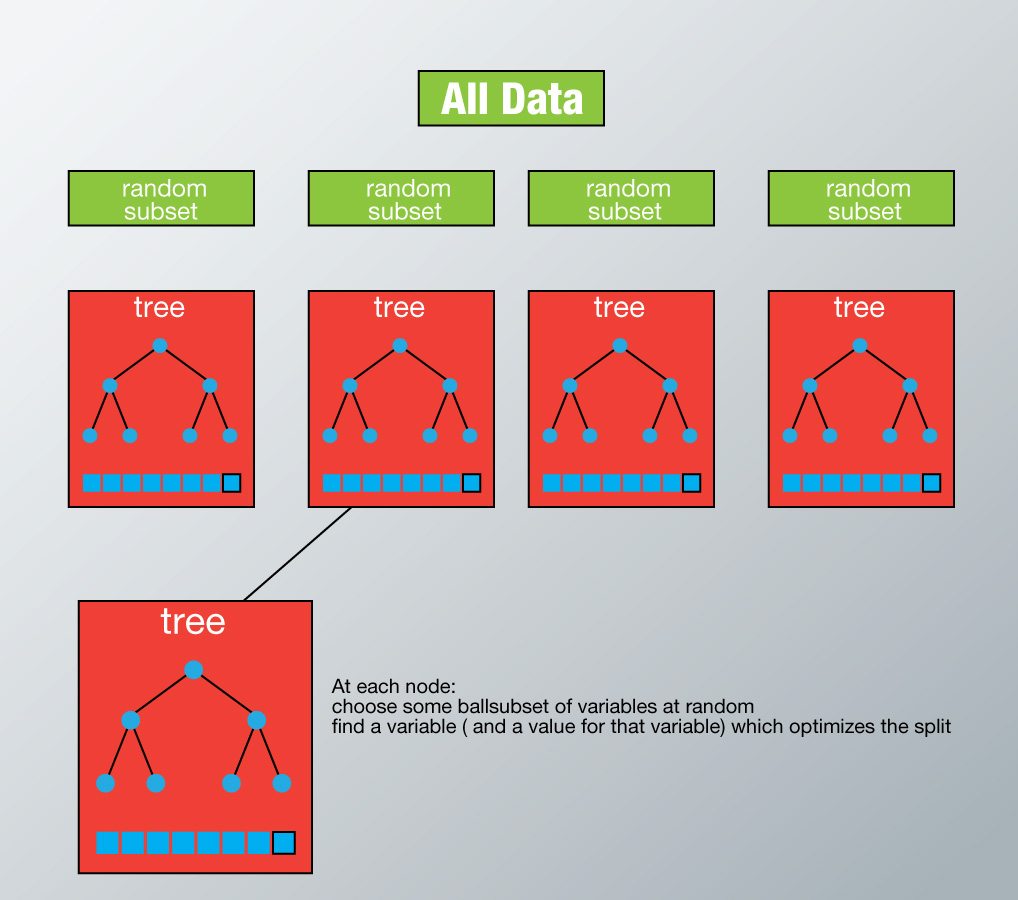
How Random Forest algorithm works?
In Random Forest, each tree is planted & grown as follows:
- Assume number of cases in the training set is N. Then, sample of these N cases is taken at random but with replacement. This sample will be the training set for growing the tree.
- If there are M input variables, a number m<M is specified such that at each node, m variables are selected at random out of the M. The best split on these m is used to split the node. The value of m is held constant while we grow the forest.
- Each tree is grown to the largest extent possible and there is no pruning.
- Predict new data by aggregating the predictions of the ntree trees (i.e., majority votes for classification, average for regression).
To understand more in detail about this algorithm using a case study, please read this article “Introduction to Random forest – Simplified“.
Pros and Cons of Random Forest
Pros:
- As I mentioned earlier, this algorithm can solve both type of problems i.e. classification and regression and does a decent estimation at both fronts.
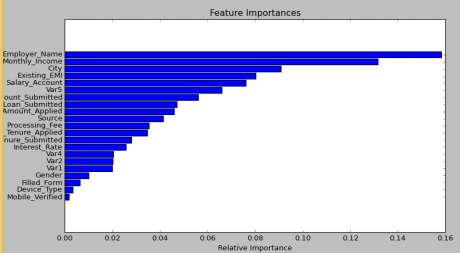
- One of benefits of Random forest which excites me most is, the power of handle large data set with higher dimensionality. It can handle thousands of input variables and identify most significant variables so it is considered as one of the dimensionality reduction methods. Further, the model outputs Importance of variable, which can be a very handy feature. Look at the below image of variable importance from currently Live Hackathon 3.x.

- It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing.
- It has methods for balancing errors in datasets where classes are imbalanced.
- The capabilities of the above can be extended to unlabeled data, leading to unsupervised clustering, data views and outlier detection.
- Random Forest involves sampling of the input data with replacement called as bootstrap sampling. Here one third of the data is not used for training and can be used to testing. These are called the out of bag samples. Error estimated on these out of bag samples is known as out of bag error. Study of error estimates by Out of bag, gives evidence to show that the out-of-bag estimate is as accurate as using a test set of the same size as the training set. Therefore, using the out-of-bag error estimate removes the need for a set aside test set.

Cons:
- It surely does a good job at classification but not as good as for regression problem as it does not give continuous output. In case of regression, it doesn’t predict beyond the range in the training data, and that they may over-fit data sets that are particularly noisy.
- Random Forest can feel like a black box approach for statistical modelers – you have very little control on what the model does. You can at best – try different parameters and random seeds!
How to Tune Parameters of Random Forest?
Till now, we have looked at the basic random forest model, where we have used the default values of various parameters except n_estimators=1000. Here we will look at the different parameters, its importance and methods to tune. Below is the syntax of Random Forest model in python scikit-learn.
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None,bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
Follow definition of these metrics here.

These parameters play a vital role in adjusting the accuracy of your random forest model. The intelligent use of these metrics improve the power of model significantly. To understand this aspect in more detail, you can refer this article “Tuning parameters of random forest model“.
Practice Problem
In currently Live, Hackathon 3.x – Predict customer worth for Happy Customer Bank, a binary classification problem is given. This problem has 24 input variables( mix of both categorical and continuous variables). Input variables have missing values, outlier values and unbalanced distribution of numerical variables.
After we’ve finished hypothesis generation and basic data exploration, my next step is to use a classification algorithm. I can choose from various classification algorithms like Logistic, SVM, Random Forest and many others. But here, I’ll compare the performance of logistic regression and random forest model.
For initial model, I have not done any feature engineering and data cleaning. Let’s look at the output of these three models and their relative performance:
Step-1: Initial steps of importing libraries and reading data:
import pandas as pd import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn import preprocessing from sklearn.metrics import roc_curve, auc
number = preprocessing.LabelEncoder()
train=pd.read_csv('C:/Users/Analytics Vidhya/Desktop/Hackathon3.x/Final_Files/Train.csv')
Step-2: Convert categorical variable to numpy arrays and fill NaN values to zero.
def convert(data): number = preprocessing.LabelEncoder() data['Gender'] = number.fit_transform(data.Gender) data['City'] = number.fit_transform(data.City) data['Salary_Account'] = number.fit_transform(data.Salary_Account) data['Employer_Name'] = number.fit_transform(data.Employer_Name) data['Mobile_Verified'] = number.fit_transform(data.Mobile_Verified) data['Var1'] = number.fit_transform(data.Var1) data['Filled_Form'] = number.fit_transform(data.Filled_Form) data['Device_Type'] = number.fit_transform(data.Device_Type) data['Var2'] = number.fit_transform(data.Var2) data['Source'] = number.fit_transform(data.Source) data=data.fillna(0) return data train=convert(train)
Step-3: Split the data set to train and validate
train['is_train'] = np.random.uniform(0, 1, len(train)) <= .75 train, validate = train[train['is_train']==True], train[train['is_train']==False]
Step-4: Build Logistic and look at the roc_auc (evaluation metric of this challenge)
lg = LogisticRegression() lg.fit(x_train, y_train)
Disbursed_lg=lg.predict_proba(x_validate)
fpr, tpr, _ = roc_curve(y_validate, Disbursed_lg[:,1]) roc_auc = auc(fpr, tpr) print roc_auc
Output: 0.535441187235
Step-5: Build Random and look at the roc_auc
rf = RandomForestClassifier() rf.fit(x_train, y_train) disbursed = rf.predict_proba(x_validate) fpr, tpr, _ = roc_curve(y_validate, disbursed[:,1]) roc_auc = auc(fpr, tpr) print roc_auc
Output: 0.614586623764
Step-6: Build Random Forest with n_estimtors=1000 and look at the roc_auc
rf = RandomForestClassifier(n_estimators=1000) rf.fit(x_train, y_train) disbursed = rf.predict_proba(x_validate) fpr, tpr, _ = roc_curve(y_validate, disbursed[:,1]) roc_auc = auc(fpr, tpr) print roc_auc
Output: 0.824606785363
By looking at above models, it is clear that random forest with tuned parameter has better results than other two. You can further improve the model power by tuning other parameters also. Above, we have not done any feature engineering, you can populate featured variable(s), treat missing or outlier values, combine multiple models and generate a powerful ensemble methods. This competition is Live till 11th September 2015, therefore, I can’t discuss more as it will violate T&C of competition.
End Note
In this article, we looked at one of most common machine learning algorithm Random Forest followed by its pros & cons, method to tune parameters and explained & compared it using a practice problem. I would suggest you to use random forest and analyse the power of this model by tuning the parameters.
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/powerful-guide-to-learn-random-forest-with-codes-in-r-python/
注意:本文归作者所有,未经作者允许,不得转载

