from http://blog.csdn.net/epluguo/article/details/27800625
Apriori算法是数据挖掘中一种挖掘关联规则的频繁项集算法。其核心是基于两阶段频集思想的递推算法。
先来了解下关联规则挖掘:
发现事务数据库,关系数据, 或其它信息库中项或数据对象集合间的频繁模式。关联,相关,或因果关系结构。
频繁模式:在数据库中频繁出现的模式(项集, 序列, 等)。
动机是发现数据中的规律性。
如:
购物篮分析:哪些产品更经常一起购买? 啤酒 和 尿布?!
购买了PC后, 哪些将相继购买?
什么类型的 DNA 对新药敏感?
我们能自动地对Web文档分类吗?
再来看看几个概念:
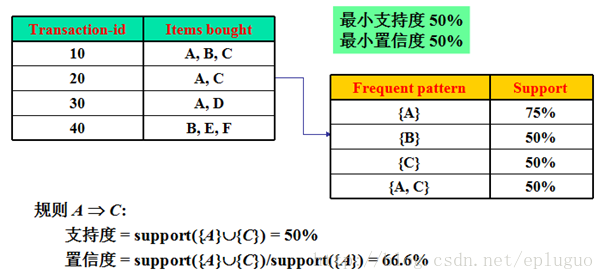
支持度:s (support),事务包含 X∪Y 的概率。
置信度:c (confidence),事务含 X 也包含 Y 的条件概率p(Y|X)。
频繁项集: I,项集I的相对支持度满足预定义的最小支持度阈值
Apriori算法:
Apriori算法的核心是使用候选项集寻找频繁项集。Apriori使用一种称为逐层搜索的迭代方法,k-项集用于搜索(k+1)-项集。首先,找出所有频繁1-项集L1,然后用L1寻找L2,用L2寻找L3,如此,直至不能找到频繁k-项集为止。
Apriori性质:
频繁项集的所有非空子集肯定也是频繁的。
如:
每个包含 {beer, diaper, nuts}的事务 也包含 {beer, diaper}
如果 {beer, diaper, nuts} 是频繁的, {beer, diaper}也是
转换一下思维,如果一个子集是非频繁的,那么它的超集也一定是非频繁的。这在Apriori算法里面很重要。
利用Apriori性质,我们在使用频繁(k-1)-项集L(k-1)寻找频繁k-项集L(k)时分两个过程:连接步和剪枝步。
连接步:
L(k-1)与其自身进行连接,产生候选项集C(k)。L(k-1)中某个元素与其中另一个元素可以执行连接操作的前提是它们中游(k-2)个项是相同的。也就是只有一个项是不同的。
如:项集{I1,I2}与{I1,I5}连接之后产生的项集是{I1,I2,I5},而项集{I1,I2}与{I3,I4}不能进行连接操作。
剪枝步:
候选集C(k)中的元素可以是频繁项集,也可以不是。但所有的频繁k-项集一定包含在C(k)中,所以,C(k)是L(k)的超集。扫描事物集D,计算C(k)中每个候选项出现的次数,出现次数大于等于最小支持度与事务集D中事务总数乘积的项集便是频繁项集(这里的最小支持度指的是概率,实际中我们经常直接将最小支持度看成乘积后的结果),如此便可确定频繁k-项集L(k)了。
但是,由于C(k)很大,所以计算量也会很大。为此,需要进行剪枝。即压缩C(k),删除其中肯定不是频繁项集的元素,依据就是前面提到的Apriori性质:如果一个子集是非频繁的,那么它的超集也一定是非频繁的。这在Apriori算法里面很重要。如此,如果一个候选(k-1)-子集不在L(k-1)中,那么该候选k-项集也不可能是频繁的,可以直接从C(k)中删除。
这里看一个例子就可以理解了:
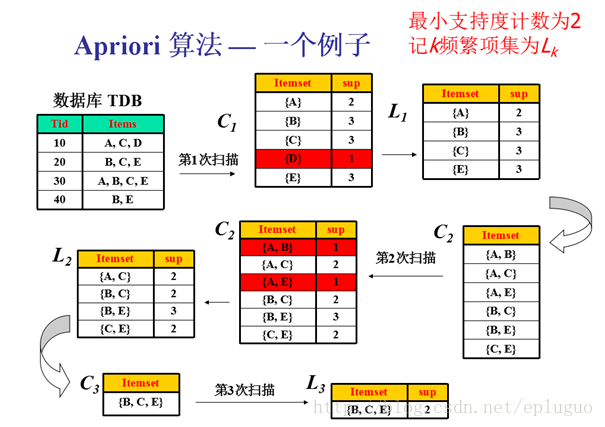
所以,满足条件的所有频繁项集有{A}、{B}、{C}、{E}、{A、C}、{B、C}、{B、E}、{C、E}、{B、C、E}
更详细内容可以参考 使用Apriori算法和FP-growth算法进行关联分析
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e3%80%90%e5%8d%81%e5%a4%a7%e7%bb%8f%e5%85%b8%e6%95%b0%e6%8d%ae%e6%8c%96%e6%8e%98%e7%ae%97%e6%b3%95%e3%80%91apriori/
注意:本文归作者所有,未经作者允许,不得转载

