来自 http://www.klshu.com/1202.html
关联规则挖掘是一种流行的数据挖掘方法,在R语言中为扩展包arules。然而,挖掘关联规则往往导致非常多的规则,使分析师需要通过查询所有的规则才能发现有趣的规则。通过手动筛选大量的规则集是费时费力。在本文中,我们基于探索关联规则的R扩展包arulesViz,提出几个已知的和新颖的可视化技术。
1、简介
算法步骤这里不做详细介绍,下面是几个重要的变量的定义:
Supp(X=>Y) = P(X) Conf(X=>Y) = P(Y|X) Lift(X=>Y) = CONF(X=>Y)/SUPP(Y) = P(X and Y)/(P(X)P(Y))
2、数据准备和arulesViz的统一接口
> library("arulesViz")
> data("Groceries")
> summary(Groceries)
> rules <- apriori(Groceries, parameter = list(support = 0.001, confidence = 0.5)) > rules set of 5668 rules
结果共找出了5668条规则。按照Lift降序排,最大的三条规则如下:
> inspect(head(sort(rules, by = "lift"), 3))
lhs rhs support confidence lift
1 {Instant food products,
soda} => {hamburger meat} 0.001220132 0.6315789 18.99565
2 {soda,
popcorn} => {salty snack} 0.001220132 0.6315789 16.69779
3 {flour,
baking powder} => {sugar} 0.001016777 0.5555556 16.40807
3、散点图
直接用plot画出散点图
> plot(rules)
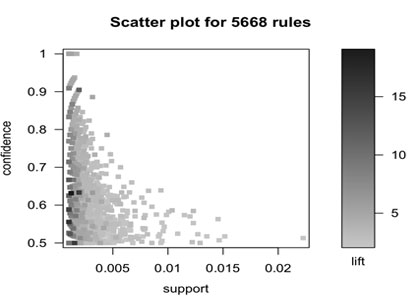
图1
从图1可以看到高lift对应低supp。另外一些科学家认为最有意思的规则在supp/conf的边沿上,如t图1所示。
> head(quality(rules)) support confidence lift 1 0.001118454 0.7333333 2.870009 2 0.001220132 0.5217391 2.836542 3 0.001321810 0.5909091 2.312611 4 0.001321810 0.5652174 2.212062 5 0.001321810 0.5200000 2.035097 6 0.003660397 0.6428571 2.515917
如果我们想个性化plot图中的坐标的特征,将颜色表示conf,lift为纵标轴,如下所示。
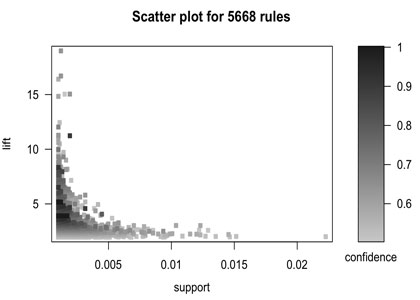
图2
> plot(rules, measure = c("support", "lift"), shading = "confidence")
图2中的y轴是lift,这里可以比较清晰地看出很多的规则都有高lift。

图3
> plot(rules, shading = "order", control = list(main = "Two-key plot"))
图3中,supp为x轴,conf为y轴,颜色的深浅表示“order”,例如规则里频繁项的个数。从图中可以看出,order和supp有着很强的负相关性。这在关联规则中也是熟知的。
散点图方法提供了互动功能的选择和缩放,可以使用interactive=TRUE来实现。
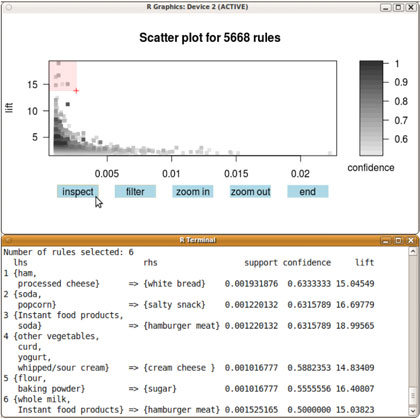
图4
> sel <- plot(rules, measure = c("support", "lift"), shading = "confidence",
+ interactive = TRUE)
图4中选择了lift较高的几个点,并且使用inspect按钮,在终端的界面上便显示了这些规则。
4、基于分组矩阵的可视化
基于矩阵的可视化中只能有效处理规则数较少的可视化,因为大的规则集通常也有大量LHS/RHS(左边的集合/右边的集合)的限制。在这里,我们引入一个新的可视化技术,通过使用聚类方法将规则分组,可提高基于矩阵的可视化。
一个直接的方法来聚类频繁项集,便是定义两个项集(Xi和Xj )之间的距离。一个比较好的选择是使用Jaccard distance。
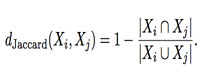
有几种方法,以聚类关联规则和频繁项集解决高维和数据稀疏问题。有的建议要观察包含在频繁项集中的项的交易的个数。然而,他对从相同频繁项集产生的聚类规则有着很强的偏向。由频繁项集的定义,一个频繁项集的两个子集都将适用于许多常见的交易。这种偏见会导致大多只是从集合关联规则重新发现已知的频繁项集的结构。
为了使分组速度加快并且有效地分为K类,这里使用了K-means聚类方法。这个思路是LHS和RHS统计上是相似的则被归为一类。相对于频繁项集的其他聚类结果,这种方法得出含有替代品的分组(如“黄油”和“人造黄油”),这些通常是很少一起购买的,但因为他们有着相似的RHS。相同的分组方法也作用于后项。然而,由于挖掘的规则只得出一个RHS的项集,因此这里没有组合爆炸的问题,但这样的分组通常也是不需要的。
在可视化图中,LHS是列,RHS是行,lift是圈的颜色深浅,圈的大小事聚合后的支持度。LHS的个数和分组中最重要(频繁)项集显示在列的标签里。lift从左上角到右下角逐渐减少。
> plot(rules, method = "grouped")
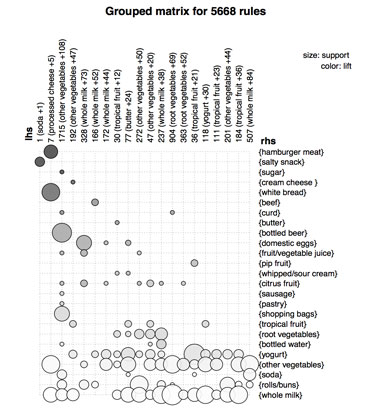
图5
lift从左上角到右下角的颜色逐渐变小。这里有3条规则包含“Instant food products ”,RHS超过2个其他项集的是“hamburger meat”。
组的个数默认是20个,我们也可以通过添加control = list(k = 50)来改变组的个数。
5、基于图的可视化
基于图形的可视化技术,利用顶点代表项或者项目集,和边表示规则中关系的关联规则。强度通常使用颜色或者边的宽度来表示。
基于图形的可视化提供了一个规则非常明确的展示,但他们规则越过则往往容易变得混乱,因此是比较可行的是使用非常小的规则集。对于下面的图,我们选择了10条具有高lift的规则。
> subrules2 <- head(sort(rules, by = "lift"), 10)
arulesViz包含了一些基于图形的可视化展示,使用Rgraphviz扩展包的一些接口。默认的版本点代表项目集,表代表规则项集之间的有向边 。
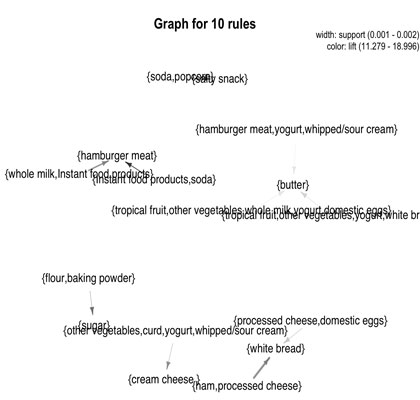
图6
> plot(subrules2, method = "graph")

图7
> plot(subrules2, method = "graph", control = list(type = "items"))
图7着重于规则是如何由个别项目组成的,并显示哪些规则共享的项目。arulesViz的内置基于徒刑的可视化只对规则数较少时有效。探索大量规则的可视化,需要先进的图形放大,过滤,分组和着色节点的交互功能。
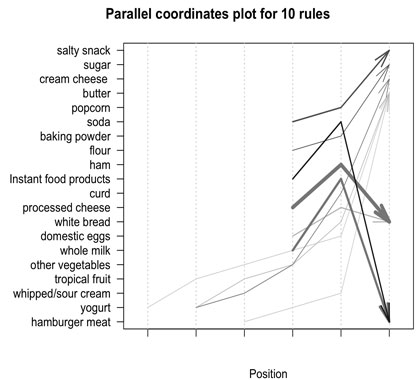
7、平行坐标图(Parallel coordinates plot )
平行坐标图将多维数据共享,使得每个维度上分别显示在x轴和y轴。每个数据点是由连接的值对于每个维度中的线表示。每个数据点由连接每个维度的线表示。
8、小节
参考文件:《Visualizing Association Rules-Introduction to the R-extension Package arulesViz》
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/r%e8%af%ad%e8%a8%80%e5%85%b3%e8%81%94%e8%a7%84%e5%88%99%e5%8f%af%e8%a7%86%e5%8c%96%ef%bc%9a%e6%89%a9%e5%b1%95%e5%8c%85arulesviz%e7%9a%84%e4%bb%8b%e7%bb%8d/
注意:本文归作者所有,未经作者允许,不得转载

