一、自定义词库
针对一些特殊的词语在分词的时候也需要能够识别。
例如:公司产品的名称或者网络上新流行的词语
假设我们公司开发了一款新产品,命名为:数据大脑,我们希望ES在分词的时候能够把这个产品名称直接识别成一个词语。
现在使用ik分词器测试一下分词效果:
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/test/_analyze?pretty' -d '{"text":"数据大脑","tokenizer":"ik_max_word"}'
{
"tokens" : [
{
"token" : "数据",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "大脑",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
结果发现ik分词器会把数据大脑分为 数据 和 大脑这两个单词。
因为这个词语是我们自己造出来的,并不是通用的词语,所以ik分词器识别不出来也属于正常。
想要让IK分词器识别出来,就需要自定义词库了,也就是把我们自己造的词语添加到词库里面,这样在分词的时候就可以识别到了。
下面演示一下如何在IK中自定义词库:
1:首先在ik插件对应的配置文件目录下创建一个自定义词库文件my.dic
首先在bigdata01节点上操作。
切换到es用户,进入到ik插件对应的配置文件目录
[root@bigdata01 ~]# su es
[es@bigdata01 root]$ cd /data/soft/elasticsearch-7.13.4
[es@bigdata01 elasticsearch-7.13.4]$ cd config
[es@bigdata01 config]$ cd analysis-ik
[es@bigdata01 analysis-ik]$ ll
total 8260
-rwxrwxrwx. 1 root root 5225922 Feb 27 20:57 extra_main.dic
-rwxrwxrwx. 1 root root 63188 Feb 27 20:57 extra_single_word.dic
-rwxrwxrwx. 1 root root 63188 Feb 27 20:57 extra_single_word_full.dic
-rwxrwxrwx. 1 root root 10855 Feb 27 20:57 extra_single_word_low_freq.dic
-rwxrwxrwx. 1 root root 156 Feb 27 20:57 extra_stopword.dic
-rwxrwxrwx. 1 root root 625 Feb 27 20:57 IKAnalyzer.cfg.xml
-rwxrwxrwx. 1 root root 3058510 Feb 27 20:57 main.dic
-rwxrwxrwx. 1 root root 123 Feb 27 20:57 preposition.dic
-rwxrwxrwx. 1 root root 1824 Feb 27 20:57 quantifier.dic
-rwxrwxrwx. 1 root root 171 Feb 27 21:42 stopword.dic
-rwxrwxrwx. 1 root root 192 Feb 27 20:57 suffix.dic
-rwxrwxrwx. 1 root root 752 Feb 27 20:57 surname.dic
创建自定义词库文件my.dic
直接在文件中添加词语即可,每一个词语一行。
[es@bigdata01 analysis-ik]$ vi my.dic
数据大脑注意:这个my.dic词库文件可以在Linux中直接使用vi命令创建,或者在Windows中创建之后上传到这里。
如果是在Linux中直接使用vi命令创建,可以直接使用。
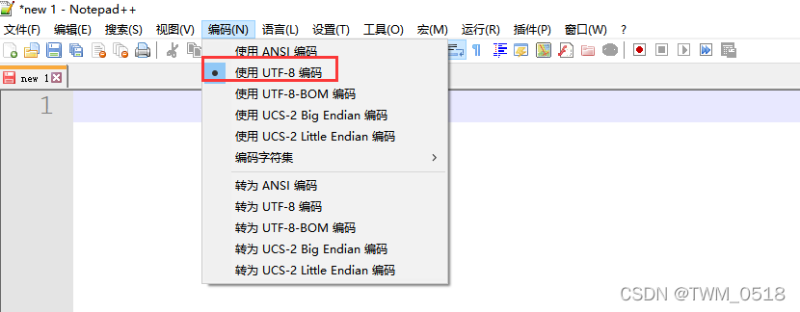
如果是在Windows中创建的,需要注意文件的编码必须是UTF-8 without BOM 格式【UTF-8 无 BOM格式】
以Notepad++为例:新版本的Notepad++里面的文件编码有这么几种,需要选择【使用UTF-8编码】,这个就是UTF-8 without BOM 格式。
2:修改ik的IKAnalyzer.cfg.xml配置文件
进入到ik插件对应的配置文件目录中,修改IKAnalyzer.cfg.xml配置文件
[es@bigdata01 analysis-ik]$ vi IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry>-->
</properties>
注意:需要把my.dic词库文件添加到key="ext_dict"这个entry中,切记不要随意新增entry,随意新增的entry是不被IK识别的,并且entry的名称也不能乱改,否则也不会识别。
如果需要指定多个自定义词库文件的话需要使用分号;隔开。
例如:my.dic;your.dic
3:将修改好的IK配置文件复制到集群中的所有节点中
注意:如果是多个节点的ES集群,一定要把配置远程拷贝到其他节点。
先从bigdata01上将my.dic拷贝到bigdata02和bigdata03
[es@bigdata01 analysis-ik]$ scp -rq my.dic bigdata02:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
The authenticity of host 'bigdata02 (192.168.182.101)' can't be established.
ECDSA key fingerprint is SHA256:SnzVynyweeRcPIorakoDQRxFhugZp6PNIPV3agX/bZM.
ECDSA key fingerprint is MD5:f6:1a:48:78:64:77:89:52:c4:ad:63:82:a5:d5:57:92.
Are you sure you want to continue connecting (yes/no)? yes
es@bigdata02's password:
[es@bigdata01 analysis-ik]$ scp -rq my.dic bigdata03:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
The authenticity of host 'bigdata03 (192.168.182.102)' can't be established.
ECDSA key fingerprint is SHA256:SnzVynyweeRcPIorakoDQRxFhugZp6PNIPV3agX/bZM.
ECDSA key fingerprint is MD5:f6:1a:48:78:64:77:89:52:c4:ad:63:82:a5:d5:57:92.
Are you sure you want to continue connecting (yes/no)? yes
es@bigdata03's password:
注意:因为现在使用的是普通用户es,所以在使用scp的时候需要指定目标机器的用户名(如果是root可以省略不写),并且还需要手工输入密码,因为之前是基于root用户做的免密码登录。
再从bigdata01上将IKAnalyzer.cfg.xml拷贝到bigdata02和bigdata03
[es@bigdata01 analysis-ik]$ scp -rq IKAnalyzer.cfg.xml bigdata02:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
es@bigdata02's password:
[es@bigdata01 analysis-ik]$ scp -rq IKAnalyzer.cfg.xml bigdata03:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
es@bigdata03's password:
注意:如果后期想增加自定义停用词库,也需要按照这个思路进行添加,只不过停用词库需要配置到 key="ext_stopwords"这个entry中。
4:重启ES验证一下自定义词库的分词效果
先停止ES集群。
[es@bigdata01 ~]$ jps
1892 Jps
1693 Elasticsearch
[es@bigdata01 ~]$ kill 1693
[es@bigdata02 ~]$ jps
1873 Jps
1725 Elasticsearch
[es@bigdata02 ~]$ kill 1725
[es@bigdata02 ~]$ jps
1844 Jps
1694 Elasticsearch
[es@bigdata02 ~]$ kill 1694
再启动ES集群。
[es@bigdata01 ~]$ cd /data/soft/elasticsearch-7.13.4/
[es@bigdata01 elasticsearch-7.13.4]$ bin/elasticsearch -d
[es@bigdata02 ~]$ cd /data/soft/elasticsearch-7.13.4/
[es@bigdata02 elasticsearch-7.13.4]$ bin/elasticsearch -d
[es@bigdata03 ~]$ cd /data/soft/elasticsearch-7.13.4/
[es@bigdata03 elasticsearch-7.13.4]$ bin/elasticsearch -d
验证:
[es@bigdata01 elasticsearch-7.13.4]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/test/_analyze?pretty' -d '{"text":"数据大脑","tokenizer":"ik_max_word"}'
{
"tokens" : [
{
"token" : "数据大脑",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "数据",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "大脑",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
}
]
}
现在发现数据大脑这个词语可以被识别出来了,说明自定义词库生效了。
二、热更新词库
针对前面分析的自定义词库,后期只要词库内容发生了变动,就需要重启ES才能生效,在实际工作中,频繁重启ES集群不是一个好办法
所以ES提供了热更新词库的解决方案,在不重启ES集群的情况下识别新增的词语,这样就很方便了,也不会对线上业务产生影响。
下面来演示一下热更新词库的使用:
1:在bigdata04上部署HTTP服务
在这使用tomcat作为Web容器,先下载一个tomcat 8.x版本。
tomcat 8.0.52版本下载地址:
https://archive.apache.org/dist/tomcat/tomcat-8/v8.0.52/bin/apache-tomcat-8.0.52.tar.gz
上传到bigdata04上的/data/soft目录里面,并且解压
[root@bigdata04 soft]# ll apache-tomcat-8.0.52.tar.gz
-rw-r--r--. 1 root root 9435483 Sep 22 2021 apache-tomcat-8.0.52.tar.gz
[root@bigdata04 soft]# tar -zxvf apache-tomcat-8.0.52.tar.gz
tomcat的ROOT项目中创建一个自定义词库文件hot.dic,在文件中输入一行内容:测试
[root@bigdata04 soft]# cd apache-tomcat-8.0.52
[root@bigdata04 apache-tomcat-8.0.52]# cd webapps/ROOT/
[root@bigdata04 ROOT]# vi hot.dic
测试
启动Tomcat
[root@bigdata04 ROOT]# cd /data/soft/apache-tomcat-8.0.52
[root@bigdata04 apache-tomcat-8.0.52]# bin/startup.sh
Using CATALINA_BASE: /data/soft/apache-tomcat-8.0.52
Using CATALINA_HOME: /data/soft/apache-tomcat-8.0.52
Using CATALINA_TMPDIR: /data/soft/apache-tomcat-8.0.52/temp
Using JRE_HOME: /data/soft/jdk1.8
Using CLASSPATH: /data/soft/apache-tomcat-8.0.52/bin/bootstrap.jar:/data/soft/apache-tomcat-8.0.52/bin/tomcat-juli.jar
Tomcat started.
验证一下hot.dic文件是否可以通过浏览器访问:
注意:页面会显示乱码,这是正常的,不用处理即可。
2:修改ES集群中ik插件的IKAnalyzer.cfg.xml配置文件
在bigdata01上修改。
在key="remote_ext_dict"这个entry中添加hot.dic的远程访问链接
http://bigdata04:8080/hot.dic
注意:一定要记得去掉key="remote_ext_dict"这个entry外面的注释,否则添加的内容是不生效的。
[es@bigdata01 analysis-ik]$ vi IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://bigdata04:8080/hot.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry>-->
</properties>
3:将修改好的IK配置文件复制到集群中的所有节点中
[es@bigdata01 analysis-ik]$ scp -rq IKAnalyzer.cfg.xml bigdata02:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
es@bigdata02's password:
[es@bigdata01 analysis-ik]$ scp -rq IKAnalyzer.cfg.xml bigdata03:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
es@bigdata03's password:
4:重启ES集群验证效果。
因为修改了配置,所以需要重启集群。
先停止ES集群。
[es@bigdata01 ~]$ jps
1892 Jps
1693 Elasticsearch
[es@bigdata01 ~]$ kill 1693
[es@bigdata02 ~]$ jps
1873 Jps
1725 Elasticsearch
[es@bigdata02 ~]$ kill 1725
[es@bigdata02 ~]$ jps
1844 Jps
1694 Elasticsearch
[es@bigdata02 ~]$ kill 1694
再启动ES集群。
[es@bigdata01 ~]$ cd /data/soft/elasticsearch-7.13.4/
[es@bigdata01 elasticsearch-7.13.4]$ bin/elasticsearch -d
[es@bigdata02 ~]$ cd /data/soft/elasticsearch-7.13.4/
[es@bigdata02 elasticsearch-7.13.4]$ bin/elasticsearch -d
[es@bigdata03 ~]$ cd /data/soft/elasticsearch-7.13.4/
[es@bigdata03 elasticsearch-7.13.4]$ bin/elasticsearch -d
验证:
对北京雾霾这个词语进行分词
[es@bigdata01 elasticsearch-7.13.4]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/test/_analyze?pretty' -d '{"text":"北京雾霾","tokenizer":"ik_max_word"}'
{
"tokens" : [
{
"token" : "北京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "雾",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "霾",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
}
]
}
正常情况下 北京雾霾 会被分被拆分为多个词语,但是在这我希望ES能够把 北京雾霾 认为是一个完整的词语,又不希望重启ES。
这样就可以修改前面配置的hot.dic文件,在里面增加一个词语:北京雾霾
在bigdata04里面操作,此时可以在Linux中直接编辑文件。
[root@bigdata04 apache-tomcat-8.0.52]# cd webapps/ROOT/
[root@bigdata04 ROOT]# vi hot.dic
测试
北京雾霾
文件保存之后,在bigdata01上查看ES的日志会看到如下日志信息:
[2027-03-09T18:43:12,700][INFO ][o.w.a.d.Dictionary ] [bigdata01] start to reload ik dict.
[2027-03-09T18:43:12,701][INFO ][o.w.a.d.Dictionary ] [bigdata01] try load config from /data/soft/elasticsearch-7.13.4/config/analysis-ik/IKAnalyzer.cfg.xml
[2027-03-09T18:43:12,929][INFO ][o.w.a.d.Dictionary ] [bigdata01] [Dict Loading] /data/soft/elasticsearch-7.13.4/config/analysis-ik/my.dic
[2027-03-09T18:43:12,929][INFO ][o.w.a.d.Dictionary ] [bigdata01] [Dict Loading] http://bigdata04:8080/hot.dic
[2027-03-09T18:43:12,934][INFO ][o.w.a.d.Dictionary ] [bigdata01] 测试
[2027-03-09T18:43:12,935][INFO ][o.w.a.d.Dictionary ] [bigdata01] 北京雾霾
[2027-03-09T18:43:12,935][INFO ][o.w.a.d.Dictionary ] [bigdata01] reload ik dict finished.
再对北京雾霾这个词语进行分词
[es@bigdata01 elasticsearch-7.13.4]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/test/_analyze?pretty' -d '{"text":"北京雾霾","tokenizer":"ik_max_word"}'
{
"tokens" : [
{
"token" : "北京雾霾",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "北京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "雾",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "霾",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 3
}
]
}
此时,发现北京雾霾这个词语就可以完整被切分出来了,到这为止,我们就成功实现了热更新自定义词库的功能。
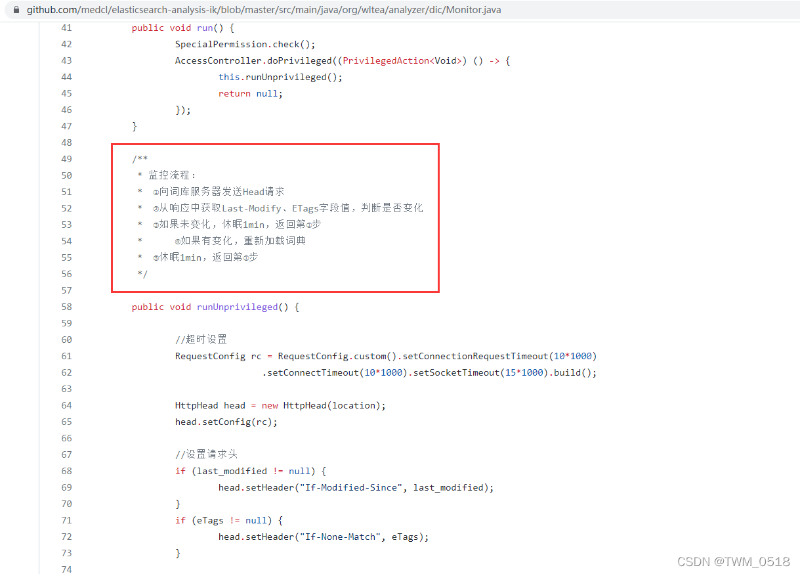
注意:默认情况下,最多一分钟之内就可以识别到新增的词语。
通过查看es-ik插件的源码可以发现
https://github.com/medcl/elasticsearch-analysis-ik/blob/master/src/main/java/org/wltea/analyzer/dic/Monitor.java
注意:本文归作者所有,未经作者允许,不得转载

