1. 引言
个人以为,机器学习是朝着更高的易用性、更低的技术门槛、更敏捷的开发成本的方向去发展,且AutoML或者AutoDL的发展无疑是最好的证明。因此花费一些时间学习了解了AutoML领域的一些知识,并对AutoML中的技术方案进行归纳整理。
众所周知,一个完整的机器学习项目可概括为如下四个步骤。
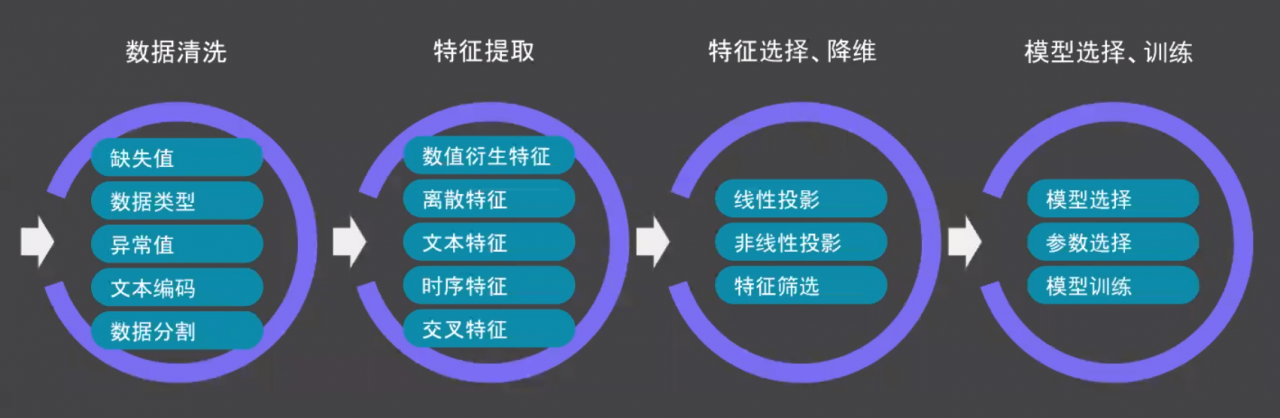

其中,特征工程(提取)往往是决定模型性能的最关键一步。而往往机器学习中最耗时的部分也正是特性工程和超参数调优。因此,许多模型由于时间限制而过早地从实验阶段转移到生产阶段从而导致并不是最优的。
自动化机器学习(AutoML)框架旨在减少算法工程师们的负担,以便于他们可以在特征工程和超参数调优上花更少的时间,而在模型设计上花更多的时间进行尝试。


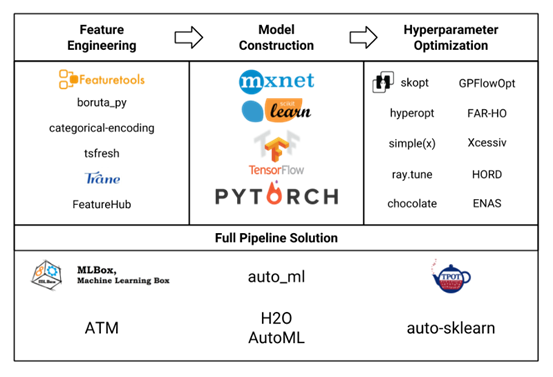
本文将对AutoML中的自动化特征工程模块的现状展开介绍,以下是目前主流的有关AUTOML的开源包。

2. 什么是自动化特征工程?
自动化特征工程旨在通过从数据集中自动创建候选特征,且从中选择若干最佳特征进行训练的一种方式。
3. 自动化特征工程工具包
3.1 Featuretools
Featuretools使用一种称为深度特征合成(Deep Feature Synthesis,DFS)的算法,该算法遍历通过关系数据库的模式描述的关系路径。当DFS遍历这些路径时,它通过应用于数据的操作(包括和、平均值和计数)生成综合特征。例如,对来自给定字段client_id的事务列表应用sum操作,并将这些事务聚合到一个列中。尽管这是一个深度操作,但该算法可以遍历更深层的特征。Featuretools最大的优点是其可靠性和处理信息泄漏的能力,同时可以用来对时间序列数据进行处理。
例子:
假设有三张表,分别为clients、loans、payments。
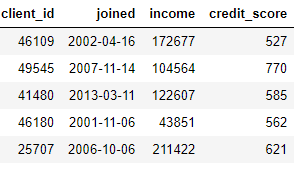
clients :有关信用合作社客户的基本信息表。每个客户端在此数据框中只有一行。

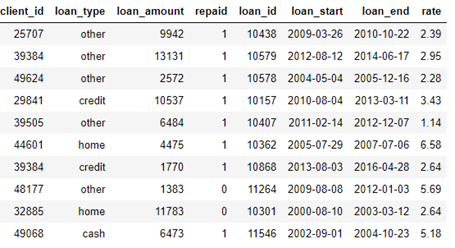
loans:向客户提供的贷款表。每笔贷款在此数据框中只有自己的行,但客户可能有多笔贷款。

payments:贷款偿还表。每笔付款只有一行,但每笔贷款都有多笔付款。
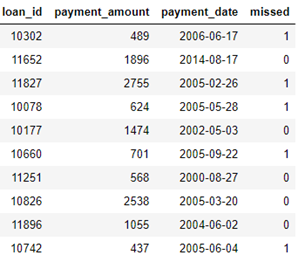

以每个client_id为对象构造特征:
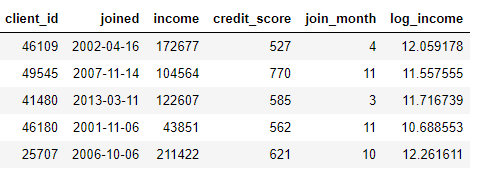
传统的特征工程方案是利用Pandas对所需特征做处理,例如下表中的获取月份、收入值的对数。

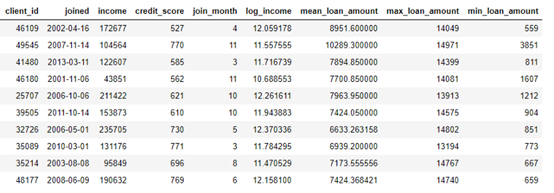
同时,也可以通过与loans表关联获取新的特征(每个client平均贷款额度、最大贷款额度等)。

而Featuretools通过基于一种称为“ 深度特征合成 ”的方法,即通过堆叠多个特征来完成特征工程。
深度特征合成堆叠多个转换和聚合操作(在特征工具的词汇中称为特征基元),以通过分布在许多表中的数据创建特征。
Featuretools有两个主要概念:
- 第一个是entities,它可被视为单个表。
- 第二个是entityset,它是实体(表)的集合,以及用来表示实体之间的关系。
首先,需要创建一个存放所有数据表的空实体集对象:
import featuretools as ft
es = ft.EntitySet(id='clients')现在需要添加实体:每个实体都必须有一个索引,索引是由实体中具有唯一元素值的列构成。也就是说,索引中的每个值必须只出现在表中一次。
es = es.entity_from_dataframe(entity_id='clients', dataframe=clients,
index='client_id', time_index='joined')
es = es.entity_from_dataframe(entity_id='loans', dataframe=loans,
index='loans_id', time_index='joined')而对于没有唯一索引的表:需要传入参数make_index = True并指定索引的名称。
此外,虽然featuretools会自动推断实体中每个列的数据类型,但仍可以通过将列类型的字典传递给参数variable_types来重新定义数据类型。例如对“missed”字段我们定义为类别型变量。
es = es.entity_from_dataframe(entity_id='payments', dataframe=payments,
variable_types={'missed': ft.variable_types.Categorical},
make_index=True, index='payment_id', time_index='payment_date')在执行聚合计算时,要在featuretools中指定表之间的关系时,只需指定将两个表关联在一起的特征字段。clients和loans表通过client_id字段关联,loans和payments通过loan_id字段关联。
创建表之间关系并将其添加到entityset的代码如下所示:
# 'clients'表与loans表关联
r_client_previous = ft.Relationship(es['clients']['client_id'], es['loans']['client_id'])
# 将关系添加到实体集
es = es.add_relationship(r_client_previous)
# loans表与payments表关联
r_payments = ft.Relationship(es['loans']['loan_id'], es['payments']['loan_id'])
# 将关系添加到实体集
es = es.add_relationship(r_payments)在添加实体和形式化关系之后,entityset就完成了。
需要注意,featuretools 是通过以下两种操作进行特征构造:
- Aggregations:分组聚合
- Transformations:列之间计算
在 featuretools 中,可以使用这些原语自行创建新特性,也可以将多个原语叠加在一起。下面是featuretools中的一些功能原语列表:
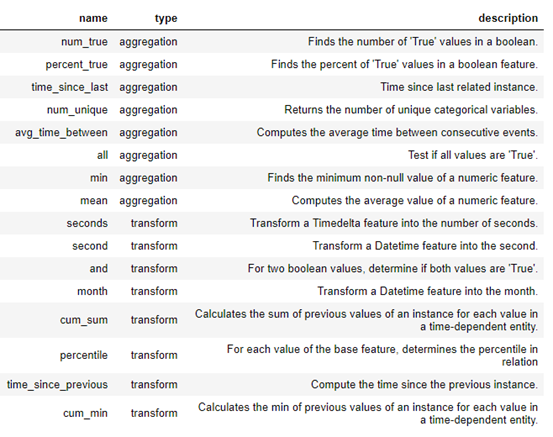

此外,我们也可以定义自定义原语,详见: https://docs.featuretools.com/guides/advanced_custom_primitives.html。
接下来是进行特征构造,这也是自动化特征工程中最重要的一步:
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
agg_primitives=['mean', 'max', 'percent_true', 'last'],
trans_primitives=['years', 'month', 'subtract', 'divide'])当然,也可以让 featuretools 自动为我们选择特征:
features, feature_names = ft.dfs(entityset=es, target_entity='clients', max_depth=2)3.2 Boruta
Boruta主要是用来进行特征选择。所以严格意义上,Boruta并不是我们所需要的自动化特征工程包。
Boruta-py是brouta特征约简策略的一种实现,在该策略中,问题以一种完全相关的方式构建,算法保留对模型有显著贡献的所有特征。这与许多特征约简算法所应用的最小最优特征集相反。boruta方法通过创建由目标特征的随机重排序值组成的合成特征来确定特征的重要性,然后在原始特征集的基础上训练一个简单的基于树的分类器,在这个分类器中,目标特征被合成特征所替代。所有特性的性能差异用于计算相对重要性。
Boruta函数通过循环的方式评价各变量的重要性,在每一轮迭代中,对原始变量和影子变量进行重要性比较。如果原始变量的重要性显著高于影子变量的重要性,则认为该原始变量是重要的;如果原始变量的重要性明显低于影子变量的重要性,则认为该原始变量是不重要的。其中,原始变量就是我们输入的要进行特征选择的变量;影子变量就是根据原始变量生成的变量
生成规则是:
- 先向原始变量中加入随机干扰项,这样得到的是扩展后的变量
- 从扩展后的变量中进行抽样,得到影子变量
使用python来实现影子特征,类似于:
# 从训练数据集获取特征
z = train_df[f].values
# Shuffle
np.random.shuffle(z)
# 影子特征
train_df[f + "shadow"] = z下面是Boruta算法运行的步骤:
- 首先,它通过创建混合数据的所有特征(即影子特征)为给定的数据集增加了随机性。
- 然后,它训练一个随机森林分类的扩展数据集,并采用一个特征重要性措施(默认设定为平均减少精度),以评估的每个特征的重要性,越高则意味着越重要。
- 在每次迭代中,它检查一个真实特征是否比最好的影子特征具有更高的重要性(即该特征是否比最大的影子特征得分更高)并且不断删除它视为非常不重要的特征。
- 最后,当所有特征得到确认或拒绝,或算法达到随机森林运行的一个规定的限制时,算法停止。
3.3 tsfresh
tsfresh是基于可伸缩假设检验的时间序列特征提取工具。该包包含多种特征提取方法和鲁棒特征选择算法。
tsfresh可以自动地从时间序列中提取100多个特征。这些特征描述了时间序列的基本特征,如峰值数量、平均值或最大值,或更复杂的特征,如时间反转对称性统计量等。
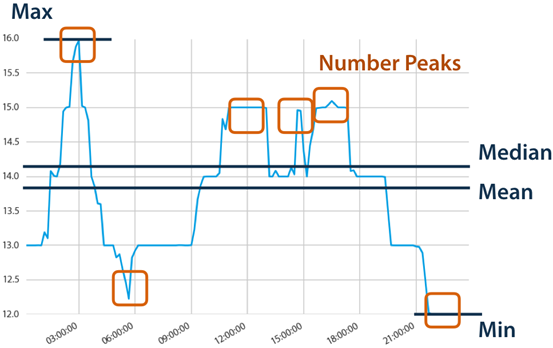

这组特征可以用来在时间序列上构建统计或机器学习模型,例如在回归或分类任务中使用。
时间序列通常包含噪声、冗余或无关信息。因此,大部分提取出来的特征对当前的机器学习任务没有用处。为了避免提取不相关的特性,tsfresh包有一个内置的过滤过程。这个过滤过程评估每个特征对于手头的回归或分类任务的解释能力和重要性。它建立在完善的假设检验理论的基础上,采用了多种检验方法。
需要注意的是,在使用tsfresh提取特征时,需要提前把结构进行转换,一般上需转换为(None,2)的结构,例如下图所示:
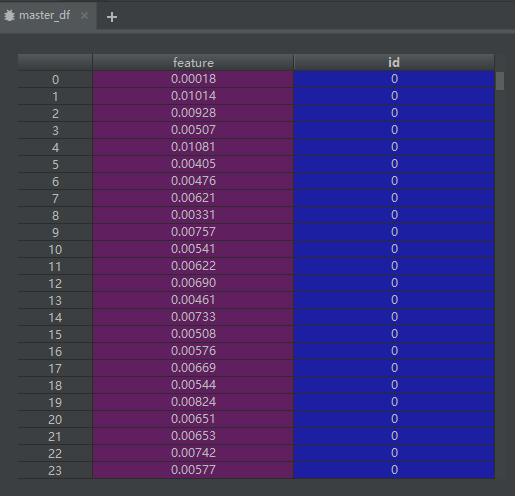

例子:
import matplotlib.pylab as plt
from tsfresh import extract_features, select_features
from tsfresh.utilities.dataframe_functions import impute
from tsfresh.feature_extraction import ComprehensiveFCParameters
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
if __name__ == '__main__':
N = 500
df = pd.read_csv('UCI HAR Dataset/train/Inertial Signals/body_acc_x_train.txt', delim_whitespace=True, header=None)
y = pd.read_csv('UCI HAR Dataset/train/y_train.txt', delim_whitespace=True, header=None, squeeze=True)[:N]
# plt.title('accelerometer reading')
# plt.plot(df.ix[0, :])
# plt.show()
#
extraction_settings = ComprehensiveFCParameters()
master_df = pd.DataFrame({'feature': df[:N].values.flatten(),
'id': np.arange(N).repeat(df.shape[1])})
# 时间序列特征工程
X = extract_features(timeseries_container=master_df, n_jobs=0, column_id='id', impute_function=impute,
default_fc_parameters=extraction_settings)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
cl = DecisionTreeClassifier()
cl.fit(X_train, y_train)
print(classification_report(y_test, cl.predict(X_test)))
# 未进行时间序列特征工程
X_1 = df.ix[:N - 1, :]
X_train, X_test, y_train, y_test = train_test_split(X_1, y, test_size=.2)
cl = DecisionTreeClassifier()
cl.fit(X_train, y_train)
print(classification_report(y_test, cl.predict(X_test)))此外,对于进行时间序列特征工程后的数据集进行特征选择,进一步提高模型指标。
这里,可以利用tsfresh.select_features方法进行特征选择,然而由于其仅适用于二进制分类或回归任务,所以对于6个标签的多分类,我们将多分类问题转换为6个二元分类问题,故对于每一种分类,都可以通过二分类进行特征选择:
relevant_features = set()
for label in y.unique():
y_train_binary = y_train == label
X_train_filtered = select_features(X_train, y_train_binary)
print("Number of relevant features for class {}: {}/{}".format(label, X_train_filtered.shape[1],
X_train.shape[1]))
relevant_features = relevant_features.union(set(X_train_filtered.columns))
X_train_filtered = X_train[list(relevant_features)]
X_test_filtered = X_test[list(relevant_features)]
cl = DecisionTreeClassifier()
cl.fit(X_train_filtered, y_train)
print(classification_report(y_test, cl.predict(X_test_filtered)))注意:在Windows开发环境下,会抛出“The “freeze_support()” line can be omitted if the program is not going to be frozen to produce an executable.”多进程的错误,导致无限循环,解决方法是在代码执行时引入” if __name__ == ‘__main__’:“ 。可参考: https://github.com/blue-yonder/tsfresh/issues/185 。
以下是分别使用tsfresh进行特征工程、未进行特征工程以及使用tsfresh进行特征工程+特征选择后的模型效果:
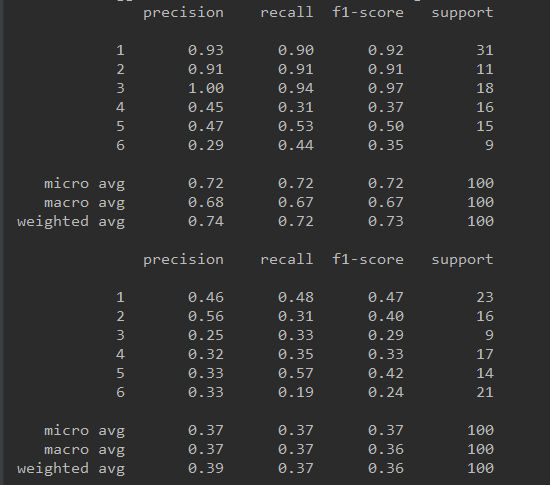

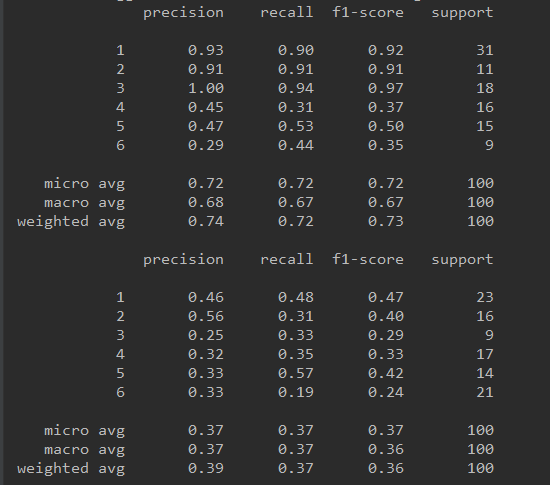

4. 总结
自动化特征工程解决了特征构造的问题,但同时也产生了另一个问题:在数据量一定的前提下,由于产生过多的特征,往往需要进行相应的特征选择以避免模型性能的降低。事实上,要保证模型性能,其所需的数据量级需要随着特征的数量呈指数级增长。
本文完整代码位于:https://github.com/wangkangdegithub/AutoML 。
本文来自oschina,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://my.oschina.net/u/4311881/blog/3295270
注意:本文归作者所有,未经作者允许,不得转载

