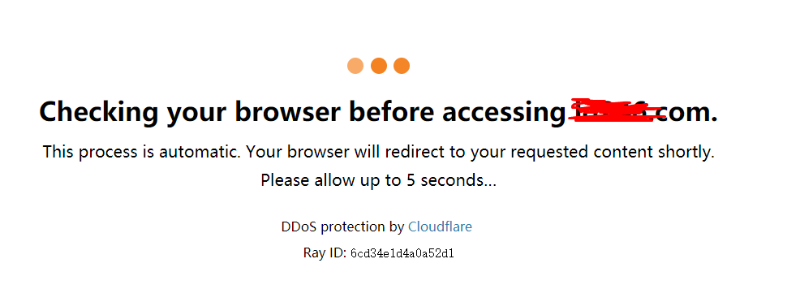
由于现在大型网站对selenium工具进行检测,会跳页面checking your browser before accessing,若检测到selenium,则判定为机器人,访问被拒绝。所以第一步是要防止被检测出为机器人,如何防止被检测到呢?当使用selenium进行自动化操作时,在chrome浏览器中的consloe中输入windows.navigator.webdriver会发现结果为Ture,而正常使用浏览器的时候该值为False。所以我们将windows.navigator.webdriver进行屏蔽。
在代码中添加:
options = webdriver.ChromeOptions()
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
同时,为了加快爬取速度,我们将浏览器模式设置为不加载图片,在代码中添加:
options = webdriver.ChromeOptions()
# 不加载图片,加快访问速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
注意:本文归作者所有,未经作者允许,不得转载

