requests.get()爬去中文网页乱码解决方法
当我们使用requests.get()爬取百度首页时会发现,返回的html代码中的中文发生乱码。
import requests
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url = 'http://www.baidu.com'
html = requests.get(url, headers = headers)
print(html.text)
发现下图中中文位置出现乱码。
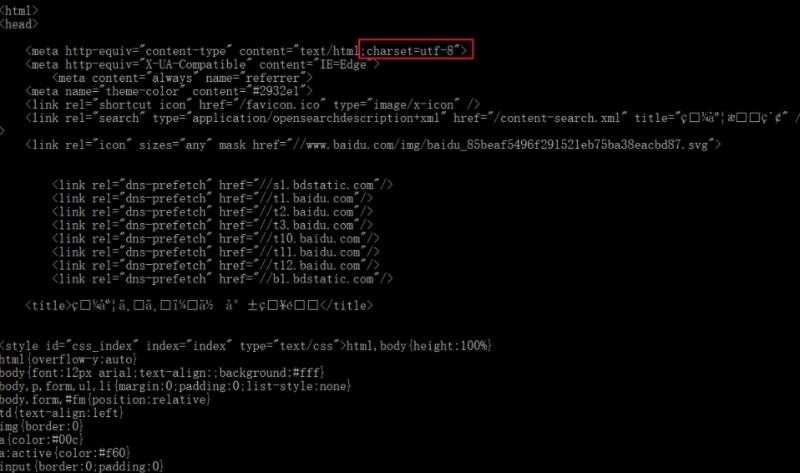
对源码分析发现源码是以’utf-8’编码的。
以下提供两种思路:1.将get到的结果再用’utf-8’编码,之后获取text属性。官网给出的解决方法。2.对get返回结果的text属性以’latin-1’编码,再用’utf-8’解码。
1.
import requests
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url = 'http://www.baidu.com'
html = requests.get(url, headers = headers)
html.encoding = 'utf-8'
print(html.text)
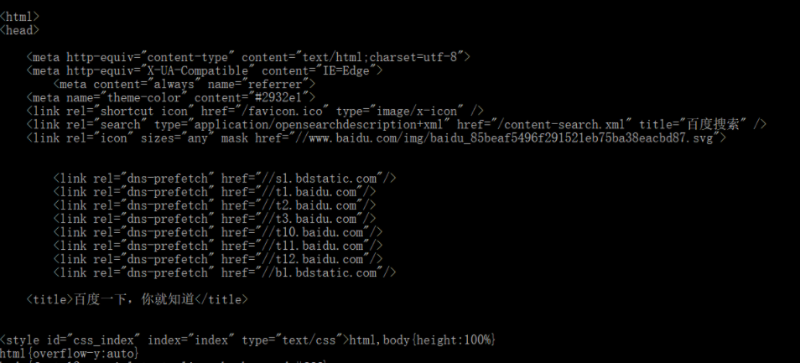
2.
import requests
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url = 'http://www.baidu.com'
html = requests.get(url, headers = headers)
print(html.text.encode('latin-1').decode('utf-8'))
注意:本文归作者所有,未经作者允许,不得转载

