我们提出了一种新的特征转换方法,类似于标准化。该方法来自 Michael Jahrer,他最近赢得了另一场比赛,随后分享了他使用的方法。
有在普遍关心的一些东西写了。例如,它再次确认梯度提升比神经网络更快、更容易使用,同时提供相似的结果。迈克尔使用了 lightgbm:
不错的库,速度非常快,有时在准确性方面比 xgboost 好。合奏中的一个模型。我在简历上调整了参数。
对于神经网络,Jahrer 提出了一种显然比标准化或归一化效果更好的非标准方法。他称之为RankGauss:
基于梯度的模型(如神经网络)的输入归一化至关重要。对于 lightgbm/xgb 没有关系。我在过去发现的最好的东西是“RankGauss”。它基于等级变换。
第一步是为从 -1…1 排序的特征分配一个 linspace,然后应用误差函数 ErfInv 的倒数来像高斯一样塑造它们,然后我减去平均值。此 trafo 不涉及二进制功能(例如 1-hot 的)。这通常比标准均值/标准定标器或最小值/最大值好得多。
尽管名称 RankGauss 反映了该方法的两个步骤的顺序,但我们更喜欢“GaussRank”。听起来更好。
为了实现它,首先我们计算给定列 ( argsort ) 中每个值的排名。然后我们将等级归一化为 -1 到 1 的范围。然后我们应用神秘的erfinv函数。这样做的目的是使变换后的秩的分布呈高斯分布。
实际上,erfinv(-1)是-inf而erfinv(1)是inf,所以我们需要考虑到这一点。
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import erfinv
# simulating normalized ranks from -0.99 to 0.99
x = np.arange( -0.99, 1, 0.01 )
y = erfinv( x )
plt.hist( y )
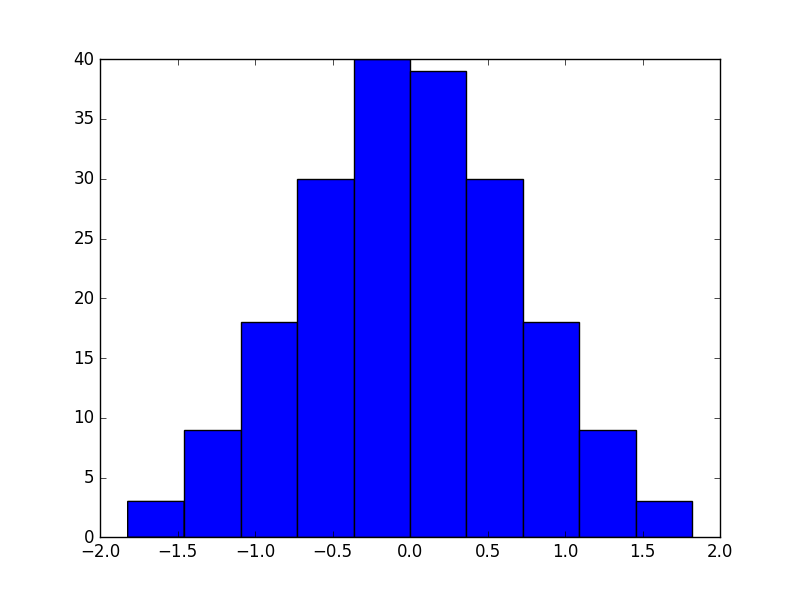

减去平均值并不是真正必要的,因为它非常接近于零。
In [33]: y.mean()
Out[33]: 1.7495775905650709e-15
在实践中
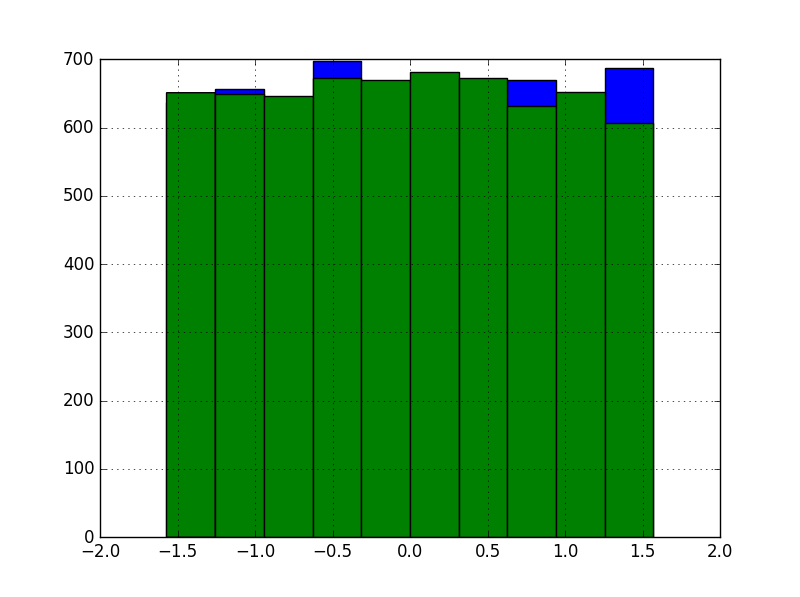
为了了解它是如何工作的,我们在kin8nm数据集上测试了该方法。数据集中的特征,总共八个,或多或少均匀分布。这是训练集中前两个的直方图:
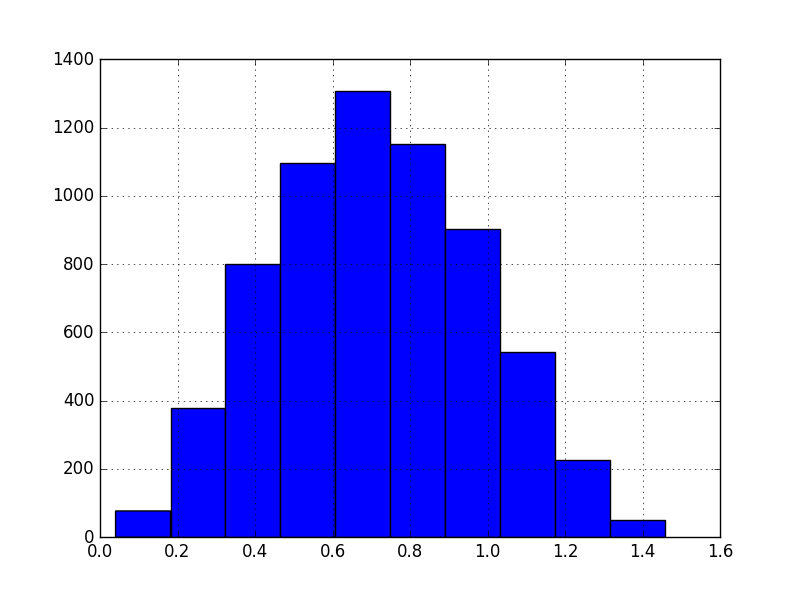
相比之下,目标变量:
我们为 GaussRank实现了fit_predict()方法,因为它比编写单独的fit()和predict()方法要容易得多。使用它从训练集和测试集中获取特征,然后联合拟合/转换的方法。没关系,因为我们没有使用任何标签。
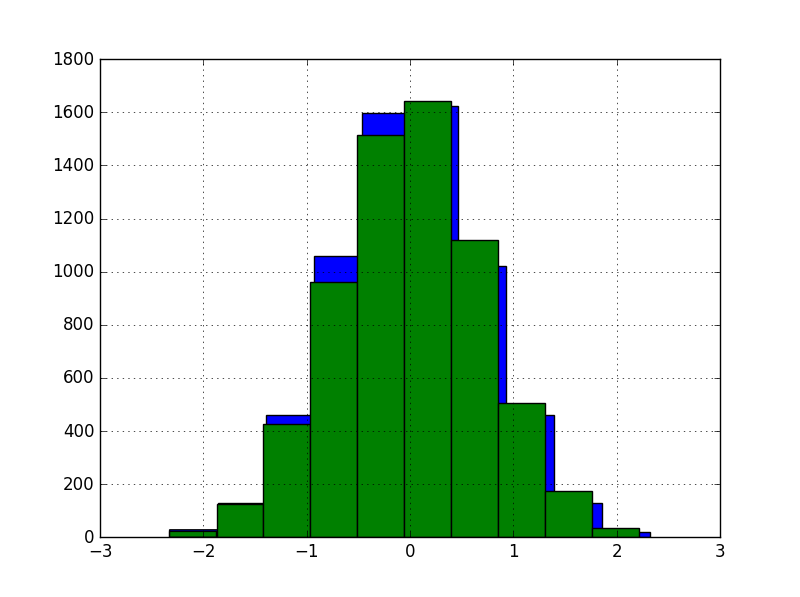
变换后前两个特征的直方图:
对于神经网络,我们使用 Keras 并使用Hyperband对数据集的两个版本执行超参数搜索:有和没有 GaussRank。
我们使用原始版本获得的最佳分数是 8.14% RMSE,这接近我们不久前使用PyBrain获得的分数。对于转换后的版本,它是 10.86%。因此,我们必须得出结论,GaussRank 不适用于数据集。
为了进行比较,我们还使用随机投影对数据进行了转换,并保持相同的维度。注意这个方法是将X矩阵作为一个整体进行变换,而不是GaussRank的逐列方案。
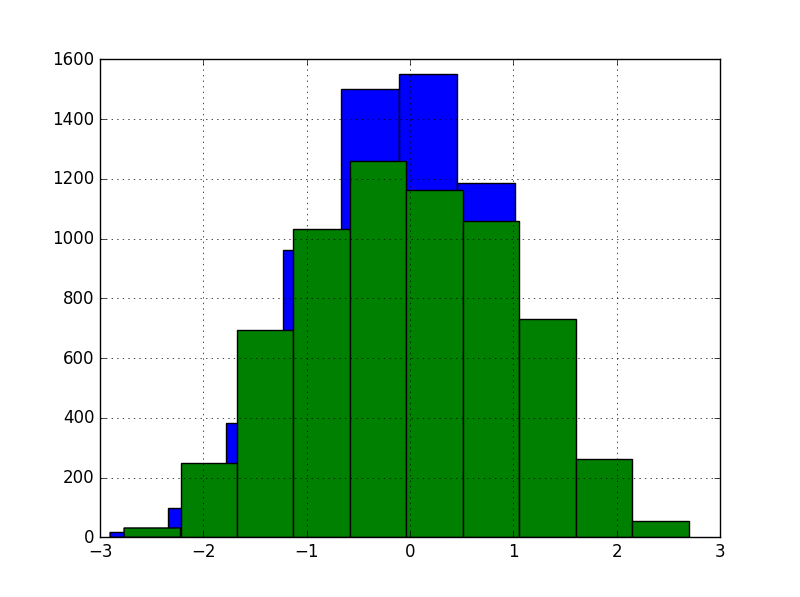
这个版本产生了更不起眼的 13.27% RMSE。这并不奇怪,因为无监督的随机投影通常不太可能为监督学习带来更好的表示。
实验的数据、代码和结果可在 GitHub 上找到。
注意:本文归作者所有,未经作者允许,不得转载

