IBM SPSS 软件家族预测分析模型的商业应用初探,第 5 部分: 应用 Statistics 非参数检验分析快餐连锁店促销方案
快餐连锁店促销典型案例
某快餐连锁店为其菜单添加新菜品,策划了三种促销新菜品的方案,打算通过分析三种方案的市场销售情况,得出三种方案在促销新菜品方面,除了销量不同外,是否存在显著性差异,进而为高层决策提供理论依据。非参数检验作为数理统计学的一个分支,对于这种总体分布和方差未知或知道甚少的样本数据,提供了多种检验方法,每种方法适用于不同特点的样本数据,其原理是利用样本数据对总体分布形态等进行推断,不涉及有关总体分布的参数,进而得出原假设是否为真。以下通过一则快餐连锁店促销新菜品的案例,利用 IBM SPSS Statistics 产品中的“非参数检验”,分析新菜品的销量,得出三种促销方案是否存在显著性差异。文中将详细地描述产品的设置和使用方法,以及对结果的分析。
非参数检验简介
非参数检验的相关概念
非参数检验是统计分析方法的重要组成部分,它与参数检验共同构成统计推断的基本内容。参数检验是在已知总体分布的情况下,对总体分布的参数如均值、方差等进行推断的方法;而非参数检验对总体分布未知或知道甚少的情况下,利用样本数据对总体分布等进行推断的方法。由于非参数检验在推断过程中不涉及总体分布的参数,故得名“非参数”检验。以下对非参数检验涉及到的相关概念进行说明。
总体是我们要调查或统计某一现象全部数据的集合;样本是从总体中随机抽取的部分个体。一般统计调查中,总体是大量的甚至是无限的,在实际工作中不可能对每个个体逐一进行研究,往往是随机选取一组样本,根据这一部分的研究结果,再去推断和估计总体的情况。
图 1. 用样本估计总体
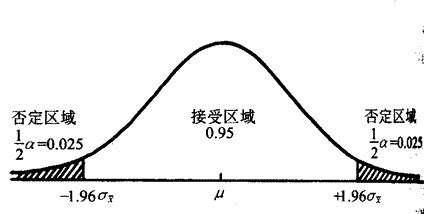
 零假设,又称原假设,指进行统计检验时预先建立的假设。零假设成立时,有关统计量应服从已知的某种概率分布。当统计量的计算值落入否定域时,应否定原假设。备择假设就是和原假设相反的假设。零假设是我们研究两个事物之间是否有关时做出的最保守的假设,从数学上来看,零假设和备择假设的地位是相等的。在下图正态分布曲线中,接受区域表示接受原假设的区域,否定区域为否定原假设的区域。
零假设,又称原假设,指进行统计检验时预先建立的假设。零假设成立时,有关统计量应服从已知的某种概率分布。当统计量的计算值落入否定域时,应否定原假设。备择假设就是和原假设相反的假设。零假设是我们研究两个事物之间是否有关时做出的最保守的假设,从数学上来看,零假设和备择假设的地位是相等的。在下图正态分布曲线中,接受区域表示接受原假设的区域,否定区域为否定原假设的区域。
图 2. 原假设接受区域
 参数检验是当总体分布已知,根据样本数据对总体分布的统计参数进行推断的方法。非参数检验是在总体分布未知的情况下,利用样本数据对总体分布等进行推断的方法。参数检验要求数据呈正态分布,为连续数据,要求样本要足够大,对异常数据敏感;而非参数检验不要求分布,数据可以是连续型,也可以分类型,而且能够处理小样本数据,对异常数据不敏感。非参数检验适用性强,但灵敏度和精确度不如参数检验,因为这些特点,加上非参数检验一般原理和计算比较简单,因此常用于一些为正式研究进行探路的预备性研究中。
参数检验是当总体分布已知,根据样本数据对总体分布的统计参数进行推断的方法。非参数检验是在总体分布未知的情况下,利用样本数据对总体分布等进行推断的方法。参数检验要求数据呈正态分布,为连续数据,要求样本要足够大,对异常数据敏感;而非参数检验不要求分布,数据可以是连续型,也可以分类型,而且能够处理小样本数据,对异常数据不敏感。非参数检验适用性强,但灵敏度和精确度不如参数检验,因为这些特点,加上非参数检验一般原理和计算比较简单,因此常用于一些为正式研究进行探路的预备性研究中。
图 3. 非参数检验示意图

非参数检验的分类
非参数检验根据检测样本的不同分为单样本的非参数检验,独立样本的非参数检验和相关样本的非参数检验。
单样本的非参数检验
- 定义:是对单个总体的分布形态等进行推断的方法。
- 特点:是待检验字段无分组。
- 实例:儿童身高是否服从正态分布。心脏病人猝死人数与日期的关系是否与某理论分布相吻合。
独立样本的非参数检验
- 定义:是对两组或多组独立样本的分析来推断各自的总体的分布等是否存在显著性差异的方法,其中独立样本是指在一个总体中随机抽样对另一个总体中随机抽样没有影响的情况下所获得的样本。
- 特点:是待检验字段被一个分类字段分组,每组数据就是一个独立样本。
- 实例:不同工艺产品的寿命分布是否一致。城镇和农村的存款分布是否一致。某车间用四种不同的操作方法检测产品优等品率的实验,这四种不同的操作方法对产品优等品率是否有显著性差异。
相关样本的非参数检验
- 定义:是对两组或多组相关样本的分析来推断各自的总体的分布等是否存在显著性差异的方法,其中相关样本是指两组或多组样本的数据之间存在一一对应的关系,如同一组实验体在前后两次实验中的两个项目,相互影响,互不独立。
- 特点:是待检验字段是两个或多个相关字段。
- 实例:某校 15 名男生长跑锻炼前后的晨脉变化有无显著性差异。为了试验某种减肥药的性能,测量 10 个人在服用该药物前,一个月后、两个月后,三个月后的体重,在这四个时期,这 10 个人的体重有无发生显著变化。
非参数检验的方法
非参数检验的三类检验,每类都包含各种方法,每种方法都具有各自的特点和适用范围。
表 1. 单样本的非参数检验
| 检验分类 | 检验方法 | 检验方法描述 | 原假设举例 |
|---|---|---|---|
| 单样本 | 二项式检验 | 适用于两个类别的标记字段 | 某班级性别男和女以 0.5 和 0.5 的概率发生 |
| 卡方检验 | 适用于次数分布的检验,是否与某理想的分布相等 | 某公司受教育水平(9 年,12 年,16 年,19 年)的类别以相同概率发生 | |
| Kolmogorov-Smirnov 检验 | 利用样本数据推断总体是否服从某一理论分布,如正态分布、均匀分布、泊松分布和指数分布 | 某公司当前薪金的分布为正态分布,平均值为 34419.57 美元,标准差为 17075.66 美元 | |
| Wilcoxon 符号秩检验 | 检验连续字段的中位数是否为某理想数值 | 某公司当前薪金的中位数等于 34419.57 美元 | |
| 游程检验 | 适用于两个类别的标记字段,检验这两个值的出现是否是随机的 | 某班级性别男和女的序列是随机序列 |
表 2. 独立样本的非参数检验
| 检验分类 | 检验方法 | 检验方法描述 | 原假设举例 | |
|---|---|---|---|---|
| 独立样本 | 二样本 | Mann-Whitney U | 通过两个样本的秩来检验两个总体的分布是否存在显著性差异 | 某公司当前薪金的分布在性别类别上相同 |
| Kolmogorov-Smirnov | 通过两个样本的分布来检验两个总体的分布是否存在显著性差异 | |||
| Wald-Wolfowitz | 通过对游程的研究来实现推断两个总体的分布是否存在显著性差异 | |||
| Moses 极端反应 | 一个样本作为控制样本,另一个作为实验样本,检验是否具有相同范围 | 某公司当前薪金的范围在性别类别上相同 | ||
| Hodges-Lehman 估计 | 可以为两个组的中位数差异生成一个独立样本估计和置信区间 | 无原假设,计算估计值和置信区间 | ||
| K 样本 | Kruskal-Wallis 单因素 ANOVA | 通过推广的平均秩来实验推断多个样本的分布是否存在显著性差异 | 某公司当前薪金的分布在教育水平(9 年,12 年,16 年,19 年)类别上相同 | |
| Jonckheere-Terpstra 有序选项检验 | 可作为比 Kruskal-Wallis 功能更强大的选项,但前提是 K 个样本需具有自然顺序 | 某公司当前薪金的分布在教育水平(9 年,12 年,16 年,19 年)类别上相同,其中教育水平具有顺序 | ||
| 中位数检验 | 检验 K 个样本是否具有相同的中位数 | 某公司当前薪金的中位数在教育水平(9 年,12 年,16 年,19 年)类别上相同 | ||
表 3. 相关样本的非参数检验
| 检验分类 | 检验方法 | 检验方法描述 | 原假设举例 | |
|---|---|---|---|---|
| 相关样本 | 二样本 | McNemar 检验 | 用来检验两个标记字段(只有两个值的分类字段)间的值组合可能性是否相同 | 甲班三好学生和乙班三号学生的分布可能性相同 |
| 边际齐性检验 | 两个有序字段间的值组合可能性是否相同,该有序字段可以有两个以上的值 | 甲公司和乙公司员工的教育水平(9 年,12 年,16 年,19 年)的分布相同 | ||
| 符号检验 | 检验两个连续字段间的中位数差是否等于 0,推断两样本是否来自中心位置相同的总体 | 某公司起始薪金与当前薪金之间差异的中位数等于 0 | ||
| Wilcoxon 匹配对符号秩 | 该检验类似符号检验,符号检验只是比较了前后测试结果的大小,却忽略大小变化的程度,而 Wilcoxon 检验考虑了大小变化的程度 | |||
| Hodges-Lehman | 为两个配对连续字段间中位数差生成一个相关样本估计和置信区间 | 无原假设,计算估计值和置信区间 | ||
| K 样本 | Cochran Q | 用来检验 K 个标记字段(只有两个值的分类字段)间的值组合可能性是否相同 | 甲班,乙班和丙班的三好学生的分布相同 | |
| Kendall 协同系数 | 将生成对裁判员或评分员间一致性的测量,检验字段为评分或分数,只适用于连续字段 | 甲乙丙丁四个裁判员分别对所有跳远运动员评分的分布相同 | ||
| Friedman 按秩二因素 ANOVA | 检验 K 个相关样本是否从同一总体中抽取,适合于多配对组的平均秩和检验,是目前国内通用教材的秩和检验,检验字段只能是连续字段 | 10 个人在服用某减肥药后,测量服用后,一个月,两个月,三个月的体重,这四个时期 10 个人的体重的分布相同 | ||
IBM SPSS Statistics 非参数检验的使用
IBM SPSS Statistics 是世界上最早的统计分析软件,作为 IBM SPSS 的一款主打产品,随着 IBM SPSS 的发展和壮大,它的功能、性能也得到了显著的增强和提升。IBM SPSS Statistics 为非参数检验提供了多种方法和功能。本章节将重点结合具体的商业案例,对非参数检验的设置、使用方法和结果分析做详细介绍。
对于快餐连锁店为其菜单添加新菜品的案例,本章节利用三种促销方案的销售数据,通过非参数检验的具体使用方法来进行分析,进而得出三种促销方案的分析结果,为进一步的决策提供理论依据。
数据分析阶段
对于此案例,我们适用 IBM SPSS Statistics 自带的安装目录下的 Samples 文件夹下的样本数据 testmarket.sav。我们希望分析出三种促销方案是否存在显著性差异,以此来合理选择促销方案,进而提高新菜品的销量。
现在让我们打开 IBM SPSS Statistics 软件,建议使用 18.0 以上版本,文章节演示使用的是 IBM SPSS Statistics 20.0。打开软件后,进入文件菜单下的打开中的数据选项,选择安装目录下自带的 Samples 数据 testmarket.sav,会看到数据中各个字段的名称和类型,如下图所示。
图 4. 数据字段视图
 此数据包括 7 个字段,分别表示销售记录的信息,marketid 表示快餐店所在的市场编号,mktsize 表示市场的大小,locid 表示快餐店所在的地理位置编号,ageloc 表示该快餐店在该地开业了多少年,promo 表示所使用的促销方案,week 表示促销进行的第几周,sales 表示某个周的销量总额。对应如下图中的数据。
此数据包括 7 个字段,分别表示销售记录的信息,marketid 表示快餐店所在的市场编号,mktsize 表示市场的大小,locid 表示快餐店所在的地理位置编号,ageloc 表示该快餐店在该地开业了多少年,promo 表示所使用的促销方案,week 表示促销进行的第几周,sales 表示某个周的销量总额。对应如下图中的数据。
图 5. 数据视图
 第一条记录表示,市场一的第一个地点使用第三种促销方案,在第一个周的销量为 70.63 千美元;第六条记录表示,市场一的第二个地点使用第二种促销方案,在第二周的销量为 56.74 千美元;等等。
第一条记录表示,市场一的第一个地点使用第三种促销方案,在第一个周的销量为 70.63 千美元;第六条记录表示,市场一的第二个地点使用第二种促销方案,在第二周的销量为 56.74 千美元;等等。
如何对这些数据进行分析,选择哪种非参数检验方法,这是使用非参数检验的第一个步骤,这时就要结合第二章节中的理论知识,来进行具体分析。当然对于一个初次使用者,也可以使用非参数检验提供的默认方法进行分析。
现在对数据进行分析,三种促销方案的数据可以看作是三个样本,促销方案一的所有记录组成样本一,促销方案二的所有记录组成样本二,促销方案三的所有记录组成样本三,再根据数据的特点,待分析的字段是销量,可以看出 sales 检验字段被 promo 分类字段所分组,所以可以判断该数据适合使用独立样本的非参数检验方法。也就是说三个样本之间互相独立,互不影响。进而,该数据为三样本数据,因此可以选择 K 样本的独立样本检验方法,供选择的方法包括 Kruskal-Wallis 单因素 ANOVA 方法和 Jonckheere-Terpstra 有序选项检验方法,因为 J-T 方法要求样本要具有自然顺序,所以对该样本数据的分析使用 Kruskal-Wallis 单因素 ANOVA 方法。
操作使用阶段
第一步,进入“分析”菜单下的“非参数检验”中的“独立样本”选项,这时会弹出一个设置对话框,在该对话框中完成方法的选择和参数的设置,如下图所示。
图 6. 设置非参数检验目标
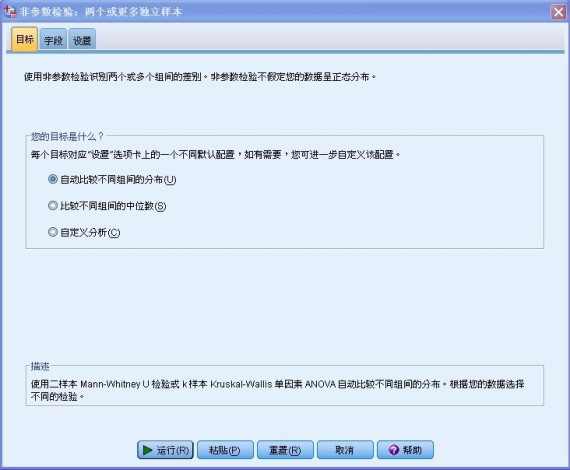 在该页面选择要进行的分析,如果选择“自动比较不同组间的分布”选项,则系统会根据具体数据的情况选择一个默认方法,对二样本的数据进行 Mann-Whitney U 检验,对于 K 样本的数据进行 Kruskal-Wallis 单因素 ANOVA 检验。如果选择“比较不同组间的中位数”选项,则系统会选择“设置”选项卡中的“中位数检验”。如果选择“自定义分析”选项,则用户可以在“设置”选项卡中自己选择适当的方法。这里要说明一点,如果选择了“自动比较不同组间的分布”选项,而又在“设置”选项卡中选择了某种检验方法;或者选择了“比较不同组间的中位数”选项,而又在“设置”选项卡中选择了不同的检验方法,则系统会自动选择“自定义分析”选项。
在该页面选择要进行的分析,如果选择“自动比较不同组间的分布”选项,则系统会根据具体数据的情况选择一个默认方法,对二样本的数据进行 Mann-Whitney U 检验,对于 K 样本的数据进行 Kruskal-Wallis 单因素 ANOVA 检验。如果选择“比较不同组间的中位数”选项,则系统会选择“设置”选项卡中的“中位数检验”。如果选择“自定义分析”选项,则用户可以在“设置”选项卡中自己选择适当的方法。这里要说明一点,如果选择了“自动比较不同组间的分布”选项,而又在“设置”选项卡中选择了某种检验方法;或者选择了“比较不同组间的中位数”选项,而又在“设置”选项卡中选择了不同的检验方法,则系统会自动选择“自定义分析”选项。
我们要进行 Kruskal-Wallis 单因素 ANOVA 检验,所以选择“自定义分析”选项。
第二步,进入“字段”选项卡,该页面要求指定检验字段和分组字段,如下图所示。
图 7. 非参数检验字段视图
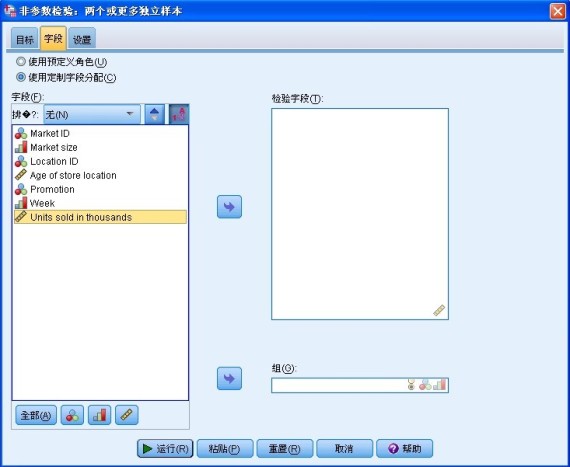 如果选择“使用预定义角色”选项,则使用现有的字段信息,字段角色为“目标”或“两者”的连续字段将用作检验字段,字段角色为“输入”的分类字段将用作分组字段。如果选择“使用定制字段分配”选项,则需要指定检验字段和分组字段。对于本案例,检验字段为 sales,分组字段为 promo,分别将两个字段拖放进“检验字段”和“组”中,如下图所示。
如果选择“使用预定义角色”选项,则使用现有的字段信息,字段角色为“目标”或“两者”的连续字段将用作检验字段,字段角色为“输入”的分类字段将用作分组字段。如果选择“使用定制字段分配”选项,则需要指定检验字段和分组字段。对于本案例,检验字段为 sales,分组字段为 promo,分别将两个字段拖放进“检验字段”和“组”中,如下图所示。
图 8. 设置非参数检验字段
 此时就设置好了检验字段和分组字段。
此时就设置好了检验字段和分组字段。
第三步,进入“设置”选项卡,该页面要求选择检验方法和设置参数,如下图所示。
图 9. 设置非参数检验方法
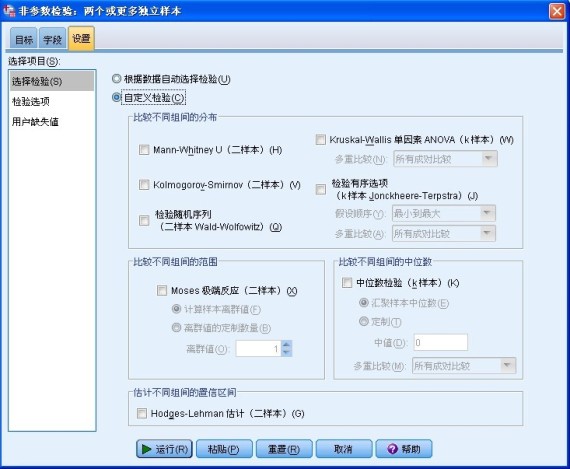 如果在“目标”选项卡中选择了“自动比较不同组间的分布”选项,那么系统会选择“根据数据自动选择检验”选项,将对二样本的数据应用 Mann-Whitney U 检验,对 K 样本的数据应用 Kruskal-Wallis 单因素 ANOVA 检验。
如果在“目标”选项卡中选择了“自动比较不同组间的分布”选项,那么系统会选择“根据数据自动选择检验”选项,将对二样本的数据应用 Mann-Whitney U 检验,对 K 样本的数据应用 Kruskal-Wallis 单因素 ANOVA 检验。
上文已经分析过,本文案例使用 Kruskal-Wallis 单因素 ANOVA 检验,则选择“自定义检验”选项,勾选“Kruskal-Wallis 单因素 ANOVA”选项。下拉菜单“多重比较”表示对 K 个样本的多重比较,包括“所有成对比较”和“逐步降低”,本文中选择“所有成对比较”选项,即对 K 个样本两两进行比较。
进入“检验选项”项目,该页面设置一些检验参数,如下图所示。
图 10. 设置检验选项
 显著性水平是介于 0 和 1 之间的数值,默认值为 0.05,表示在假设检验中,用样本资料推断总体时,犯拒绝原假设错误的可能性大小。对于该值,一般使用默认值 0.05。接着,为置信区间设置置信度,是介于 0 和 100 之间的数值,默认值是 95,表示估计可靠性的概率,误差范围。“已排除的个案”选项表示如何从检验中排除具有缺失值的记录,提供了两种方法,一般默认使用“按检验排除个案”。
显著性水平是介于 0 和 1 之间的数值,默认值为 0.05,表示在假设检验中,用样本资料推断总体时,犯拒绝原假设错误的可能性大小。对于该值,一般使用默认值 0.05。接着,为置信区间设置置信度,是介于 0 和 100 之间的数值,默认值是 95,表示估计可靠性的概率,误差范围。“已排除的个案”选项表示如何从检验中排除具有缺失值的记录,提供了两种方法,一般默认使用“按检验排除个案”。
进入“用户缺失值”项目,该页面表示如何对分类字段处理用户缺失值,如下图所示。
图 11. 设置用户缺失值
 通过本页面选项可以决定是否将用户缺失值在分类字段中视为有效值,一般默认使用“排除”选项。
通过本页面选项可以决定是否将用户缺失值在分类字段中视为有效值,一般默认使用“排除”选项。
在设置了检验方法和参数后,点击“运行”按钮,这时就会在“输出查看器文档”中生成分析结果。
结果分析阶段
接下来,对运行结果进行分析,“假设检验汇总”如下图所示。
图 12. 检验结果汇总视图
 检验结果被描述在上图的表格中,首先是原假设,假设每种促销方案上销量的分布相同,如果接受原假设,则表明每种促销方案无显著性差异;如果拒绝原假设,则每种促销方案存在显著性差异。接下来是测试的方法,这里使用的是独立样本 Kruskal-Wallis 检验。接着是测试结果中最重要的参数指标——渐进显著性,如果该值小于显著性水平(默认是 0.05),则表明拒绝原假设;否则表明接受原假设。最后为结论,结论是拒绝原假设,销量在每个促销方案上的分布不同,表明存在显著性差异。
检验结果被描述在上图的表格中,首先是原假设,假设每种促销方案上销量的分布相同,如果接受原假设,则表明每种促销方案无显著性差异;如果拒绝原假设,则每种促销方案存在显著性差异。接下来是测试的方法,这里使用的是独立样本 Kruskal-Wallis 检验。接着是测试结果中最重要的参数指标——渐进显著性,如果该值小于显著性水平(默认是 0.05),则表明拒绝原假设;否则表明接受原假设。最后为结论,结论是拒绝原假设,销量在每个促销方案上的分布不同,表明存在显著性差异。
对于更详细的分析结果,双击该假设检验汇总表,则会弹出一个模型浏览器,如下图所示。
图 13. 检验结果辅助视图
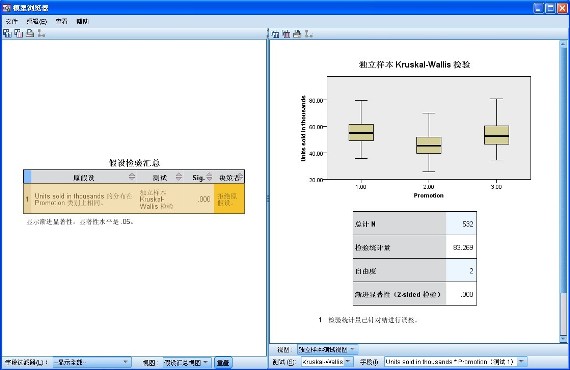 假设汇总视图显示在左边,更详细的辅助视图显示在右边。在右边的辅助视图中,上边是箱图,箱图中显示了销量在促销方案上的分布,关于箱图的详细讲解,请参见 IBM SPSS Statistics 帮助文档。
假设汇总视图显示在左边,更详细的辅助视图显示在右边。在右边的辅助视图中,上边是箱图,箱图中显示了销量在促销方案上的分布,关于箱图的详细讲解,请参见 IBM SPSS Statistics 帮助文档。
从汇总图的渐进显著性值可以判断销量在促销方案上分布不同,进而从箱图可以直观的看出分布具体的差别,将鼠标放置在每个箱图上可以显示出每种促销方案上的平均秩的值,平均秩描述的是该分类上的值在所有值中的占位,平均秩大则表明该分类上的值在所有值中处于靠前位置。从该结果的箱图中可以看出,第一种促销方案的销量在销量占位中靠前,第二种促销方案的销量在销量占位中靠后。
在右边辅助视图的下表中,显示的是一些统计量,所有的记录个数,检验统计量,自由度和渐进显著性,在此只有渐进显著性的值具有指标性意义。
从左边辅助视图下边框处的“视图”下拉框,选择“分类字段信息”视图,会显示如下图所示的柱状图。
图 14. 分类字段信息
 该视图显示的是假设检验中的分类字段的分布情况,该处显示的是促销方案的分布情况,将鼠标放置在每个柱状图上,可以显示出每种分类的具体信息,如将鼠标放置在第一个柱状图上,会显示如下图所示信息。
该视图显示的是假设检验中的分类字段的分布情况,该处显示的是促销方案的分布情况,将鼠标放置在每个柱状图上,可以显示出每种分类的具体信息,如将鼠标放置在第一个柱状图上,会显示如下图所示信息。
图 15. 分类字段详细信息
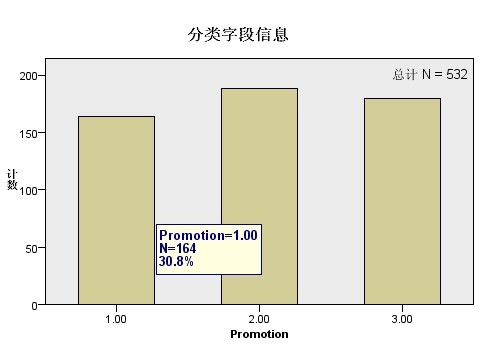 可以看出,第一种促销方案的记录个数为 164,占所有记录总数的 30.8%,依次可以看出第二种促销方案的记录个数为 188,第三种促销方案的记录个数为 180。得到了此信息,可以知道每种促销方案的记录个数和分布情况。
可以看出,第一种促销方案的记录个数为 164,占所有记录总数的 30.8%,依次可以看出第二种促销方案的记录个数为 188,第三种促销方案的记录个数为 180。得到了此信息,可以知道每种促销方案的记录个数和分布情况。
再从左边辅助视图下边框处的“视图”下拉框,选择“连续字段信息”选项,会显示如下图的柱状图。
图 16. 连续字段信息
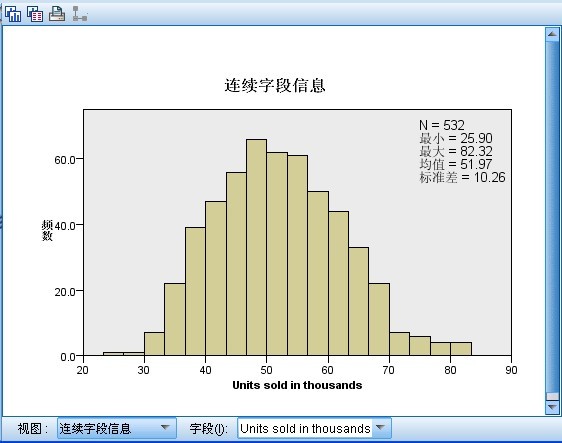 该视图显示的是假设检验中的连续字段的分布情况,该处显示的是销量的分布情况,可以看出销量在 50 左右的记录个数最多,销量在 40 以下和 70 以上的记录比较少。从此图可以了解整个销量的分布情况,普遍的销量情况。
该视图显示的是假设检验中的连续字段的分布情况,该处显示的是销量的分布情况,可以看出销量在 50 左右的记录个数最多,销量在 40 以下和 70 以上的记录比较少。从此图可以了解整个销量的分布情况,普遍的销量情况。
最后,从左边辅助视图下边框处的“视图”下拉框,选择“成对比较”选项,会显示如下图所示成对比较图和表。
图 17. 成对比较视图
 该成对比较视图显示了“距离网络图”和“比较表”,“距离网络图”中的每个节点代表每个促销方案的样本,节点的值是每个促销方案样本的平均秩,节点之间的线表示两样本之间的差异,黄颜色的线表示两样本之间存在显著性差异,黑颜色的线表示两样本之间不存在显著性差异,将鼠标悬停在线上,可以显示两样本之间的调整显著性值。
该成对比较视图显示了“距离网络图”和“比较表”,“距离网络图”中的每个节点代表每个促销方案的样本,节点的值是每个促销方案样本的平均秩,节点之间的线表示两样本之间的差异,黄颜色的线表示两样本之间存在显著性差异,黑颜色的线表示两样本之间不存在显著性差异,将鼠标悬停在线上,可以显示两样本之间的调整显著性值。
“比较表”对应于“距离网络图”,表中的每一行对应图中的每条线,而且表中的每一行是两样本是否存在显著性差异的检验结果,例如第一行表示促销方案二和促销方案三是否存在显著性差异的检验结果。从图中和表中,都可以看出促销方案二和另两种促销方案存在显著性差异。
通过以上的结果分析,首先渐进显著性值小于显著性水平(0.05),则拒绝原假设,接受备择假设,即新菜品的销量在三种促销方案上分布不同,也就是说三种促销方案的样本存在显著性差异,不是来自同一个总体。
进而通过成对比较视图,可以得到促销方案二的样本和其它两种促销方案的样本存在显著性差异,也就是说促销方案二样本的总体不同于其他两种促销方案样本的总体。促销方案二样本和其他两种促销方案样本具有显著性差异的可能性是 95%,5% 没有差异的可能性是由于随机误差造成的,促销方案二在统计意义上和其他促销方案具有显著性差异。
然后再根据促销方案二样本的平均秩较其它两个样本的平均秩小,说明促销方案二的销量低;促销方案一和促销方案三之间的成对比较结果可以看出,这两个样本之间不存在显著性差异,来自相同的总体,销量都较促销方案二的销量高。则促销方案一和促销方案三在提高销量上不存在差异,都能提高菜品销量,较促销方案二的效果好。
根据以上结果分析,可以得出快餐连锁店为推广新菜品,应该选择促销方案一或促销方案三,这两种方案不存在差异,通过采用促销方案一或促销方案三,可以提高新菜品的销量。
总结
本文通过一个实际的商业场景,引入了 IBM SPSS Statistics 非参数检验方法,首先给出了非参数检验的相关概念和方法,接着带领您一步一步的使用,并且介绍了非参数检验方法的选择和设置,最后对结果进行了详细分析。您可以将本方法应用到其他的场景中,如市场调查、证券投资分析、企业综合评价、问卷调查、药物性能试验,等等。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e5%ba%94%e7%94%a8-statistics-%e9%9d%9e%e5%8f%82%e6%95%b0%e6%a3%80%e9%aa%8c%e5%88%86%e6%9e%90%e5%bf%ab%e9%a4%90%e8%bf%9e%e9%94%81%e5%ba%97%e4%bf%83%e9%94%80%e6%96%b9%e6%a1%88/
注意:本文归作者所有,未经作者允许,不得转载

