使用 IBM SPSS Modeler 分析近年图书出版行业数据
IBM® SPSS® Modeler 有着优秀的数据分析及预测功能,一般人对其的印象主要偏重于后者即预测功能。其实作为一个成熟的数据挖掘产品,其数据分析的强大功能是支撑后期数据预测的基础(注:依据数据挖掘行业的实践数据表明,有 70% 的时间都花费在数据分析或者说数据准备部分,可见其重要程度)。 本文模拟分析员安迪的工作,一位图书出版社的数据分析员,每天与各种各样,繁复冗杂的数据打交道,到底怎么将这些杂乱无章的数据整理成有意义的分析结果,并且以清晰明了的形式报告给可能并不懂数据挖掘的老板或更高层的领导呢?本文将从 IBM SPSS Modeler 产品出发,结合近几年图书行业的已知数据,通过实例分析展示 IBM SPSS Modeler 软件的多种数据分析操作方法,以及其颇具特色的数据展示与报告功能。
建议读者阅读本文前,最好先熟悉一下 IBM SPSS Modeler 的一些基本操作,如读取数据、创建数据流、编辑节点等。
数据介绍
本文所用数据全部取自官方公开信息,包括从 2004 年至 2011 年全国新闻出版业的情况。数据的单位有万册、万元、千印张、种等等,由于我们在分析时考虑的是同类数据间的关系,比如单位同为万册的数据之间的关系,所以在这里具体单位是什么其实不那么重要,因此在进入实际分析前我们已将数据中的单位略去。在文中用到单位的地方将会特别说明。数据包括图书出版业各细分类别以及汇总的信息,如图书出版数量和金额,图书销售数量及金额,进出口数量及金额,版权引进及输出数量,等。图示为图书细分类别的销售数量及金额数据的一部分示例。由于 2004 年的数据缺失严重,所以在后面的分析中都将其忽略,只关注从 2005 年开始的一些数据。
图 1. 图片示例

销量 VS 销售金额
先看一下销量与销售金额的情况,如图 1 所示销量与销售金额数据为隔行存在,需要先分别进行提取。IBM SPSS Modeler 提供一个 Sample 节点,我们可以用它来巧妙地完成隔行数据的处理。
图 2. Sample 节点
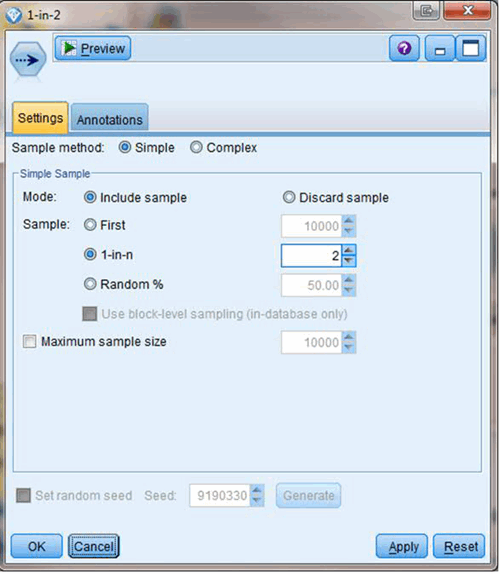
如图所示 Sample 节点有个’1-in-n’ 的选项,在帮助文档中对其是如下描述的: 如果随机选择难以实现,则可以系统(以固定间隔)或顺序方式抽取单元。 选择此选项会按照这样的方式抽样数据:每隔 n 个记录传递或丢弃一次。例如,如果 n 设为 5,则每隔五条记录便会选中一条。 我们的数据是二中取一,所以设置为 2 即可将双数行取出来。注意到有两种 Mode,Include sample 和 Discard sample,使用后者可取单数行,使用前者可将单数行忽略,即取出双数行。如果是大于两行,比如是五行相间的数据,就不是这么简单了,读者有兴趣可以做为练习自己试试。
图 3. Graph 节点选择 Pie 模板
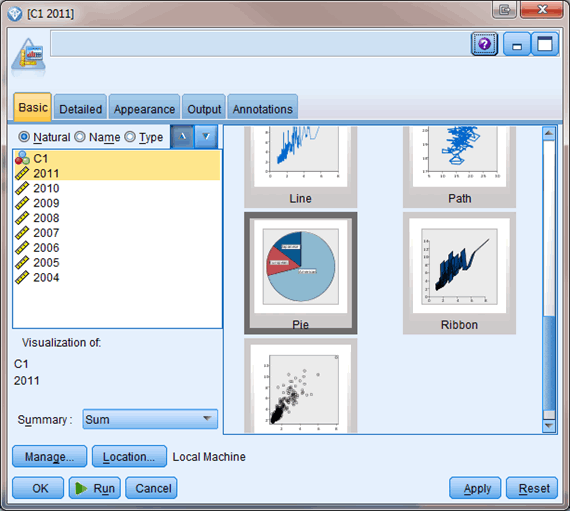
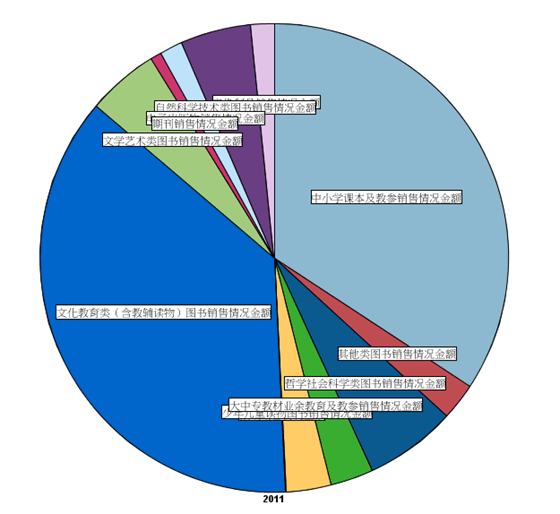
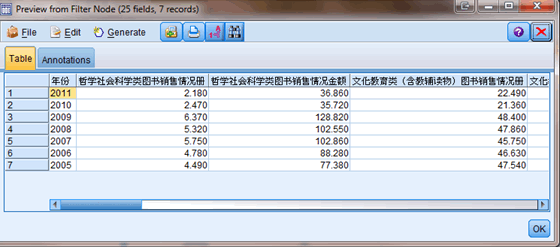
取出单数行,即销量以后,我们对 2011 年的情况做一个饼状图展示。在 Graphs 选项板中的 Graph 节点中内置有 Pie 模板可以使用,如图所示,选择 C1 和 2011 两列,右侧选择 Pie 模板,点击运行可得 2011 年销量按图书分类的一个饼状图。可以看到,文化教育类和中小学课本及教参类占比最大。同样做一个销售金额的饼状图,如图 5 所示,发现这两类图书依旧为占比最大的图书分类,但是与图 4 相比,中小学课本及教参类的比例明显要小一些,这说明这一类别的图书单价相对较低。关于这一点在后面的分析中可以得到印证,此处不再详述。
图 4. 销量 Pie 图
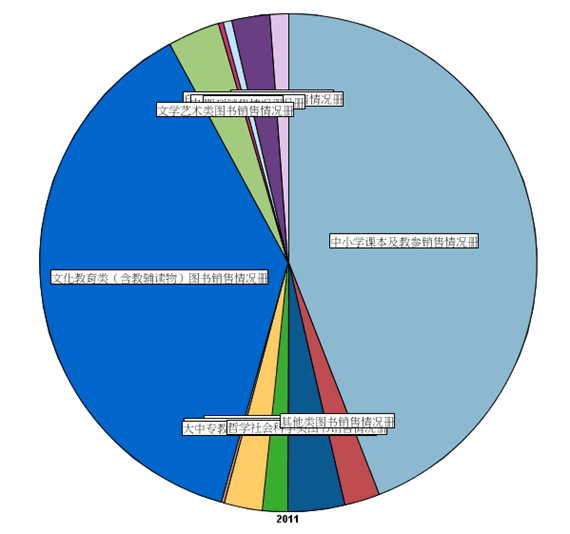
图 5. 销售金额 Pie 图
图书分类分析
现在我们分析一下图书分类数据,看从中能得到什么信息。首先看一下各类图书从 2005 年到 2011 年的人销量与销售金额的变化,SPSS Modeler 提供 Plot 节点和 MultiPlot 节点分别可以展示单散点图与多重散点图,两个节点的使用方法很类似,这里我们直接使用后者同时分析多类图书。MultiPlot 节点显示的是字段之间的关系,而在我们的原数据中,销量和销售金额是以行的形式呈现,所以我们在使用 MultiPlot 节点之前需要先对数据进行转置。IBM SPSS Modeler 提供一个 Transpose 节点可以完成转置操作。如图所示,设置节点以列 C1 所包含的值,即图书分类转置为新的列名。原来的各列即年份值,转置为新的一列,列名字由 Row ID name 指定,在此取名为年份。图 7 为转置后数据示例。
图 6. Transpose 节点
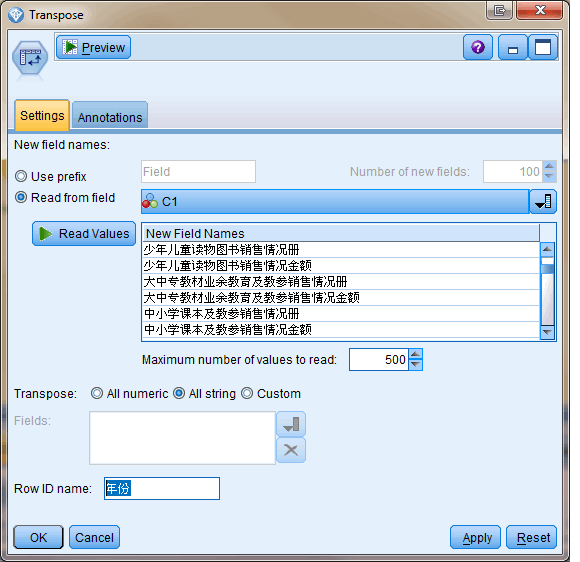
图 7. Transpose 节点
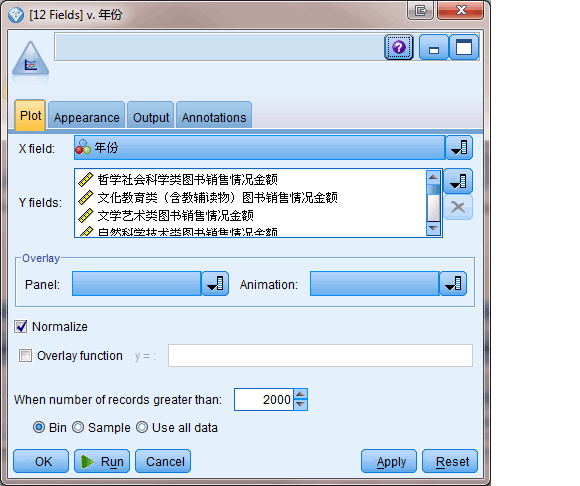
数据准备好后,连接上 Multiplot 节点,如图设置年份为 X 轴,各图书分类的销售金额为 Y 轴,并将 Normalize 选中。关于这个 Normalize 选项,在帮助文档中对其是如下描述的: 选中此选项可将所有 Y 值都定标到在图形的 0 – 1 范围内显示。标准化有助于研究多条线之间的关系,如果不使用标准化,这种关系可能由于每个系列的值范围的差异而变得不明显,建议在同一个图形中绘制多条线时或比较并行面板中的散点图时使用标准化选项
图 8. Multiplot 节点
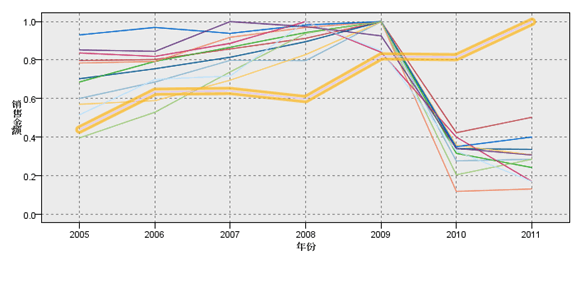
设置完成后,运行得到图 9 所示结果,其中黄色高亮选中的线代表的图书类别为电子出版物。在 2010 年除了此类别外,其他所有的图书分类销售金额由于整体经济环境的影响都有明显下滑,仅此类保持了上升的趋势。再使用相同方法分析历年销量时,也可看到类似结果。再回头看看前面图 4 与图 5 的分布,可以发现电子出版物占比其实很小,不仔细看几乎都找不到它。综合考虑下来,我们可以说电子出版物不仅发展势头良好,而且发展空间也很大。这与我们的生活步入数据时代的趋势是一致的。
图 9. 售金额历年变化情况
图书分类均价分析
接下来,我们将各类图书的整体销量与销售金额处理后进行分析。如前图 4 和图 5 所示,同一类图书的销售金额与销量占比是不同的,所以在此引入图书分类的均价,计算公式为:销售金额 / 销量。然后分析每类图书均价的历年变化情况,及各类图书均价之间的对比关系。 继续使用转置后的数据,在 IBM SPSS Modeler 中使用 Derive 节点利用计算公式给每个图书分类生成均价,然后将原销量及销售金额数据都过滤掉。然后还是使用 Multiplot 节点对各图书分类进行分析。此处我们可以顺便对比一下使用与未使用 Normalized 选项的效果。如图 10 为未使用 Normalized 选项的结果,由于红色的单价在 2010 年比其他的图书都高出很多导致纵轴拉长,所以单价较低的其他图书随年份的变化趋势看起来很不明显。图 11 为使用 Normalized 选项的结果,跟图 11 对比起来,每类图书的变化趋势都比较明显了。
图 10. 均价历年变化情况 – 未使用 Normalized 选项
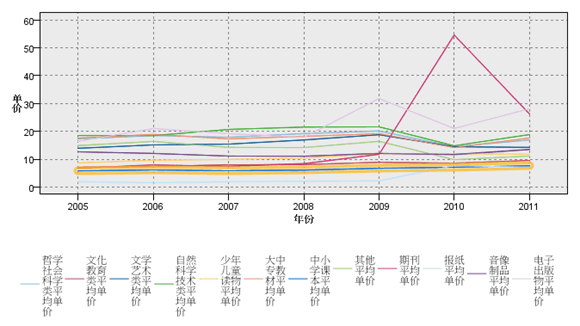
图 11. 均价历年变化情况 – 使用 Normalized 选项
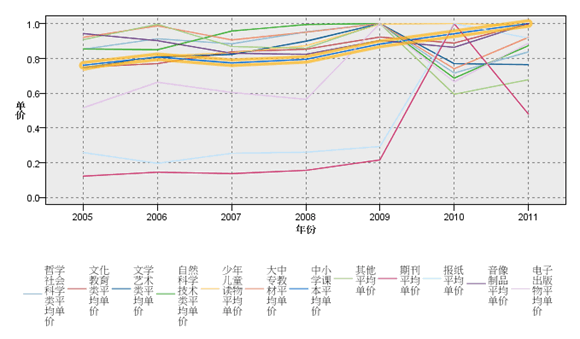
现在关注一下两图中高亮选中的线,其代表的图书类别为中小学课本及教参。从图 10 看到,这一类别的图书均价仅比报纸高,说明中小学所用的图书价格还是很配合义务教育这个基本方针的。但是从图 11 可以发现,这一类别的价格在缓慢上升,即使是 2010 年其他图书分类均价大部分在下降时也是如此。 更明显地,在 2010 年均价变化异常的还有两类,分别为期刊与报纸,从 2009 年起价格可以用暴涨来形容,到 2011 年有所回落。这一现象后面包含的商业竞争信息及原因在互联网上有很多,这里不再引用。
数据地图分析
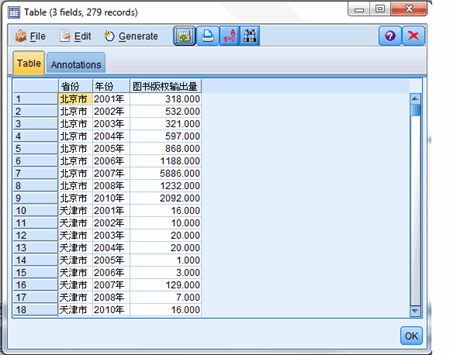
在商业数据分析中,有大量数据是与地理位置相关的,例如各区域的销售额和利润数据等。这种情况下,如果能采用数字地图这种全新的形式来反映这些数据,无疑会比单纯的表格要直观形象得多,信息沟通将更加有效,也更具专业的品质和形象。自然国家图书出版社会有大量来自全国各地的各类与图书相关的数据,在此我们就需要分地域来分析这些图书数据。IBM SPSS Modeler 15.0 中也实现了统计地图的功能。基于这个新功能我们将分析近几年全国一些省份传统图书行业的出版数据。图示为近几年全国图书版权的输出情况一览表。
图 12. 近几年全国各省份图书出版情况

图 12 展示给我们的是最原始的数据,为了做数据地图分析,首先我们需要把这些原始数据转换成我们想要的数据结构,这一步可以通过 IBM SPSS Modeler 中的 Transpose 节点 ( 如图 6 所示 ) 实现,也可以通过 EXCEL 里的 Transpose 功能来实现,此方法在这里就不过多描述了,下面是转置后的数据结构,以北京市,天津市的数据为例。
图 13. 北京市、天津市近几年图书出版情况
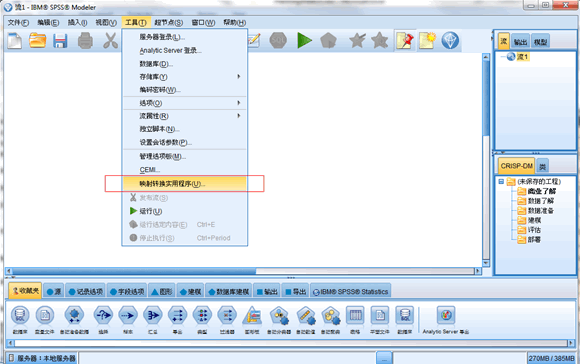
大家不难发现上面的原始数据图表中没有统计到中国所有的省份,当我们需要考虑地理信息呈现数据的时候,相信大部分的地图都是全球或者全国地图,不一定适用于每组数据,但 IBM SPSS Modeler 15 集成了地图转换程序,可以根据需要合并、移动、删除部分区域,制定自己想要的地图。下面我们就来简单了解一下这个地图转换实用程序。图示为如何在 IBM SPSS Modeler 中打开地图转换实用程序,即从菜单中选择“工具”选项,然后选择“地图转换实用程序”。
图 14. 地图转换实用程序的打开方式
在地图转换实用程序中有四个主要步骤。它们还分别包含相应的子步骤,以便详细控制对地图文件的编辑操作,为了易于理解下面分别贴出相应四个步骤的截图。
第 1 步:选择目标和源文件
您首先需要选择源地图文件和转换后地图文件的目标位置。这里需要注意的是,对于 shapefile,您将同时需要 .shp 和 .dbf 文件。shapefile 的 .dbf 文件必须存储在与 .shp 文件相同的位置,并且二者的基本文件名应相同。需要 .dbf 文件,因为它包含 .shp 文件的属性信息。
图 15. 步骤 1 – 选择源文件

第 2 步:选择地图关键字
现在,您将选择要在 SMZ 文件中包括哪些地图关键字。然后,您可以更改一些会影响地图呈现的选项。在地图转换实用程序的后续步骤中包含预览地图。您选择的呈现选项将用于生成地图预览。
图 16. 步骤 2 – 选择地图键

第 3 步:编辑地图
现在,您已指定了地图的基本选项,还可以编辑更多特定选项。这些修改是可选的。地图转换实用程序的该步骤将引导您完成相关任务,并显示地图预览,以便验证您的更改。根据形状类型(点、多义线或多边形)和坐标系统,某些任务可能不可用。 默认情况下,在预览中不显示特征标签。您可以选择显示这些标签。尽管标签可以帮助识别特征,但它们可能干扰在预览地图上直接选择。请在需要时打开此选项,例如当您编辑特征标签时。 默认情况下,预览地图将以一种纯色显示各个分区。所有特征具有相同颜色。您可以选择为每个地图特征指定相应的颜色。此选项有助于区分地图中的不同特征。当您合并特征,并想要查看在预览中如何表示新特征时,这非常有用。
图 17. 步骤 3 – 编辑地图
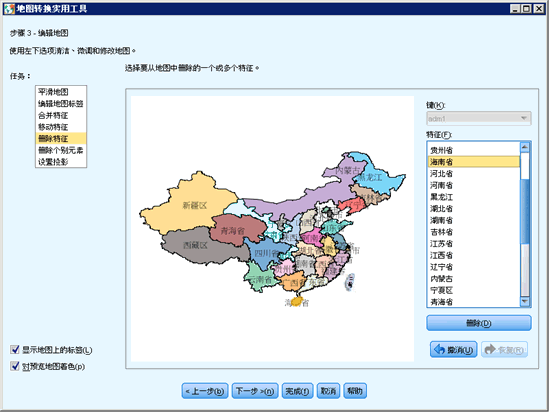
第 4 步:完成地图转换
在这一步中,您可以添加注释以描述地图文件,或者向用户提供更多相关信息,例如原始 shapefile 来源。该注释将出现在图形画板模板选择器的管理系统中。还可从地图关键字创建样本数据文件。如果在地图文件中存在多个关键字,则选择您要在预览中显示其特征标签的地图关键字。如果您从地图创建数据文件,这些标签将用于数据值。如果您要从显示的特征标签创建文本数据文件,选中此选项。在单击浏览…后,您可以指定位置和文件名。如果添加了 .txt 扩展名,则文件将保存为制表符分隔值文件。如果添加了 .csv 扩展名,则文件将保存为逗号分隔值文件。在未指定扩展名时,CSV 为默认值。
图 18. 步骤 4 – 完成地图转换
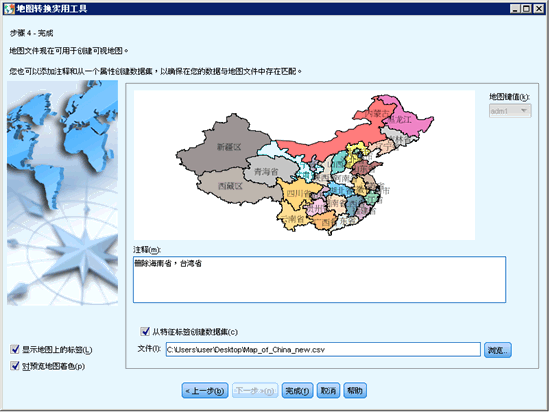
这样一张新的地图就生成了。基于第三步的操作“删除特征”,我们顺利地从中国地图中删除掉了海南省 , 台湾省(由于这两个省份近几年图书出版量数据缺失比较严重)。用户根据第三步的其他几个特征也很容易对一张地图实现其他简单操作。
下面我们就用准备好的数据结合 IBM SPSS Modeler 中的 Graphboard 节点来分析各个省份图书的出版情况。图示为 Graphboard 节点中的基本选项卡。在此选择数据后,右边即会显示适合所选数据的所有直观表示类型。
图 19. Graphboard 节点中的基本选项卡
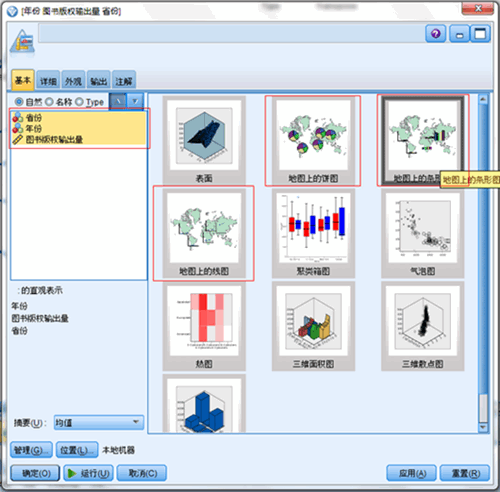
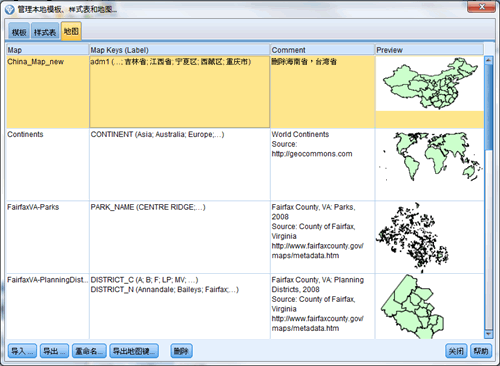
对于许多直观表示,您只需作出两项选择:感兴趣的字段和直观表示这些字段的模板,无需其他选择或操作。而地图直观表示另外还需要至少一个步骤,那就是选择用于定义地图直观表示的地理信息的地图文件,及我们前面讲到的制作完成的转换后的地图文件。当然我们首先需要管理此地图文件并把它导入到 IBM SPSS Modeler 中,如下图所示。
图 20. 将地图文件 Map_of_China_new 导入 SPSS Modeler 中
准备好了数据和地图模板我们就来看看几种展示全国各省份近几年图书的出版情况的地图数据。
图 21. 各省份近几年图书出版情况之“地图上的条形图
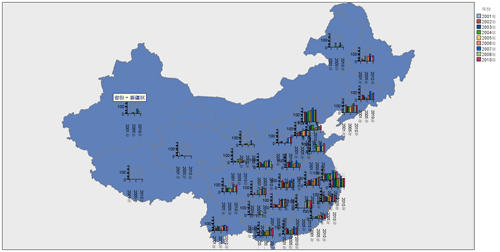
从此图中我们能明显的看到北京市历年来图书出版情况一直是遥遥领先于其他省份,尤其突出的是蓝色柱状图代表的 2007 年,几乎快要达到 6000 本。地图上的条形图体现的是各个省份,各个年份之间,在其数量上的一个比较,由于一些省份在某些年份没有出版,或者出版数量极少,所以我们在某些省份的地图上看不到条形图。
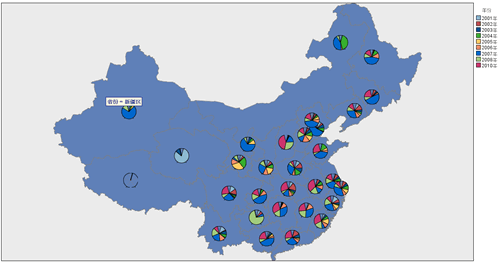
看到这里就会有人问了,如果我不关心各个省份之间图书出版量的比较,只想关注各个省份在近几年哪一年的图书出版量比较大,哪一年比较小要怎么做呢,这里我们就将介绍一种地图上的饼状图,如下图所示,我们能很快看出每个省份近几年图书出版量的一个大致比例,也就是说它能很好的回答上面这个问题。
图 22. 各省份近几年图书出版情况之“地图上的饼图
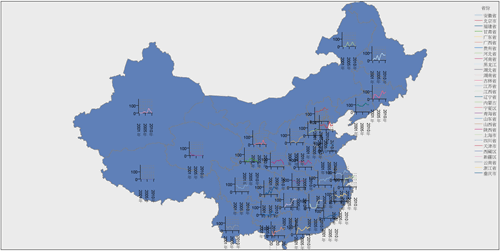
最后我们再展示一种地图上的线图,它在反映各个省份近几年图书出版量情况的基础上体现的是每一年较上一年图书出版量增长或减少的趋势。如下图所示。
图 23. 各省份近几年图书出版情况之“地图上的线图
小结
到此,基于 IBM SPSS Modeler 的一些分析方法,我们对已有的数据进行了初步的整理分析。就如在实际数据挖掘项目中一样,在最后使用各种模型或者算法进行建模之前,往往需要对数据做探索性了解, IBM SPSS Modeler 的图形功能可以很方便地展示数据结构,对数据的探索起到事半功倍的效果。本文主要关注如何使用 IBM SPSS Modeler 进行数据分析及展示,故没有涉及对未来趋势的预测,有兴趣的读者可以在此基础上做进一步研究。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e4%bd%bf%e7%94%a8-ibm-spss-modeler-%e5%88%86%e6%9e%90%e8%bf%91%e5%b9%b4%e5%9b%be%e4%b9%a6%e8%a1%8c%e4%b8%9a%e6%83%85%e5%86%b5/
注意:本文归作者所有,未经作者允许,不得转载

