sklearn中的sk代表着scikit,就可以知道这是一个用于科研的工具包了,那么这个科研工具包种都包含了哪些内容呢? 下面这个图描述了sk-learn所覆盖的领域。

分类、聚类、回归和降维,基本的数据算法需求均有所覆盖,下面我们就跟着这个地图探究下sk-learn的功能吧。
- 检查数据样本量,如何小于50个赶紧收集更多的数据吧;
- 然后看任务目标,如果是
预测一个种类,并且拥有标注的数据,那么这就是一个分类任务;如果没有标注数据,那么这就是一个聚类任务。 - 如果任务目标是
预测数值,那么这就是个回归任务; - 如果任务目标则只是更好的观测数据,那么这是个降维任务,
- 如果以上都不是,那么目标就只能是结构预测了,而这是个困难任务。
通过这个地图基本上覆盖了sk-learn的四个主要算法,从上面的地图来看,sklearn对数据集的要求非常严格,往往是特定的数据只能进行特定的任务,那么在进一步看这四部分算法之前,先了解下sklearn中的数据集吧。
数据集/dataset
sklearn中自带了各种各样的数据集来满足不同的任务需求,例如使用iris数据进行分类任务。了解sklearn所有的数据集是不现实的,但还是有必要了解各个任务的典型数据集,以更好的完成之后的实验。
导入数据集
1 2 3 4 5 6 |
import numpy as np from sklearn import datasets iris = datasets.load_iris() print(type(iris)) # sklearn.datasets.base.Bunch print(iris.keys()) # dict_keys(['target', 'feature_names', 'DESCR', 'target_names', 'data']) |
可以看出来iris是一种封装起来的数据格式,使用方式和python内置的字典样式类似,而具体的数值如iris["data"]则是numpy.array数据类型,所以如果需要操作数据集,还需要了解下numpy的相关api。
分类/classification
分类的核心目的是给定一个样本的数据观测,根据一个数据模型得出预测该样本属于哪个类别。从这个定义可以看出:
- 分类需要有已知固定的类别
- 需要一个数学模型,这个数学模型就似乎分类任务的关键。
平时说训练分类,就是要得到这样一个数学模型。和训练相对的一个阶段就是评估,在sk-learn过程中也不例外,进行分类训练的时候也是会涉及到这一过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import numpy as np from sklearn import datasets from sklearn.cross_validation import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import Perceptron from sklearn.metrics import accuracy_score iris = datasets.load_iris() X = iris.data[:,[2,3]] y = iris.target # 处理数据集,得到训练集和测试集。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 对特征数据进行标准化处理 sc = StandardScaler() sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) # 训练分类器 ppn = Perceptron(n_iter=40, eta0=0.1, random_state=0) ppn.fit(X_train_std, y_train) # 预测并评估分类器性能 y_pred = ppn.predict(X_test_std) acc_score = accuracy_score(y_test, y_pred) |
这就完成了一个分类任务的标准流程,后续就可以根据训练得到的分类器ppn对目标分类。
这里使用的分类算法是感知机算法Perceptron,而在sklearn种自带了很多种分类算法,这个时候就是考验使用者的时候了,需要结合现有数据的特点和各个分类算法的适用范围来选择合适的算法。不仅仅分类算法是这样,其他的几大类算法领域也是如此。上面的算法选择地图只是对于我们算法选择做了初步的指导,更多的时候还是需要结合经验和理论来选择合适的算法。
聚类/cluster
分类是将利用已经标注的信息训练出一个数据模型/分类器,后续适用分类器判别未定样本的类别。而聚类的逻辑和流程不同,一般的聚类任务是不知道样本的类别的,而要根据样本在数据特征空间的相似性对样本进行归类,找到样本的归属。
sklearn中也包含了多种的聚类算法,其中就包含了经典的K-Means聚类算法,下面就假定不知道iris的类别数据,使用该聚类算法对目标数据进行处理,得到不同样本之间的归类关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from sklearn import datasets import numpy as np from sklearn.cluster import KMeans iris = datasets.load_iris() original_x = iris.data # 特征转换,使用加和的方式将样本空间从4维转换为2维(以方便在2维平面上展示结果) datas = original_x[:, :2] + original_x[:, 2:] # 设定聚类模型参数,并进行训练 kmeans = KMeans(init="k-means++", n_clusters = 3) kmeans.fit(datas) # 在kmeans中就包含了K均值聚类的结果:聚类中心点和每个样本的类别 labels = kmeans.labels_ centers = kmeans.cluster_centers_ |
使用matplotlib可以将聚类的结果可视化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
from matplotlib import pyplot as plt #计算每一类到其中心距离的平均值,作为绘图时绘制圆圈的依据 distances_for_labels = [] for label in range(kmeans.n_clusters): distances_for_labels.append([]) for i, data in enumerate(datas): label = kmeans.labels_[i] center = kmeans.cluster_centers_[label] distance = np.sqrt(np.sum(np.power(data - center, 2))) distances_for_labels[label].append(distance) ave_distances = [np.average(distances_for_label) for distances_for_label in distances_for_labels] #绘图 fig, ax = plt.subplots() ax.set_aspect('equal') #设置坐标范围 ax.set_xlim((x_min, x_max)) ax.set_ylim((y_min, y_max)) #绘制每个Cluster for label, center in enumerate(kmeans.cluster_centers_): radius = ave_distances[label] * 1.5 ax.add_artist(plt.Circle(center, radius = radius, color = "r", fill = False)) #根据每个数据的真实label来选择数据点的颜色 plt.scatter(datas[:, 0], datas[:, 1], c = iris.target) plt.show() |
得到可视化的结果如下所示:
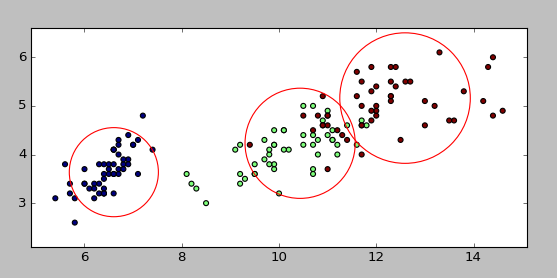
对于样本的分类如上图所示,不同的颜色代表不同的样本。 就如同分类算法可以预测未知数据的分类,聚类算法同样可以预测未知数据的类别。给定新的样本数据,比较距离已知分类中心的距离,就可以预测该样本的列别。
和分类算法相同,也有各种各样的聚类算法,其中各种算法也各有差异和特异性。例如KMeans算法就需要指定赝本的类别数量,如果指定的类别数值等同于真实类别,会显著的提升结果的准确度和可解释性。而有的聚类算法可能对初始类别值不敏感,所以同样需要根据数据特征和研究目的,结合各个算法的特性来选择合适的聚类算法。
回归/regression
回归,在高中数学中已经有所涉及。
回归分析:对具有相关关系的两个变量之间的关系形式进行测定,确定一个相关的数学表达式,以便进行估计预测的统计分析方法
这个定义已经很好的诠释了回归的用处。从某种意义分类和回归是具有一定的相似性的,都是根据一些列变量来推测出另外变量的值,只不过分类是离散的,而一般意义上的回归是连续的(逻辑回归也算是分类的一种)。我们看个利用简单线性回归预测房价的的例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from sklearn import datasets from sklearn import linear_model boston = datasets.load_boston() y = boston.target lr = linear_model.LinearRegression() lr.fit(boston.data, y) predict_y=lr.predict(boston.data[2]) print(predict_y) # array([ 30.5702317]) # 可以查看计算得到的回归模型参数 lr.coef_ |
这样我们完成了最基本的回归过程,得到了一个可以预测波士顿房价的数学模型。
降维/decomposition
在网络上找到一张图,可以很好的说明降维技术的重要意义。

上面四张图分别展示了一个水壶,水壶本身是三维立体的,拍摄称图片后就变成了二位平面了,这个拍摄过程就是一种降维。再看这四张图,单独通过图一、图二以及图三很难获取到水壶的整体信息,而仅通过图四就可以知道这个水壶的特征。在降低样本数据维度的同时,尽量减少整体信息的损失,这就是降维技术核心价值。
同样针对不同的数据集也发展处理多种降维技术,例如PCA(Principal Component Analysis)、LDA(Linear Discrimination Analysis)等。 下面展示下如何将iris的4维数据进行PCA降维到2维。
1 2 3 4 5 6 7 8 9 10 |
from sklearn.decomposition import PCA from sklearn.datasets import load_iris iris = load_iris() X = iris.data pca = PCA(n_components=2) reduced_X = pca.fit_transform(X) X.shape # (150, 4) reduced_X.shape # (150, 2) |
上面可以看出,已经样本的数据维度降低到了2维,从而可以使用图片来展示降维后的样本。根据肉眼还是可以这三种iris在降到2维之后也能够明确的区分。

特征提取/feature_extraction
现在有一个任务,需要判断一句话是否为脏话。假定训练集和测试集如下:
1 2 3 4 5 6 7 8 |
训练集 是脏话:fuck you 是脏话:fuck you all 不是脏话:hello everyone 测试集: fuck boy hello girl |
如何来完成这样一个分类的任务?
关于文本分类可以用很多中方式如逻辑回归等,但是目前的输入内容为文本,并不能直接用于模型中,所以需要进行特征处理。sklearn中也内置了多种特征处理的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model.logistic import LogisticRegression X = [] # 输入训练样本 X.append("fuck you") X.append("fuck you all") X.append("hello everyone") # y为训练样本标注 y = [1,1,0] # 输入测试样本 T = ["fuck boy","hello girl"] vectorizer = TfidfVectorizer() X_train = vectorizer.fit_transform(X) T_test = vectorizer.transform(T) # 用逻辑回归模型做训练 classifier = LogisticRegression() classifier.fit(X_train, y) # 做测试样例的预测 predictions = classifier.predict(T_test) print(predictions) # [1,0] |
通过特征提取,就将文本数据转化特征数据,从而可以使用逻辑回归的方式解决这个判断问题。
小结
跟着sklearn的一张数据算法地图,了解了sklearn进行数据建模分析的主要领域以及各自的使用方法,并且通过代码完成实现了特定的目标。但是在真正的分析过程中会碰到各种各样的困难,例如如何业务建模、如何特征优化,如何解决数据量和模型效果之间的矛盾等等。
千里之行始于足下,只能用这一双脚来趟遍所有的雷。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/sklearn%e5%85%a5%e9%97%a8%e6%95%99%e7%a8%8b%ef%bc%9a%e5%88%86%e7%b1%bb%e3%80%81%e8%81%9a%e7%b1%bb%e3%80%81%e5%9b%9e%e5%bd%92%e5%92%8c%e9%99%8d%e7%bb%b4/
注意:本文归作者所有,未经作者允许,不得转载

