from https://zhuanlan.zhihu.com/p/30221526
基于Iris数据集的机器学习实践
Iris数据集简介
iris数据集由Fisher, 1936收集整理,Iris也称安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。Iris数据集是常用的分类实验数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于Setosa,Versicolour,Virginica三个种类中的哪一类。
用户可通过链接http://aima.cs.berkeley.edu/data/iris.txt 查看iris数据集的详细介绍了解更多信息。

用户可以从 http://aima.cs.berkeley.edu/data/iris.csv下载该数据集,另外,python的数据挖掘/机器学习库scikit已经内置了iris数据集。

分类算法
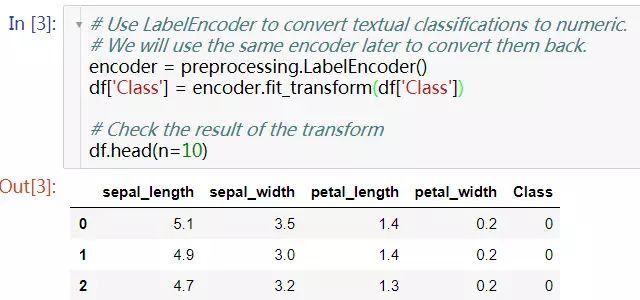
1. 我们选用jupyter notebook作为实验平台,数据集采用从上面链接下载的csv文件,添加列名以便于操作。csv文件的Class列有三类值Setosa,Versicolour,Virginica,因此这是一个多分类的问题。首先我们要将Class列转换为数值型字符。
2. 对数据进行标准化预处理,数据交叉验证采用sklearn 包中的 StratifiedKFold 方法,StratifiedKFold 是一种将数据集中每一类样本的数据成分,按均等方式拆分的方法,使用准确率作为评价模型好坏的标准。

3. 接下来分别使用SVM, 逻辑回归分类器,朴素贝叶斯三种分类算法进行验证


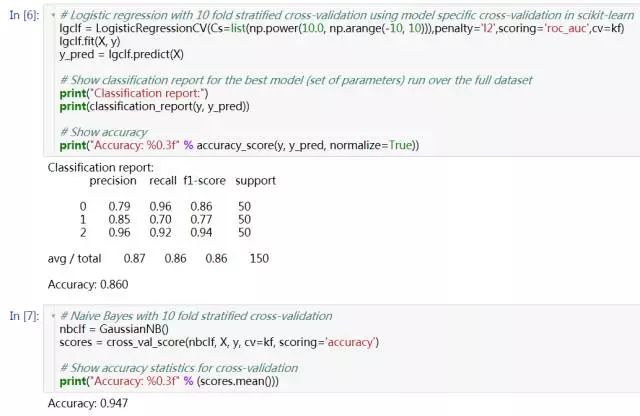
得到准确率分别是:SVM 0.987, 逻辑回归 0.860,朴素贝叶斯 0.947,就是你了SVM!
发布函数
首先运行startup.bat(Mac下为startup.sh)启动tabpy_server 服务器

接下来需要创建一个到tabpy server的连接对象

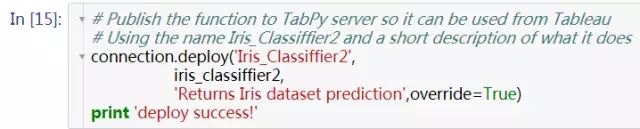
定义我们要发布的函数名称,参数,以及返回对象

然后将方法发布到tabpy server上
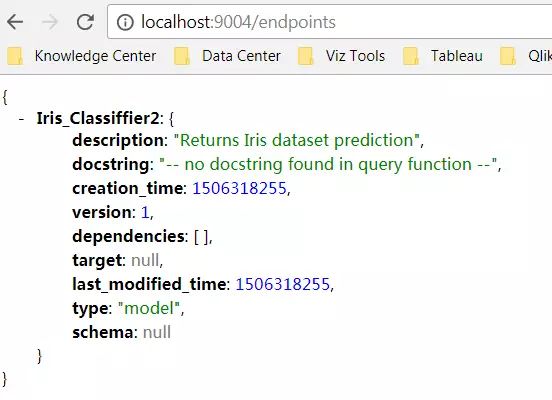
最好再去 localhost:9004/endpoints 下确认一下方法已经发布到了tabpy server上。如果没有问题,我们就可以进入到下一阶段,去创建Tableau dashboard了,Cheers!
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/tableau%e9%9b%86%e6%88%90python%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a0%e5%ae%9e%e8%b7%b5%ef%bc%88%e4%b8%ad%ef%bc%89/
注意:本文归作者所有,未经作者允许,不得转载


