版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
为什么要降维?
建模初期,我们往往只有几个指标,这个时候不太涉及到降维,但是一个月后你就发现,模型的指标越来越多,从原有的五六个指标一步一步变成 100 个指标。100 个很多吗?不多!但是以后呢?两个月过去可能会变成 500 个,三个月过去就会超过 1000 个,以后还会更多!
我们一边惊讶着,一个模型竟然可以有这么多指标,一边也在抓耳挠腮,这么多指标里面,肯定有冗余,怎么找出他们?总不能一个一个分析吧……所以需要更高效快捷的方法来处理高维数据,比如降维(减少指标数量的同时,避免丢失太多信息、改进模型性能的方法)。
降维的好处:
- 减少数据存储所需的空间,节约成本。
- 减少数据处理与建模的时间,提高效率。
- 提高算法的性能(一些算法在高维度数据上容易表现不佳)。
- 解决多重共线性问题。
- 有助于数据可视化(绘制二维三维数据图表比较简单)
以下一共12种方法,每种方法里的代码都是相对独立的,如果需要原数据练习的话,欢迎关注博主,并下方留言已关注+邮箱,博主会尽快回复邮件。
降维方法
先来看看原数据吧(已脱敏),这是我的习惯,知道要处理的是什么数据有助于理解接下来的方法。
11528 行数据中,第一列是因变量(y_增长率),余下的所有列为自变量(x1…x100),共 100 个自变量。

1.缺失值比例(高:删!)
学校做课题时拿到的数据,缺失值是相对较少的,但是在工作中,缺失值的比例简直让人瞠目结舌,高于 80% 都司空见惯了。当缺失值比例过高时,代表它包含的可用信息太少了,一般会设置一个阈值,缺失值比例高于阈值的特征便删掉。
Python 代码:
import pandas as pd
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
a = data_fea.isnull().sum()/len(data_fea)*100 #缺失值比例
cols = data_fea.columns# 列名
col = [ ]
for i in range(0,100):
if a[i]<=50: #缺失值阈值为50%
col.append(cols[i])
print("缺失值低于阈值的特征共%d个;"%len(col),"\n它们分别是:", col)
输出:
缺失值低于阈值的特征共73个
它们分别是: ['x1', 'x2', 'x3', 'x6', 'x8', 'x9', 'x10',
'x11', 'x12', 'x13', 'x14', 'x15', 'x16', 'x17', 'x18',
'x19', 'x20', 'x21', 'x25', 'x26', 'x27', 'x28', 'x29',
'x30', 'x31', 'x32', 'x33', 'x38', 'x43', 'x52', 'x53',
'x54', 'x55', 'x56', 'x57', 'x58', 'x59', 'x60', 'x61',
'x62', 'x63', 'x64', 'x68', 'x69', 'x70', 'x73', 'x74',
'x75', 'x76', 'x77', 'x78', 'x79', 'x80', 'x81', 'x82',
'x83', 'x84', 'x85', 'x86', 'x87', 'x88', 'x89', 'x90',
'x91', 'x92', 'x93', 'x94', 'x95', 'x96', 'x97', 'x98',
'x99', 'x100']2.方差(低:删!)
若某一个特征中的数据基本一致,代表这一特征对因变量 y 的解释能力是比较低的,因此我们认为这种特征包含的可用信息也很少。特征中的数据基本一致的直接表现就是方差比较小。
在实际应用中,不同特征的数据范围是不一样的,有 [ 0, 1 ] 的,也有 [ 1, +∞) 的,因此通过这种方法降维之前一定要先对数据进行归一化处理(归一化与标准化不同,具体查看下面链接里的这篇文章)。
Python 代码:
import pandas as pd
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
#归一化
data_fea = data_fea.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
var = data_fea.var()#获取每一列的方差
cols = data_fea.columns
col = [ ]
for i in range(0,len(var)):
if var[i]>=0.001: # 将阈值设置为0.001
col.append(cols[i])
print("高于阈值的特征共%d个;"%len(col),"\n它们分别是:", col)
输出:
高于阈值的特征共69个;
它们分别是: ['x1', 'x2', 'x3', 'x4', 'x5', 'x6',
'x7', 'x8', 'x10', 'x11', 'x12', 'x13', 'x14',
'x15', 'x16', 'x17', 'x18', 'x19', 'x20', 'x21',
'x22', 'x23', 'x24', 'x25', 'x26', 'x27', 'x28',
'x29', 'x30', 'x31', 'x32', 'x33', 'x39', 'x40',
'x41', 'x42', 'x43', 'x45', 'x47', 'x51', 'x52',
'x53', 'x54', 'x55', 'x66', 'x67', 'x68', 'x69',
'x70', 'x73', 'x75', 'x76', 'x79', 'x80', 'x81',
'x82', 'x83', 'x84', 'x85', 'x86', 'x87', 'x93',
'x94', 'x95', 'x96', 'x97', 'x98', 'x99', 'x100']3.相关性矩阵(高:保留其一!)
如果两个特征的相关度较高,说明这两个特征携带的信息是高度相似的,过多的相似特征会降低某些算法的性能,比如逻辑回归(Logistic Regression)和线性回归(Linear Regreesion)。因此,一般会设置一个阈值,相关度高于阈值的特征只保留其中一个。
在下例中,因为特征数量较多,不便于展示,所以我们只选取 ‘x91’, ‘x92’, ‘x95’, ‘x96′,’ x97′ 这五个特征进行相关度计算。
import pandas as pd
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
data_fea = data_fea.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))#归一化
cor = data_fea[['x91', 'x92','x95','x96','x97',]].corr()#选取部分特征计算
# cor = data_fea.corr() #全部特征计算
cor输出:
x91 x92 x95 x96 x97
x91 1.000000 0.897225 -0.086567 -0.102104 -0.099413
x92 0.897225 1.000000 -0.080699 -0.093550 -0.106207
x95 -0.086567 -0.080699 1.000000 0.844717 0.724978
x96 -0.102104 -0.093550 0.844717 1.000000 0.841306
x97 -0.099413 -0.106207 0.724978 0.841306 1.000000选取的五个特征中,’x91′ 与 ‘x92’ 的相关度达0.89,高相关,保留其一即可,其他同理。
0~0.3 弱相关
0.3~0.6 中等程度相关
0.6~1 强相关
4.随机森林(低:删!)
随机森林是一种广泛使用的特征选择算法,RandomForestRegressor 模块中的 feature_importances_ 函数会自动计算各个特征的重要性,因此大大降低了编程的难度。之后再根据特征间的相对重要性选择指标即可。
需要注意的是,随机森林只接受数字,不接受空值、逻辑值、文字等其他类型,因此需要先填充空值,转化特征值等。
Python 代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
model = RandomForestRegressor(random_state=1, max_depth=10)
data_fea = data_fea.fillna(0)#随机森林只接受数字输入,不接受空值、逻辑值、文字等类型
data_fea=pd.get_dummies(data_fea)
model.fit(data_fea,data.y_增长率)
#根据特征的重要性绘制柱状图
features = data_fea.columns
importances = model.feature_importances_
indices = np.argsort(importances[0:9]) # 因指标太多,选取前10个指标作为例子
plt.title('Index selection')
plt.barh(range(len(indices)), importances[indices], color='pink', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative importance of indicators')
plt.show()输出:
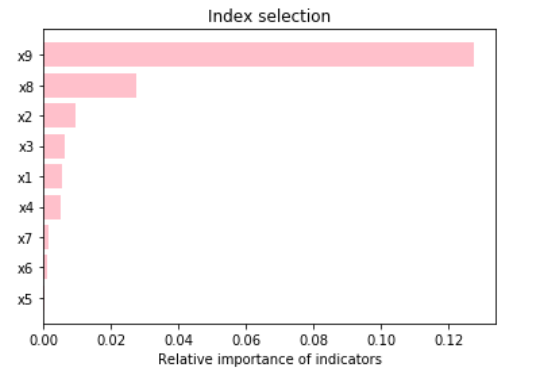
5. 反向特征消除
反向特征消除是指先选择全部的特征进行建模,再根据模型评价指标,逐步删除特征。
步骤:
- 获取数据集中的全部 100 个特征和因变量( y_增长率)。
- 使用特征与因变量训练模型(逻辑回归 or 线性回归 or ……)。
- 计算模型评价指标(召回率、精确率、F1值、准确率)。
- 删除第 i 个特征后,用剩下的 99 个特征训练模型,并计算模型评价指标。
- 比较两次的评价指标,若评价指标提高,则删除第 i 个特征。
- 循环 4 ~ 5 过程,直到模型评价指标不再明显增加。
步骤很清晰,至于代码,根据下面链接中的建模代码、模型评价指标计算,再自己写一个循环就成。
逻辑回归:逻辑回归sklearn – (LR、LRCV、MLP、RLR)Python代码实现;
线性回归:多元线性回归 – 一步一步详解 – Python代码实现;
评价指标:召回率(Recall)、精确率(Precision)、F1 值(F-Measure)、准确率(Accuracy)的原理与 Python 代码实现
6. 前向特征选择
前向特征选择是相对反向特征消除而言的,前向特征选择并不是一开始就选择所有的特征,而是先选择最优的单个特征,再根据模型评价指标,逐步增加特征,直到召回率、精确率等评价指标不再提高为止。
步骤:
- 将每个特征与因变量 y 训练模型,得到 100 个模型 与 100 个模型评价指标。
- 选择模型评价指标最高的特征作为已入选特征。
- 添加一个特征到已入选特征中继续训练模型。
- 根据模型评价指标,选择第二个入选的特征,加入到已入选特征中。
- 循环 3 ~ 4 过程,直到模型评价指标不再明显增加。
import numpy as np
import pandas as pd
from sklearn.feature_selection import f_regression
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
data_fea = data_fea.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))#归一化
fr = f_regression(data_fea,data.y_增长率)
cols = data_fea.columns
col = [ ]
for i in range(0,len(cols)-1):
if fr[0][i] >=10:
col.append(cols[i])
print("高于阈值的特征共%d个;"%len(col),"\n它们分别是:", col)
输出:
高于阈值的特征共53个;
它们分别是: ['x1', 'x2', 'x4', 'x5', 'x6', 'x7',
'x9', 'x10', 'x11', 'x12', 'x13', 'x16', 'x18',
'x19', 'x20', 'x21', 'x22', 'x23', 'x24', 'x26',
'x27', 'x28', 'x34', 'x35', 'x36', 'x37', 'x38',
'x39', 'x40', 'x41', 'x42', 'x43', 'x44', 'x45',
'x46', 'x47', 'x48', 'x49', 'x50', 'x51', 'x52',
'x53', 'x54', 'x55', 'x66', 'x67', 'x69', 'x70',
'x71', 'x72', 'x73', 'x79', 'x80']注意:前向特征选择和反向特征消除需要循环建模,耗时较久,计算成本很高,所以只适用于特征较少的数据,超过 1000 个特征的数据就慎重了。
7.因子分析(Factor Analysis)
与前几种方法不同的是,因子分析并不是通过删除特征来降低冗余数据的影响,而是通过挖掘潜在因子,在不删除特征的前提下降低影响。一般情况下,潜在因子的个数是远少于特征个数的,但是其携带的信息并不比原特征的少。
还不太了解因子分析原理的同学,可以参考下面这篇博客:
Python 代码:
import numpy as np
import pandas as pd
from sklearn.decomposition import FactorAnalysis
#导入数据
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
#标准化
data_mean = data_fea.mean()
data_std = data_fea.std()
data_fea = (data_fea - data_mean)/data_std
#因子分析,并选取潜在因子的个数为10
FA = FactorAnalysis(n_components = 10).fit_transform(data_fea.values)
#潜在因子归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
FA = min_max_scaler.fit_transform(FA)
#绘制图像,观察潜在因子的分布情况
import matplotlib.pyplot as plt
plt.figure(figsize=(12,8))
plt.title('Factor Analysis Components')
plt.scatter(FA[:,0], FA[:,1])
plt.scatter(FA[:,1], FA[:,2])
plt.scatter(FA[:,2],FA[:,3])
plt.scatter(FA[:,3],FA[:,4])
plt.scatter(FA[:,4],FA[:,5])
plt.scatter(FA[:,5],FA[:,6])
plt.scatter(FA[:,6],FA[:,7])
plt.scatter(FA[:,7],FA[:,8])
plt.scatter(FA[:,8],FA[:,9])
plt.scatter(FA[:,9],FA[:,0])输出:

能不能找到10种颜色呢?哈哈,100 维到 10 维,没有删减特征,却成功降维啦!
8.主成分分析(PCA)
因子分析是假设存在一系列潜在因子,能反映变量携带的信息,本质是一种向下挖掘的方法。
而主成分分析PCA则是通过正交变换将原始的n维特征变换到一个新的被称做主成分的数据集中,本质是一种向上提取的方法。
主成分分析通过累计的解释方差之和来判断主成分对所有特征的解释程度。
Python 代码:
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
#导入数据
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
#标准化
data_mean = data_fea.mean()
data_std = data_fea.std()
data_fea = (data_fea - data_mean)/data_std
#选取主成分的个数为25
pca = PCA(n_components=25)
pca_result = pca.fit_transform(data_fea.values)
#绘制图像,观察主成分对特征的解释程度
plt.bar(range(25), pca.explained_variance_ratio_ ,fc='pink', label='Single interpretation variance')
plt.plot(range(25), np.cumsum(pca.explained_variance_ratio_),color='blue', label='Cumulative Explained Variance')
plt.title("Component-wise and Cumulative Explained Variance")
plt.legend()
plt.show()输出:
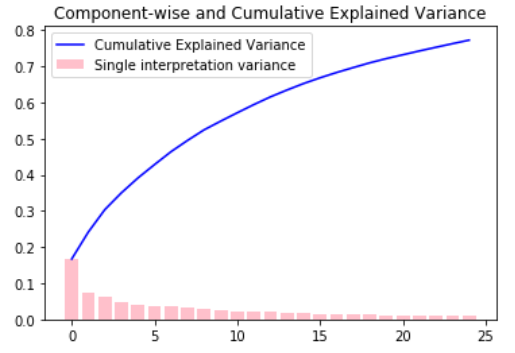
图中,粉色柱状图一共 25 个 柱子,代表提取的 25 个主成分,其高度代表每个主成分对方差的解释程度。
蓝色折线图代表 25 个主成分对方差的累计解释程度。我们可以看到,25 个主成分对 100 个特征方差的累计解释程度已经达到了80% ,因此这 25 个主成分携带了原始特征中的 大部分信息,成功降维!
9.独立分量分析(ICA)
PCA 和 ICA 之间的主要区别在于,PCA寻找不相关的因素,而ICA寻找独立因素。如果两个特征是独立的,就代表两者之间没有任何关系。例如,今天下不下雨和我工资多少无关。
Python 代码:
import numpy as np
import pandas as pd
from sklearn.decomposition import FastICA
import matplotlib.pyplot as plt
#导入数据
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
#标准化
data_mean = data_fea.mean()
data_std = data_fea.std()
data_fea = (data_fea - data_mean)/data_std
#独立分量分析(ICA)
ICA = FastICA(n_components=3, random_state=12)
X=ICA.fit_transform(data_fea.values)
#归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
X = min_max_scaler.fit_transform(X)
#绘制图像,观察成分独立情况
plt.figure(figsize=(12,5))
plt.title('Factor Analysis Components')
plt.scatter(X[:,0], FA[:,1])
plt.scatter(X[:,1], FA[:,2])
plt.scatter(X[:,2],FA[:,0])输出:
比我独立,满意!
10.manifold.Isomap
isomap算法主要流程:
- 构建邻接图G:基于输入空间X中流形G上的的邻近点对i,j之间的欧式距离dx (i,j),选取每个样本点距离最近的K个点(K-Isomap)或在样本点选定半径为常数ε的圆内所有点为该样本点的近邻点,将这些邻近点用边连接,将流形G构建为一个反映邻近关系的带权流通图G;
- 计算所有点对之间的最短路径:通过计算邻接图G上任意两点之间的最短路径逼近流形上的测地距离矩阵DG={dG(i,j)},最短路径的实现以Floyd或者Dijkstra算法为主。
- 构建k维坐标向量:根据图距离矩阵DG={dG(i,j)}使用经典Mds算法在d维空间Y中构造数据的嵌入坐标表示,选择低维空间Y的任意两个嵌入坐标向量yi与yj使得代价函数最小。
Python 代码:
import numpy as np
import pandas as pd
from sklearn import manifold
import matplotlib.pyplot as plt
#导入数据
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
#标准化
data_mean = data_fea.mean()
data_std = data_fea.std()
data_fea = (data_fea - data_mean)/data_std
#降维
trans_data = manifold.Isomap(n_neighbors=5, n_components=3, n_jobs=-1).fit_transform(data_fea.values)
#n_neighbors:决定每个点的相邻点数
#n_components:决定流形的坐标数
#n_jobs = -1:使用所有可用的CPU核心
#归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
trans_data = min_max_scaler.fit_transform(trans_data)
#绘制图像
plt.figure(figsize=(12,5))
plt.scatter(trans_data[:,0], trans_data[:,1])
plt.scatter(trans_data[:,1], trans_data[:,2])
plt.scatter(trans_data[:,2], trans_data[:,0])
输出:
运行耗时,降维效果差,不满意!
11.manifold.TSNE
Python 代码:
import numpy as np
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
#导入数据
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
#标准化
data_mean = data_fea.mean()
data_std = data_fea.std()
data_fea = (data_fea - data_mean)/data_std
#降维
tsne = TSNE(n_components=3, n_iter=300).fit_transform(data_fea.values)
#归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
tsne = min_max_scaler.fit_transform(tsne)
#绘制图像
plt.figure(figsize=(12,5))
plt.scatter(tsne[:,0], tsne[:,1])
plt.scatter(tsne[:,1], tsne[:,2])
plt.scatter(tsne[:,2], tsne[:,0])
输出:
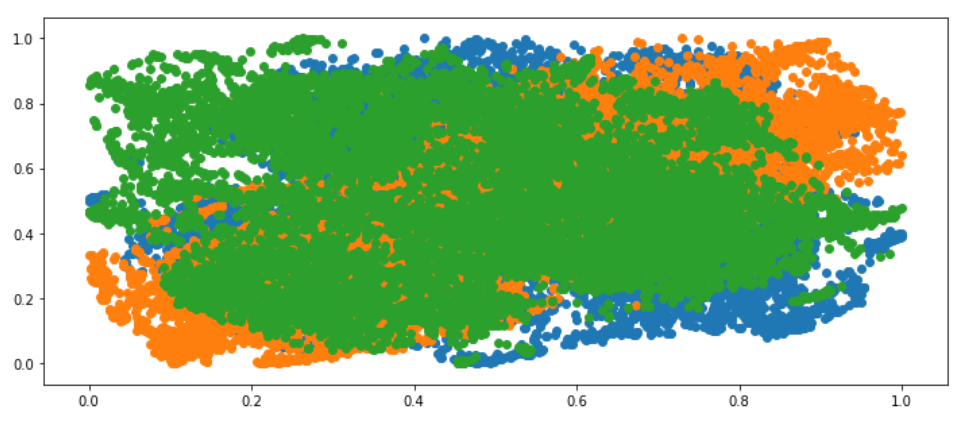
运行耗时,降维效果差,不满意!
12.UMAP
Python 代码:
import numpy as np
import pandas as pd
import umap
import matplotlib.pyplot as plt
#导入数据
datafile = u'D:\\pythondata\\learn\\dimensionality_reduction.xlsx'
data = pd.read_excel(datafile)
data_fea = data.iloc[:,1:]#取数据中指标所在的列
data_fea = data_fea.fillna(0)#填补缺失值
#标准化
data_mean = data_fea.mean()
data_std = data_fea.std()
data_fea = (data_fea - data_mean)/data_std
#降维
umap_data = umap.UMAP(n_neighbors=5, min_dist=0.3, n_components=3).fit_transform(data_fea.values)
#归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
umap_data = min_max_scaler.fit_transform(umap_data)
#绘制图像
plt.figure(figsize=(12,5))
plt.scatter(umap_data[:,0], umap_data[:,1])
plt.scatter(umap_data[:,1], umap_data[:,2])
plt.scatter(umap_data[:,2], umap_data[:,0])
运行耗时,不满意!不满意!不满意!
大总结
这么多中方法,总有各自的优缺点,下面总结一下:
其中耗时为100个特征,11528行数据的运行耗时。
| 降维方法 | 耗时 | 效果 | 信息丢失程度 | 适用维度 | 数据类型 | 特殊要求 |
| 缺失值比率 | 6.7s | 一般 | 根据数据而定 | 低维度 | ||
| 低方差滤波 | 5.9s | 一般 | 根据数据而定 | 低维度 | 线性 | |
| 高相关滤波 | 12.1s | 一般 | 较少 | 低维度 | 线性 | 与因子分析相反 |
| 随机森林 | 18s | 一般 | 一般 | 均可 | ||
| 反向特征消除 | 10.5s | 一般 | 较少 | 低维度 | ||
| 前向特征选择 | 9.9s | 一般 | 较少 | 低维度 | ||
| 因子分析 | 12.2s | 较好 | 几乎不丢失 | 均可 | 线性 | 特征间存在高度相关 |
| PCA | 8.8s | 较好 | 几乎不丢失 | 均可 | 线性 | |
| ICA | 6.8s | 一般 | 较少 | 均可 | ||
| ISOMAP | 96.6s | 较差 | 未知 | 未知 | 非线性 | |
| TSNE | 108.9s | 较差 | 未知 | 高维度 | 非线性 | |
| UMAP | 80.2s | 较差 | 未知 | 高维度 |
文中所说的反向特征消除与前项特征消除比较耗时是针对高维度数据来说了,根据实际情况,在低维度数据中,两种方法并没有很耗时。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e9%99%8d%e7%bb%b4%e6%96%b9%e6%b3%95-%e7%ae%80%e7%9b%b4%e5%a4%aa%e5%85%a8%ef%bc%81-%e9%99%84python%e4%bb%a3%e7%a0%81random-forest%e3%80%81factor-analysis%e3%80%81corr%e3%80%81pca%e3%80%81ica/
注意:本文归作者所有,未经作者允许,不得转载

