4 聚类分析
聚类和判别作为统计学习(通过拟合统计模型,从数据中学习)的分类之一,同样可以分为有监督式和无监督式。
市场研究中,聚类和判别更多适用有监督式。即目标对象的在营销活动后的反应已知,通过目标对象的特征和其他变量,来拟合出相应的群组分类模型,可称为聚类;将该模型和目标对象特征、其他变量等来预测新的一批目标对象的营销反应,可称为判别。
非监督式学习,也可用作不知道结果组,但通过数据杰哥的发掘,来获取其分组模式。
聚类分析的步骤:
- 1、选择合适的变量。根据业务需求和对数据结构的理解,选取合适的聚类变量。
- 2、对数据进行标准化。将不同变量的数据范围,使用scale()进行标准化,减少因不同变量单位差别造成的扰动。
- 3、寻找异常点。对于很多基于距离的聚类方法而言,异常点会对分类造成很大影响。可通过outliers包中的outlier()来寻找异常点。
- 4、选择聚类算法。根据数据结构和目的,选择一个或多个聚类方法。
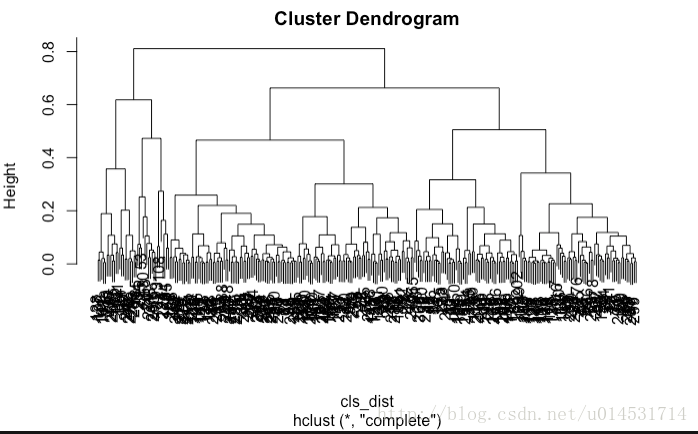
- hclust(系统聚类)和kmean(基于均值的聚类)是两个基于距离的聚类方法。其原理是寻找最小化的组内距离和最大化的组件距离。hclust()通过树状结构建模获得分组,kmean()使用中心定位的方法获得分组;
- Mclust()(混合高斯分布)和poLCA()(潜在类分析)是两类基于模型的聚类方法。Mclust认为不同类别的观测有不同的分布样态,通过估计潜在的分布参数和混合比例,来确定观测的分组,mclust是基于正态分布的,也就意味着只适用于数值型的数据。poLCA()则是使用包含分类变量的浅层级模型。
- 5、运用聚类方法,并存在聚类对象。在运用聚类方法过程中,需要根据不同的聚类方法,进行不同的准备,如基于聚类的方法hclust()需要事先计算相似度矩阵,才能运用观测分类,kmean()、poLCA()需要指定观测分组等等。
- 6、解读聚类方案,根据业务使用聚类方案的特征。
数据输入
-聚类分析.png)


hclust()

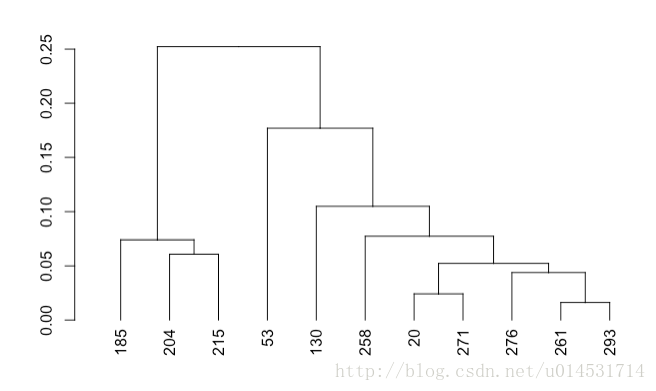
切割后的谱系图

#e 检查拟合优度。cophenetic是专门针对系统分类的检验系数,类似于r,CPCC > 0.7 说明你和强度强,意味着该模型能够较好的切分两棵树之间的距离
cor(cophenetic(cls_hc),cls_dist)
>[1] 0.7682436深挖系统聚类给出的类:
#f 对谱系图进行切割。根据plot(cls_hc)获得的谱系图,来确定具体需要的分类数量k
plot(cls_hc)
rect.hclust(cls_hc,k = 3, border = "orange")
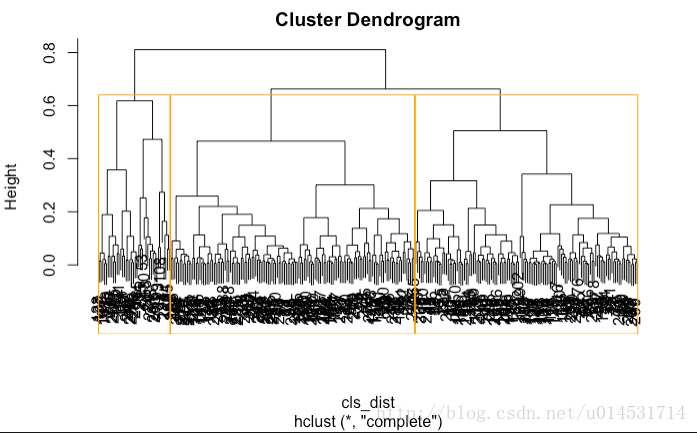

#g 对分组进行具体的描述
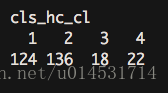
cls_hc_cl <- cutree(cls_hc, k = 4)
table(cls_hc_cl)
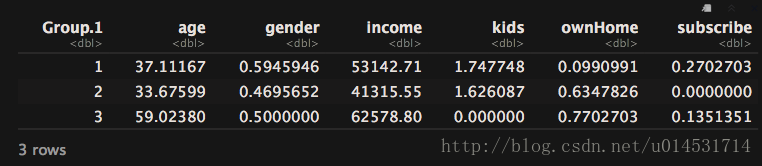
aggregate(cls, list(cls_hc_cl),function(x) mean(as.numeric(x)))

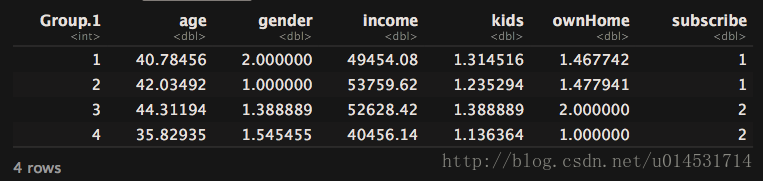

可看到,1,2两类在gender上区别明显,3、4两类则在age和ownhome上区别明显
kmean()
# a kmean只能适用于数值变量,在本案例里,可以对因子变量进行重新编码,对于二项因子变量,ifelse()就足够使用(针对更多变量,可使用factor())
cls_kd <- cls
cls_kd$gender <- ifelse(cls$gender=="Male", 0, 1)
cls_kd$ownHome <- ifelse(cls$ownHome=="ownNo", 0, 1)
cls_kd$subscribe <- ifelse(cls$subscribe=="subNo", 0, 1)
# b 随即便可建模。kmean需要事先指定定类数量
set.seed(101)
cls_km <- kmeans(cls_kd, centers = 4)
#使用之前的类别特征检验函数查看kmean分类情况
aggregate(cls_kd, list(cls_km$cluster),function(x) mean(as.numeric(x)))
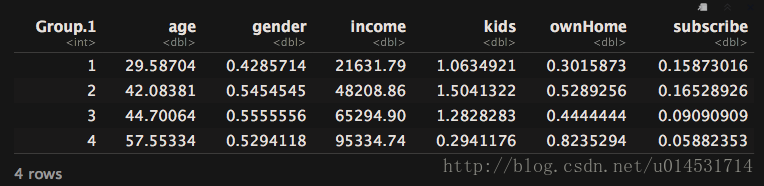

与hclust结果不同,kmeans的各组在各方面都有明显的区别。
#可用boxplot查看分类对于结果变量的差异情况
boxplot(cls_kd$income ~ cls_km$cluster, ylab = "income", xlab = "cluster")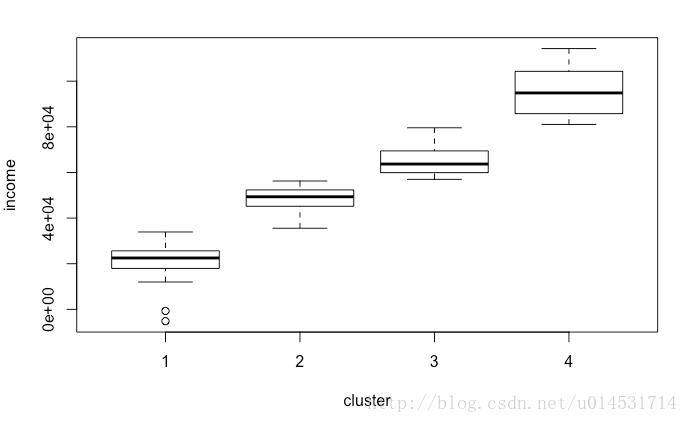

#对各类别差异进行可视化,可用到cluster包的clusplot()函数
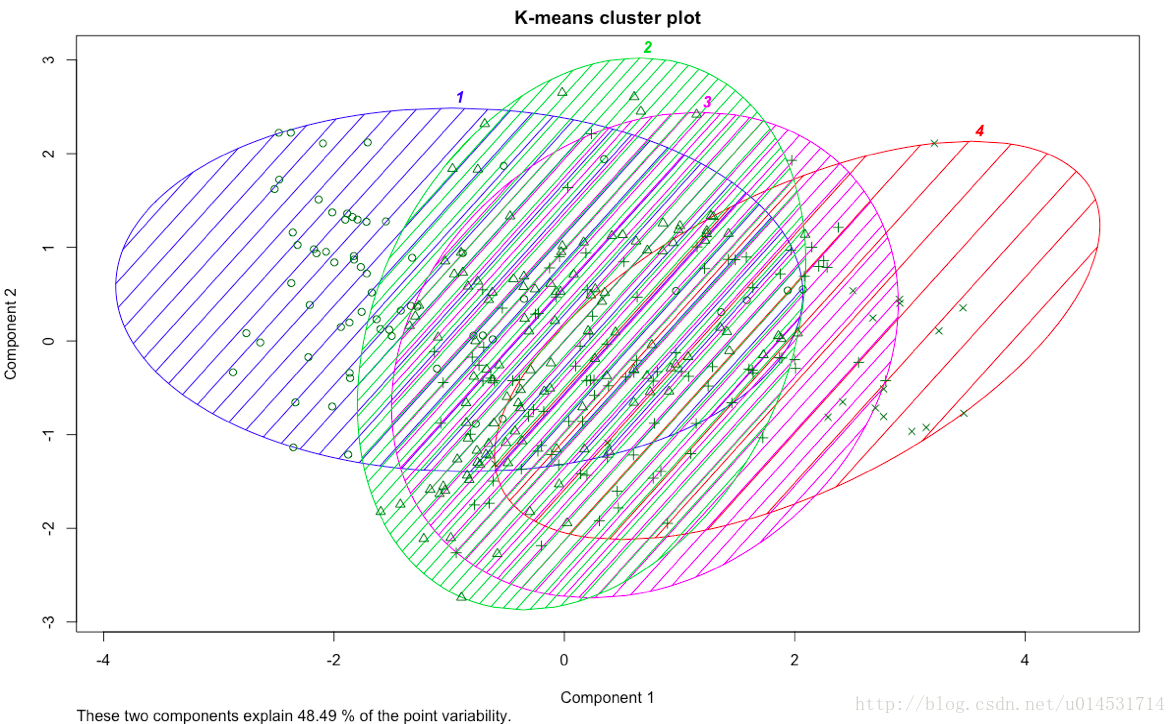
clusplot(cls, cls_km$cluster,color = T, shade = T, labels = 4, main = "K-means cluster plot")

Mclust()
library(mclust)
#Mclust同kmean一样,只能适用于数值变量,因此继续沿用之前的数据集
cls_mc <- Mclust(cls_kd)
summary(cls_mc)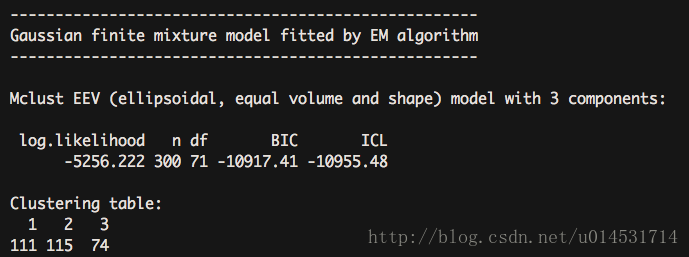

Mclust()会给出建议的分类,本例中,log似然比是最大的,3类被认为是拟合最好的案例。
若是希望制定分组数量,可以如此操作:
cls_mc4 <- Mclust(cls_kd, G = 4)
summary(cls_mc4)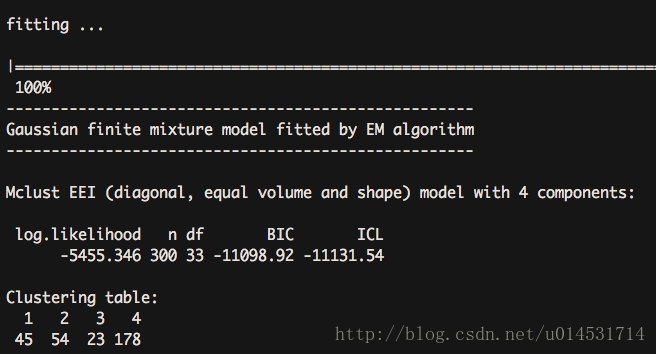

#对该函数,可使用BIC()函数来对比模型,BIC值越低越好
BIC(cls_mc,cls_mc4)
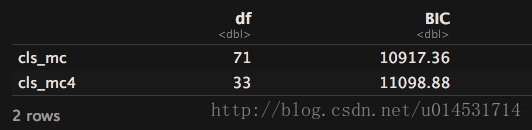

尽管从数据上显示分为3类的模型拟和更好,但依然需要对比业务需求和选择。
aggregate(cls_kd, list(cls_mc$classification),function(x) mean(as.numeric(x)))

poLCA()
#poLCA只适用于因子变量,此处使用median中位值切分法来对其中的数值变量进行切分
cls_pl <- cls
cls_pl$age <- factor(ifelse(cls$age < median(cls$age), 1, 2))
cls_pl$income <- factor(ifelse(cls$income < median(cls$income),
1, 2))
cls_pl$kids <- factor(ifelse(cls$kids < median(cls$kids), 1, 2))
summary(cls_pl)
#分别适用 K=3 , K=4两种情况下的模型
library(poLCA)
#定义poLCA的formula
cls_fml <- with(cls_pl,
cbind(age, gender, income, kids, ownHome, subscribe) ~ 1)
set.seed(101)
cls_plca <- poLCA(cls_fml,cls_pl,nclass = 3)
cls_plca4 <- poLCA(cls_fml,cls_pl,nclass = 4)
Conditional item response (column) probabilities,
by outcome variable, for each class (row)
$age
Pr(1) Pr(2)
class 1: 1.0000 0.0000
class 2: 0.7758 0.2242
class 3: 0.0000 1.0000
$gender
Pr(1) Pr(2)
class 1: 0.6085 0.3915
class 2: 0.5385 0.4615
class 3: 0.4852 0.5148
......
Estimated class population shares
0.069 0.5556 0.3755
Predicted class memberships (by modal posterior prob.)
0.0833 0.5133 0.4033
=========================================================
Fit for 3 latent classes:
=========================================================
number of observations: 300
number of estimated parameters: 20
residual degrees of freedom: 43
maximum log-likelihood: -1093.777
AIC(3): 2227.554
BIC(3): 2301.63
G^2(3): 45.63787 (Likelihood ratio/deviance statistic)
X^2(3): 42.38725 (Chi-square goodness of fit)
=========================================================
========================================================
Conditional item response (column) probabilities,
by outcome variable, for each class (row)
$age
Pr(1) Pr(2)
class 1: 0.6908 0.3092
class 2: 0.0000 1.0000
class 3: 1.0000 0.0000
class 4: 0.6359 0.3641
......
Estimated class population shares
0.2956 0.3452 0.1851 0.1742
Predicted class memberships (by modal posterior prob.)
0.33 0.3467 0.2067 0.1167
=========================================================
Fit for 4 latent classes:
=========================================================
number of observations: 300
number of estimated parameters: 27
residual degrees of freedom: 36
maximum log-likelihood: -1088.944
AIC(4): 2231.888
BIC(4): 2331.891
G^2(4): 35.97185 (Likelihood ratio/deviance statistic)
X^2(4): 31.87401 (Chi-square goodness of fit)
ALERT: iterations finished, MAXIMUM LIKELIHOOD NOT FOUND 本文来自CSDN,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://blog.csdn.net/u014531714/article/details/76339437?spm=1001.2014.3001.5502
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

