


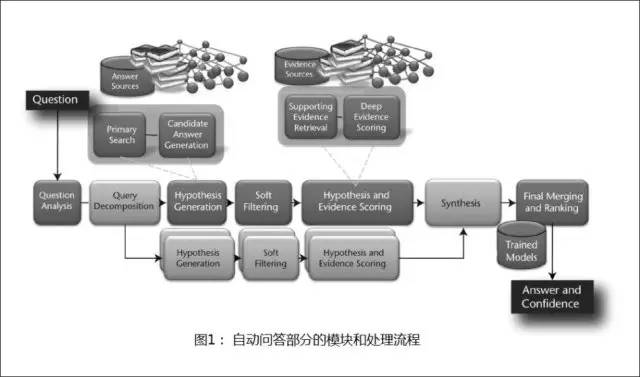
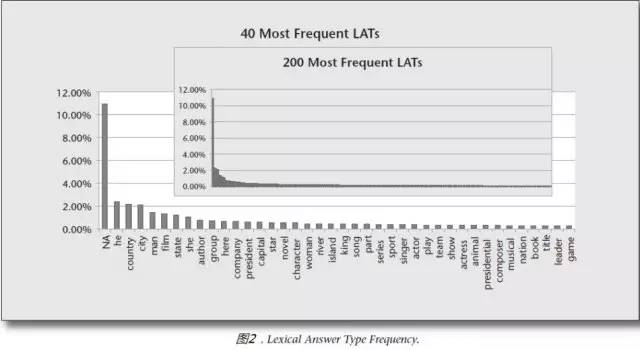


原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/ibm-watson%e6%9c%ba%e5%99%a8%e4%ba%ba%e7%ae%97%e6%b3%95%e4%bb%8b%e7%bb%8d/
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/ibm-watson%e6%9c%ba%e5%99%a8%e4%ba%ba%e7%ae%97%e6%b3%95%e4%bb%8b%e7%bb%8d/
注意:本文归作者所有,未经作者允许,不得转载

