目前数据挖掘技术越来越受到大企业的关注和使用,企业所储存的海量用户数据信息蕴藏着丰富的内容,但是缺乏足够高效的工具来挖掘、管理和利用这些资源。本文试图通过一个保险理赔欺诈的模拟用例,为读者演示如何利用 IBM SPSS Modeler 来建立模型,用 IBM SPSS Collaboration and Deployment Services 来管理模型,以及使用 Score 机制来利用模型,帮助用户对理赔请求做出合理的预测和分析,达到减少对欺诈理赔的金额,降低保险业客户的风险。
概念介绍
IBM SPSS Modeler
IBM SPSS Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。
SPSS Modeler 提供了各种借助机器学习、人工智能和统计学的建模方法。通过建模选项板中的方法,您可以根据数据生成新的信息以及开发预测模型。每种方法各有所长,同时适用于解决特定类型的问题。图 1 是 Modeler 运行时的界面。
图 1. Modeler 运行界面

CRISP-DM
CRISP-DM(Cross-Industry Standard Process for Data Mining), 意思是跨行业数据挖掘标准流程。这一标准于 1996 年由 SPSS、NCR 和 Daimler-Benz 共同提出,并不断改进总结,于 2000 年推出了 CRISP-DM 1.0 版。通用的 CRISP-DM 过程模型包括六个用来解决数据挖掘主要问题的阶段。这六个阶段拟合在一个为将数据挖掘应用于较大业务实践而设计的循环过程中。这六个阶段包括:
- 商业理解。这可能是数据挖掘最重要的阶段。商业理解包括确定业务对象、评估情况、确定数据挖掘目标以及制订工程计划。
- 数据理解。数据提供了数据挖掘的“原材料”。此阶段用于了解您的数据源以及这些数据的特征。此阶段包括收集初始数据、描述数据、探索数据和验证数据质量。
- 数据准备。对数据源进行分类之后,您需要准备数据,以便进行挖掘。准备包括选择、清理、构建、集成数据以及格式化数据。
- 建模。此阶段毫无疑问是数据挖掘的核心部分,在此阶段将使用精巧复杂的分析方法从数据中提取信息。此阶段包括选择建模技术、生成测试设计,以及构建和评估模型。
- 评估。选定模型之后,就可以评估数据挖掘结果在多大程度上能够帮助您实现业务目标了。此阶段的要素包括评估结果、查看数据挖掘过程,以及确定后续步骤。
- 部署。既然您已经付出了上述所有努力,现在就应该有所获益了。此阶段主要是将您的新知识结合到日常的业务流程中,来解决最初的业务问题。此阶段包括计划部署、监视和维护、生成最终报告,以及复查该工程。
图 2. CRISP-DM 流程图
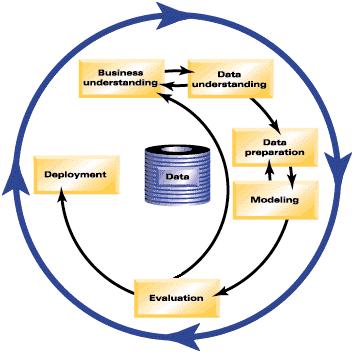
生命周期模型中由六个阶段组成,其中的箭头表示这些阶段间最重要和最频繁使用的依赖关系。阶段之间并不一定要严格遵守顺序。实际上,大多数工程都会根据需要在这些阶段之间来回移动。
CRISP-DM 模型具备灵活性,可以轻松地自定义。例如,如果您的组织旨在检测洗钱行为,您很有可能将在不设定具体建模目标的情况下对大量数据进行筛选。此时,您的工作不是建模,而是以数据探索和数据展现为主,以便揭示可疑的财务数据模式。使用 CRISP-DM,您可以创建满足特定需求的数据挖掘模型。
在此情况下,与数据理解和准备阶段相比,建模、评估和部署阶段之间的关联性可能相对较小。但是,仍然需要考虑在这些后期阶段引发的某些问题,以便进行长期规划和制定未来的数据挖掘目标。
IBM SPSS Collaboration and Deployment Services 与 ModelerAdapter
IBM SPSS Collaboration and Deployment Services (简称 CADS)是一款企业级应用程序,它可以实现预测分析的大规模使用和部署。CADS 拥有集中、安全和分析数据的可审计存储功能、管理和控制预测分析过程的高级功能以及用于将分析处理结果发送给最终用户的成熟机制。CADS 的优点包括:
- 保护分析数据的价值
- 确保符合合规性要求
- 提高分析人员的工作效率
- 最小化管理分析的 IT 成本
CADS 允许您安全地管理各类分析数据,并促进开发者与用户之间的更有效协作。并且,相关人员还可通过部署工具获得所需信息,以采取正确、及时的行动。
ModelerAdapter 是工作于 CADS 平台下的一组组件,它实现了一组来自 CADS 的标准接口,可以提供分析和执行利用 Modeler 建立的模型,以及实时评分的功能。
Real Time Scoring(RTS)
现代企业越来越重视对客户的诉求做出快速的反应,比如信用卡商面对客户临时额度的信用提升,比如保险的快速理赔,面对形形色色的快速请求,如何能够在做出快速反应的同时,降低企业客户的风险,减少企业与用户之间繁琐的手续,缩短用户请求的时间,以及提高企业服务的质量,都要求产品能够面对各种情况做出高速有效正确地判断。但是,高速的响应必然带来巨大的风险,RTS 正是依托于 Modeler 和 CADS 平台,利用企业大量的历史数据建立模型,针对这种快速请求的情况,对用户的信息加以甄别,快速地提供给用户合理的推测和建议,帮助用户对客户的请求加以判断,达到上述减低风险的目的。
RTS 在保险欺诈中实例运用
对保险欺诈国际上一般也称保险犯罪。在这里主要指针对保险公司,保险人利用保险合同内容,故意制造或捏造保险事故造成保险公司损害,以谋取保险赔付金的犯罪行为。
对应于 CRISP-DM 流程,Modeler 把流的过程分为商业理解,数据准备,数据理解,建模,评估和部署。
保险欺诈(Insurance-Fraud)的商业分析
商业理解是理解项目的商业愿景和商业目标以及把商业目标转化为相对应的数据挖掘的问题,制定完成目标的计划。
大型保险公司需要对客户的请求做出合理高效的判断,其主要目标是:
- 减少对理赔申请的时间
- 减少对保险欺诈的理赔
针对这种目标,如何对一个申请是否是欺诈做出判断就非常重要,幸运的是保险公司拥有以往的大量历史申请数据,从中可以总结出一个近似真实的模型来对新的请求做出预测。
在保险公司的数据中,主要保留如下图所示的数据项目:
图 3. 保险公司的理赔数据项目

分析数据后可以得到以下结论:
- 字段‘ fraudulent ’指明了本条申请是否为欺诈,其他字段是用户在申请时提供的信息;
- 数据分析可以得出字段‘ fraudulent ’与其它的字段存在潜在的 BayesNet 关系,比如说字段‘ police_report ’是‘ Yes ’,意味着可能的欺诈比较低;
- 部分字段在可能条件下不会对预测产生影响,比如自动生成的字段‘ claim_id ’ .
如何在 Modeler 中建立模型
通过上面的分析,用户必须建立起字段‘ fraudulent ’与其他字段的模型关系,不需要理解复杂的统计学知识,用户可以利用 Modeler 方便地建立起 如图 4 所示的流来分析和建模的流程。
图 4. 流
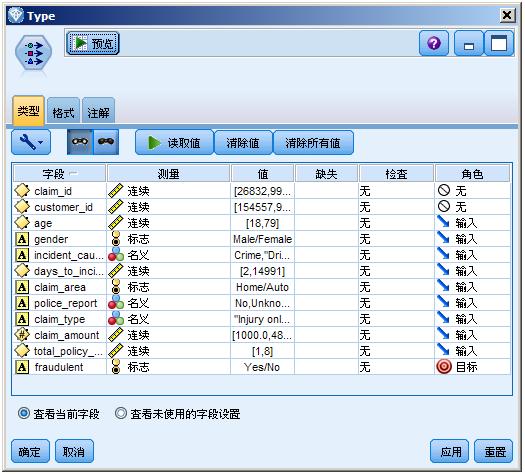
在数据的准备和数据理解阶段,用户需要使用 Type 节点定义每列数据的类型和角色,这样做可以确定每一个字段的格式和在建模中参与的行为,为以后的建模做准备,定义如图 5 所示,根据上面的分析,字段‘ claim_id ’和‘ customer_id ’并没有对预测有实际的贡献,字段‘ fraudulent ’正是分析的目标,其他所有的字段都是输入。
图 5. Type 节点设置界面
根据前面的分析,建模阶段用户选择 BayesNet 节点来建立模型,用户可以选择一个也可以选择多个模型,通过设置几个模型不同的参数,选择结果最佳的模型作为最优的结果,也可以结合多个模型的结果来综合预测。在本例中,用户可以 选择 TAN 或者 MARKOV 模型。
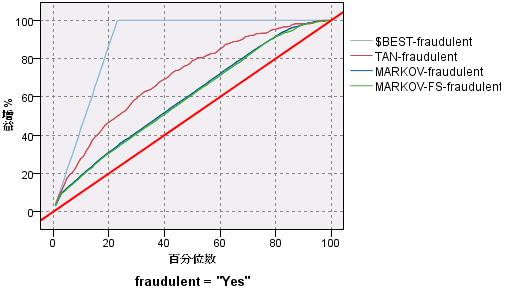
为了评估结果的好坏,用户可以尝试在 Modeler 中运行这个流,得到如图 6 所示的分析结果,通过对比结果中的最佳曲线可以发现,TAN 模型较 MARKOV 模型有更好的效果。
Modeler 的优势就在于用户不需要人工对已有数据进行筛选和分析,不需要事先定义规则,只需要使用已有的数据和选择合适的模型来分析,让 Modeler 从数据中发现和应用规则,当用户需要变更数据或者改变模型的时候,只需重新生成模型即可。这种自动的方式有利于减少人工干预,提高模型的稳定性。
图 6. 运行结果示意图
部署完成的模型到 CADS
完成的模型需要部署到 CADS 来管理和使用,如图 7 所示, Modeler 的部署工具可以帮助用户可以选择希望的得分分支,连接到 CADS 服务器,部署到相应的位置。部署的方式还可以选择流或者方案(Scenario),方案是流为企业级使用的一种包装。
图 7. 部署流到 CADS
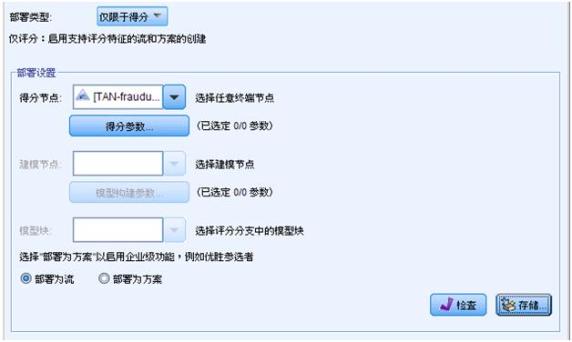
部署流在 CADS 之后,用户需要通过 Deployment Manager 来为部署的流配置一个 ScoreConfiguration 文件,用来定义 scoring 时所需要的变量信息,包括如下信息:
- 配置 ID 信息,需要为每个 Configuration 一个当前 server 唯一的 ID 和指定需要的 Label 标识不同的版本。
图 8. 配置流的识别 ID
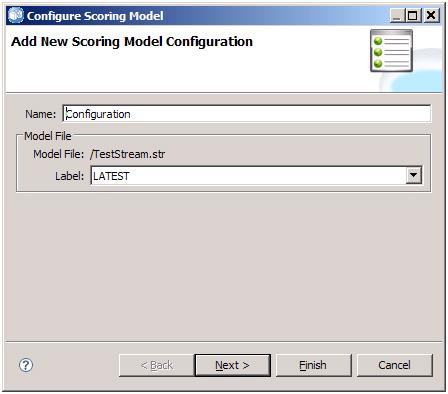

- 所需 scoring 的模型信息,用来选择所需 Score 的分支,如果流上有多个终节点,就会让用户来选择,否则就跳过这一步。
图 9. 配置所需使用的分支

- 输入使用的 Data provider, CADS 提供了访问数据库的模型,把数据库的管理分成多个层次,DPD 提供数据,ApplicationView 管理视图,EnterpriseView 管理表,在这里用户可以为自己的
图 10. 为输入节点配置 DPD


- 设置记录信息的内容,输出在 log 里,由用户决定所需关注的字段。
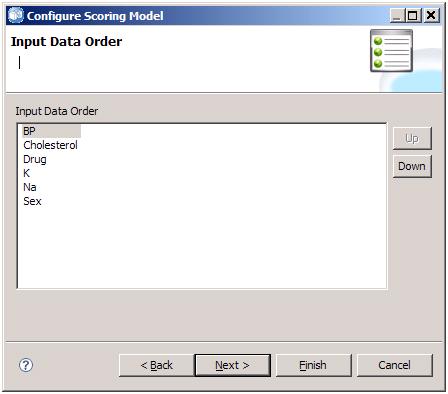
- 自定义输入字段的顺序,方便用户在 Score 时按照特定的顺序来输入。
图 11. 安排输入字段的顺序

- Scoring 模型的缓存大小,用来优化模型执行的方式,使用文件作为输入,设置 Cache 的大小来提高效率以及指定 log 存放的位置。
图 12. 设置 Cache 的大小和记录的位置


保险欺诈的实时分析与处理
访问 CADS 的 Web 管理系统,在 Repository 中找到部署的流,点击相应的链接,如果有多个 ScoreConfiguration,用户就必须选择希望的 ScoreConfiguration 配置。完成选择后会显示如图 13 所示的 Score 界面,在相应的字段填写下客户申请的值,点击‘ Score ’按钮提交 Score 的请求,返回的结果会显示在页面下方。
从运行的过程来说,Score 的过程就是 ModelerAdapter 执行了流的过程,将流的输入替换为用户实时的输入,然后利用已经生成的模型计算结果,就像在 Modeler 当中一样。正如图 8 所实现的结果,模型提供了也测得见过,与用户所提供的主观结果可能会有出入,用户可以定义一些简单的规则来做出快速的判断,比如类似下列的方式。
表 1. 自定义规则列表
| TAN | MARKOV | MARKOV-ES | 结论 |
|---|---|---|---|
| NO | NO | NO | NO |
| NO | YES | YES | NO |
| YES | NO | NO | NO |
| YES | YES | YES | YES |
图 13. 实时数据分析结果

使用 CADS 来展示数据是一种普通的方案,用户也可以自定义一种显示方式,调用 CADS 和 ModelerAdapter 的接口来实现自己的 Score 方式,IBM SPSS DecisionManager 就是这种方式的最佳体现,IBM SPSS DecisionManager 完全使用了自己的交互接口,利用了 Score 的结果同时带来细腻丰富的展示结果。
小结
尽管目前 Score 的过程非常快速地完成了用户提交的预测判断,但是还很难满足用户多种多样的需求。在新版本中,Modeler 和 CADS 会提供更多样的 Score 过程,用来满足客户对诸如多行数据输入、多源节点 Score 的需求。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/real-time-scoring-%e5%9c%a8-ibm-spss-modeler-%e7%9a%84%e4%b8%ad%e5%ae%9e%e7%8e%b0%e5%92%8c%e8%bf%90%e7%94%a8/
注意:本文归作者所有,未经作者允许,不得转载

