感觉很多时候这两个概念没有明确的区分,大家在用的时候也是混着用的。
其实,在英语中他们都属于feature scaling(特征缩放)scale:比例、数值范围
一、什么是特征缩放?
特征缩放是标准化变量取值范围的一种方法,在数据处理中也被称为数据标准化,一般是在数据预处理阶段使用。
二、Machine Learning中为什么要进行数据换算?
两个原因:
1.原始数据中各特征间的取值范围可能差距很大,有些机器学习算法如果不进行标准化就无法正常工作。比如,一些分类算法是用来计算点之间的欧拉距离,如果一个特征的取值范围特别大,那么最终计算的点的距离就会主要受这个变量影响。所以应该把所有变量进行标准化,这样每个变量都可以按照比例贡献最终距离的一部分。
2.数据换算后,在梯度下降迭代求解时收敛的更快。
三、数据换算的方法?
1.Standardization (Z-score Normalization):一般称为标准化。把数据转化为均值为0,方差为1的分布。
![]()
![]()
有些地方提到进行标准化要求数据是正态分布,其实不需要的,而且标准化不改变数据的原始分布,但归一化我认为也没有改变数据的原始分布,具体分析没有找到权威的资料。
2.Rescaling(min-max normalization):一般称为归一化,因为变换后变量范围在0-1之间。
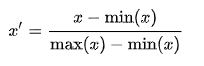

3.Mean normalization,均值归一化
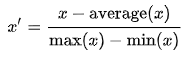

4.Scaling to unit length
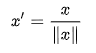

维基百科中同时也提到,在SVM中,feature scaling能缩短找到特征向量的时间,同时feature scaling也会改变SVM的结果。
总结起来,有哪些模型必须要做变量转换,哪些不用呢?
| 必须要做变量转换的模型 | 不必须要做(甚至不能做)变量转换的模型 |
| PCA(主成分分析) | 逻辑回归 |
| 聚类 | 树模型、梯度提升类模型 |
| KNN | LDA(线性判别分析) |
| SVM | Naive Bayes |
| 在回归模型中测量变量的重要性时 | |
| Lasso回归和岭回归 |
在必须要做变量转换的模型中,聚类、KNN、SVM是因为它们是基于距离的模型,数据标准化用于预防范围较大的特征对预测结果进行较大的影响。
而PCA,这时如果不做变量转换,会导致这一特征对其它特征更突出。
Lasso回归、岭回归时,会导致惩罚系数对不同变量的惩罚强度差距很大,因为在ML中,LR基本都是要带正则的,所以在ML中,LR(即lasso或ridge)必须要先标准化。
检测回归模型中变量重要性时,如果不做变量转换,只看系数大小判断变量重要性是没有意义的。
参考资料:
本文来自cnblogs,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://www.cnblogs.com/ironan-liu/p/11690034.html
注意:本文归作者所有,未经作者允许,不得转载

