A. 用途:
可以用来预测,由多种因素影响的结果。
B. 建立公式:
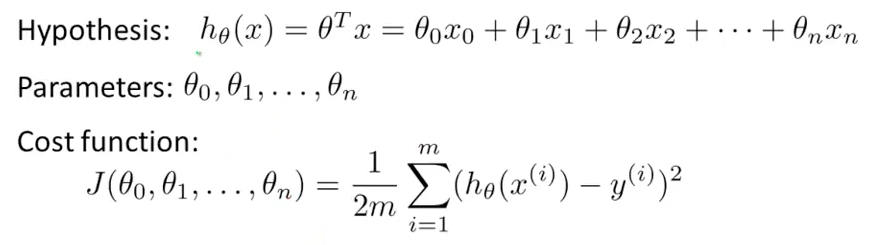
C. 求解方法:
方法1. Gradient Descent:
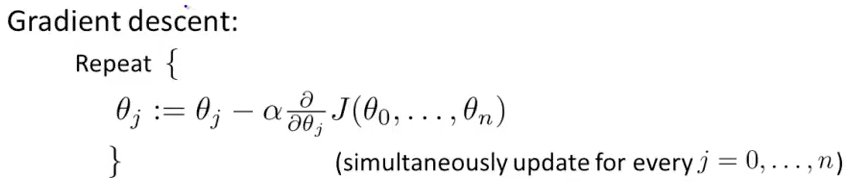

技巧:
技巧1. Feature Scaling:


何时用:
当各个变量的值域或者数量级相差比较大时,
需要将各个变量的值域变换到相似的水平,
变换后,Gradient Descent 就可以更快地下降。
为什么要用:
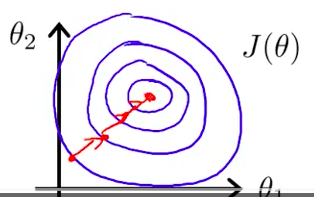
不用的话,J 关于 Theta 的形状就会非常扁,Gradient 就会来回摆动,就需要更长的时间才能找到最小值。
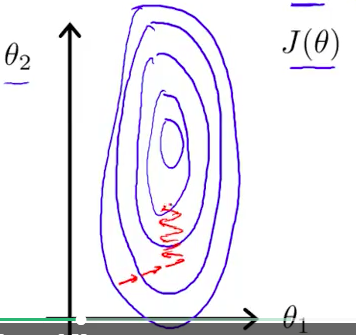
所以就要做Feature Scaling:
怎么用:
1.除以值域范围:
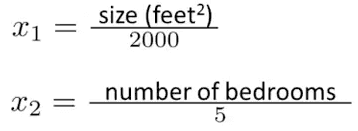
2.或者,先减平均值,再除以值域范围:

之后,这个形状就会比较正规,Gradient 就可以比较快地找到全局最小值。
技巧2. Learning Rate:
如何确认Gradient Descent是在正确地进行?
如何选择Alpha?

1. 如何确认Gradient Descent是在正确地进行?
数学家们已经证明,当Alpha足够小,J就会每次迭代后都下降。
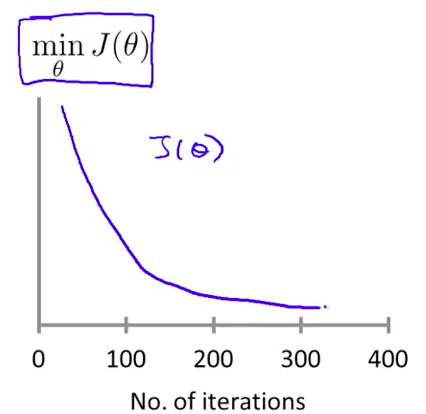
所以,就可以画图,横轴是迭代的次数,纵轴是cost function的值:
如果是正确的话,那么每次都用迭代后得到的Theta代入J,J应该是下降的。
如果曲线是上升的,说明Gradient Descent用错了,此时需要将Alpha调小。
因为Alpha较大的话,就会过头而错过最小值,进而表现越来越差,造成曲线是上升的:
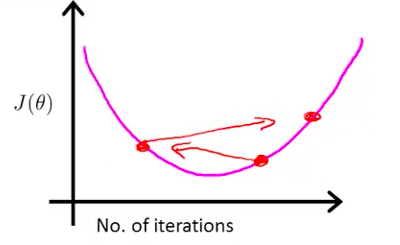
但是当Alpha太小的话,收敛就会很慢。
补充:
到底需要多少次迭代才会收敛,是与算法和数据有关的。
自动检测是否收敛的方法:
但是这个阈值是很难去确定的。

2. 如何选择Alpha?
在实践中:
可以尝试一系列Alpha的值,0.001,0.01,0.1,1等。
技巧3. 如何选Feature?
在实践中:
你可以不只是用给定的因素,而是通过思考,看哪些因素也是影响预测目标的原因,或者由原始的因素间,进行加减乘除等运算,自己构建Feature。
有一种比较普遍的构建方法,就是多项式。
后续会介绍一些算法,是用来自动选择Feature的。
方法2. Normal Equation
它是另一种求解最小值的方法,是通过分析的方式,而不是迭代。
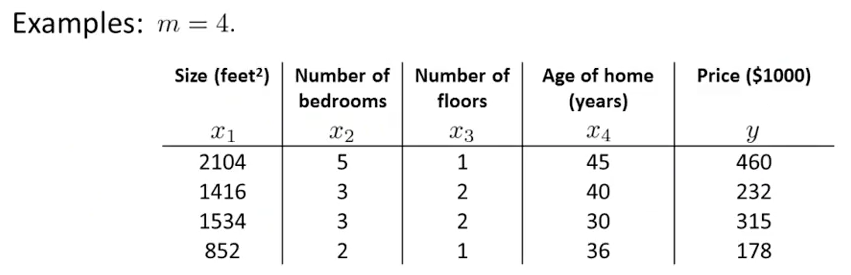

根据线性代数的知识,得到Theta的求解公式:
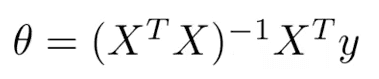
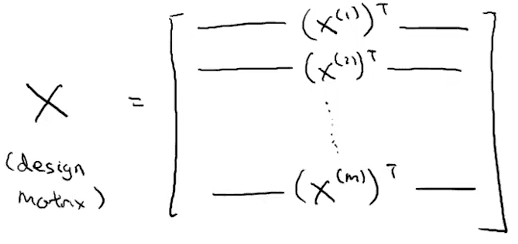
m个Sample数据,n个Feature,那么Design Matrix的维度就是 m*(n+1)。
当 X`X 不可逆的时候,该怎么办?
造成不可逆的原因可能主要有两个:
一个是变量间具有相关性,比如一个变量以线性相关关系的形式被用作两个变量。
另一个原因是用了太多的Feature,就是m<=n时,比如说只用10个Sample去做101个Feature的预测。
这两种情况下的解决方案就是,要么删掉一些Feature,要么采用Regularization,后续。
D. 两种方法比较
用 Normal Equation 的话,就不用做 Feature Scaling 了。

当 Feature 有很多,成千上百万的时候,Gradient Descent 也仍然有效,但是 Normal Equation 因为要计算矩阵的转置,乘积,还有逆,就不适用于这样的数量级的计算。一般在 1000 级别的还可以用 Normal Equation。
原文链接:http://www.jianshu.com/p/87e96bf27f20
著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a0%ef%bc%8d%e5%a4%9a%e5%85%83%e7%ba%bf%e6%80%a7%e5%9b%9e%e5%bd%92/
注意:本文归作者所有,未经作者允许,不得转载

