from http://blog.sina.com.cn/s/blog_7103b28a0102w805.html
G-means的思路为:检测一个质心所含的数据看上去是否是高斯的,如果不是就分裂这个簇。G-means能很好地处理stretched out clusters(非球面伸展型类簇)。
下面以一个二维数据集为例进行说明,数据集中包含两个簇,每个簇具有独特的协方差。
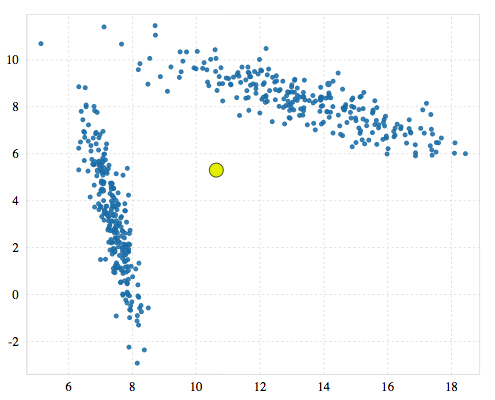
G-means的大致过程如下:
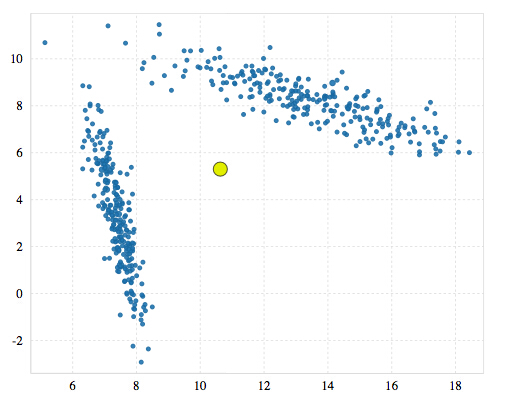
1)从一个簇开始,这个簇的位置和使用k=1的kmeans得到的位置一样。
2)使用k=2对数据集进行聚类,得到两个新的质心a和b,连接a和b得到一条直线,将所有数据投影到这条直线上。
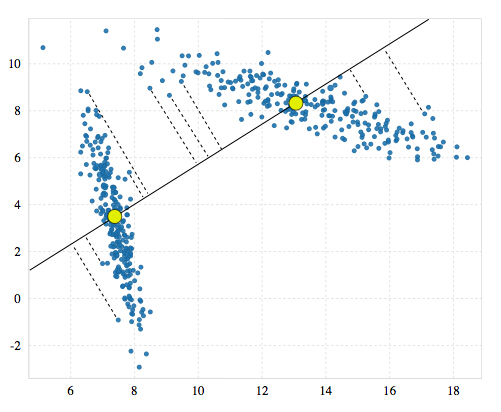
3)检测投影后的数据是否符合高斯分布,检测使用的方法是Anderson-Darling test。
4)如果数据的分布大致符合高斯分布,则说明之前的一个质心已经足以对数据进行聚类,不用分裂成两个质心。
5)如果分布不符合高斯分布,就将数据划分到两个质心,分别查看两个质心的数据在直线上的投影,是否两个分布大致符合高斯分布,是的话就保留这两个质心,将数据划分为两个数据集。
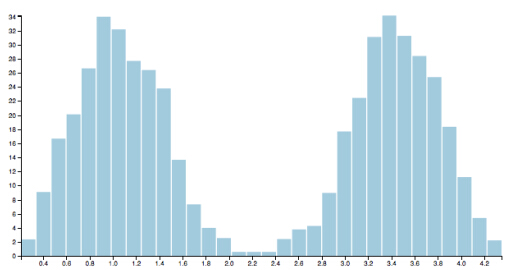
6)对得到的两个新数据集分别重复上述过程。下图中,对其中一个数据集重复了上述过程,得到的所有数据集在直线上的分布大致符合高斯分布,所以不需要再对数据进行分裂。

对Gmeans的一个变型是在于循环停止的标准上。变型中,不是在数据大致符合高斯分布后才停止,而是在进行足够多次循环后,聚类的质量并没有明显提升,就停止循环过程。这种策略能够处理数据集没有明显质心的情况。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e5%8f%a6%e4%b8%80%e7%a7%8d%e7%a1%ae%e5%ae%9akmeans%e4%b8%adk%e5%80%bc%e7%9a%84%e6%80%9d%e8%b7%af-gmeans/
注意:本文归作者所有,未经作者允许,不得转载

