Top10 搜索中的此类广告是怎么打进我的百度统计的?
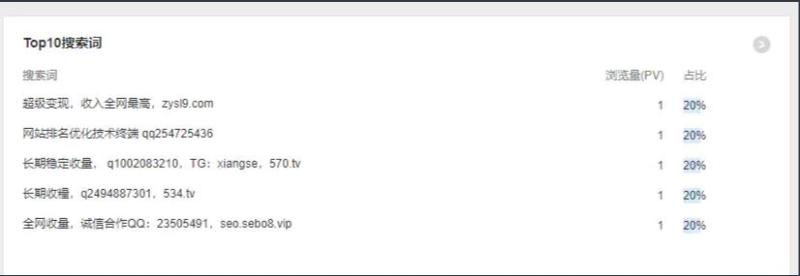
引起了彬哥墙裂的好奇心,一顿捣鼓,终于找到复现的方式了。
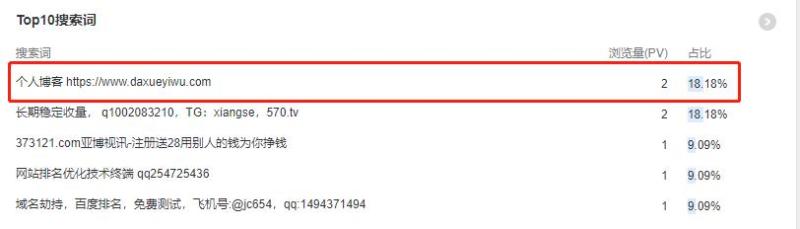
原理其实很简单,在百度搜索你想要投放广告的站长类型的关键词,加逗号加你要说的话然后批量搜索,访问搜索到的网页,这些网页的站长在站长统计工具里就能看的你搜索框里的内容了。广告确实挺烦人的,但是用来给志同道合的站长大人们相互加个友链,也是一种途径。比如我在我的博客中加了自助添加友链的功能,我就在百度搜索“个人博客,https://www.daxueyiwu.com/links/index”,在站长统计后台看到的站长,访问我的网站觉得还不错就可以自己添加友链了。
多了不说,上代码:
#!usr/bin/env python
# -*- coding: utf-8 -*-
#!文件类型: python
#!创建时间: 2020/11/5 15:02
#!作者: SongBin
#!文件名称: AdForBaiduTj.py
#!简介:
import re
from selenium import webdriver
import time
import datetime
from selenium.webdriver.chrome.options import Options
import logging
logging.basicConfig(level=logging.INFO,#控制台打印的日志级别
filename='C:\links\logs\output.log',
filemode='a',##模式,有w和a,w就是写模式,每次都会重新写日志,覆盖之前的日志
#a是追加模式,默认如果不写的话,就是追加模式
format=
'%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'
#日志格式
)
# 打开浏览器
logging.info(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') + "#############程序开始运行###########")
# 火狐浏览器
options = webdriver.FirefoxOptions()
# options.set_headless()
# 谷歌浏览器
# chrome_options = Options()
# chrome_options.add_argument("--headless")
keys = [
"个人博客 www.daxueyiwu.com",
"博客 www.daxueyiwu.com",
"站长 www.daxueyiwu.com",
"博主 www.daxueyiwu.com",
"mblog www.daxueyiwu.com",
"solo www.daxueyiwu.com",
"oneblog www.daxueyiwu.com",
"tale www.daxueyiwu.com",
"DoraCMS www.daxueyiwu.com",
"JPress www.daxueyiwu.com",
"Halo www.daxueyiwu.com",
"*博客 www.daxueyiwu.com",
"开源博客 www.daxueyiwu.com/links/index",
"自助加友链 www.daxueyiwu.com",
"加友链 www.daxueyiwu.com",
"老铁加友链吧 www.daxueyiwu.com",
"大兄弟加友链吧 www.daxueyiwu.com",
"小妞加友链吧 www.daxueyiwu.com",
"链滴 www.daxueyiwu.com"
]
for key in keys:
# browser = webdriver.Chrome(executable_path='C:\\softs\\chrome\\chromedriver.exe',
# options=chrome_options) # .Firefox() # .PhantomJS(desired_capabilities=dcap) # executable_path='/usr/local/bin/phantomjs' phantomjs没有设置环境变量时可加参数
browser = webdriver.Firefox(options=options)
loginUrl = 'https://www.baidu.com'
browser.get(loginUrl)
time.sleep(2)
browser.find_element_by_id("kw").send_keys(key)
browser.find_element_by_id("su").click()
time.sleep(2)
numtxt = browser.find_element_by_class_name("nums_text").text
numtxt = re.findall('[1-9]\d*', numtxt)[0]
num = int(numtxt)
hrefs = []
els = browser.find_elements_by_class_name("t")
for h3el in els:
ael = h3el.find_element_by_tag_name("a")
href = ael.get_attribute('href')
print(href)
hrefs.append(href)
if num > 10:
count = 1
while count == 11:
try:
nextpage = browser.find_element_by_link_text("下一页 >")
nextpage.click()
time.sleep(2)
els = browser.find_elements_by_class_name("t")
for h3el in els:
ael = h3el.find_element_by_tag_name("a")
href = ael.get_attribute('href')
print(href)
hrefs.append(href)
count = count + 1
except:
pass
count = 11
for hf in hrefs:
try:
browser.get(hf)
time.sleep(2)
except:
continue
browser.close()
logging.info(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')+"程序运行结束###########")
So easy! Ma Ma再也不担心你的网站没朋友了。
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

