环境依赖
-
CentOS7,JDK8,scala-2.12.11.tgz,spark-2.4.8-bin-hadoop2.7.tgz
1.1 jdk 8安装配置环境变量
https://www.songbin.top/post_6377.html
1.2 scala-2.12.11安装
选择2.12.11版本下载
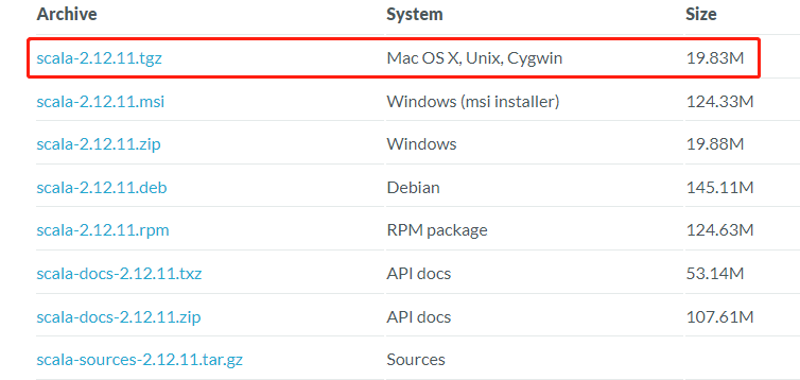
上传到服务器目录 /usr/local/softs并解压
tar -zxvf scala-2.12.11.tgz
配置环境变量
vi /etc/profile
添加环境变量如下:
export SCALA_HOME=/usr/local/softs/scala-2.12.11export PATH=${SCALA_HOME}/bin:${PATH}
刷新环境变量:
source /etc/profile
测试:
scala -version

3. 安装spark-2.4.8-bin-hadoop2.7.tgz
查看历史版本
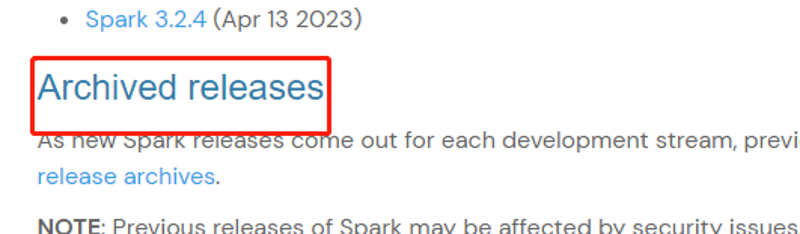
下载对应版本安装文件
 关闭防火墙
关闭防火墙
#关闭命令
service firewalld stop
chkconfig firewalld off关闭SELINUX
sudo vi /etc/sysconfig/selinux
#SELINUX=enforcing
SELINUX=disabled3.1 单节点安装
解压spark-2.4.8-bin-hadoop2.7.tgz到目录/usr/local/softs
tar -zxvf spark-2.4.8-bin-hadoop2.7.tgz
将解压的文件改名
mv spark-2.4.8-bin-hadoop2.7 spark2.4.8
修改配置文件
进入到conf文件路径下,将slaves.template拷贝并改名slaves
cp slaves.template slaves
将spark-env.sh.template拷贝并改名spark-env.sh
cp spark-env.sh.template spark-env.shvim spark-env.sh,在最后添加如下内容,如下配置路径视情况修改
export JAVA_HOME=/usr/local/softs/jdk1.8.0_311
export SCALA_HOME=/usr/local/softs/scala-2.12.11
export SPARK_HOME=/usr/local/softs/spark2.4.8
export SPARK_MASTER_IP=127.0.0.1
export SPARK_EXECUTOR_MEMORY=1G
修改环境变量 vim /etc/profile
export SPARK_HOME=/usr/local/softs/spark2.4.8
export PATH=${SPARK_HOME}/bin:${PATH}
保存退出后,使配置生效:
source /etc/profile
启动单节点Spark
进入sbin路径,执行命令启动spark
./start-all.sh
如提示输入密码,则需要进行ssh免密登录配置,如下
如果没有配置免密登录的话每次登录到这台服务器都要输入密码

[root@localhost spark2.4.8]# ssh 192.168.209.129
在本地机器(192.168.209.129)生成私钥和公钥
[root@localhost ~]# cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
[root@localhost .ssh]# ssh-keygen -t rsa # 会有提示,都按回车就可以
[root@localhost .ssh]# cat id_rsa.pub >> authorized_keys # 加入授权
[root@localhost .ssh]# chmod 600 ./authorized_keys # 修改文件权限
将公钥上传到远端机器(在此为本机)
[root@localhost .ssh]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.209.129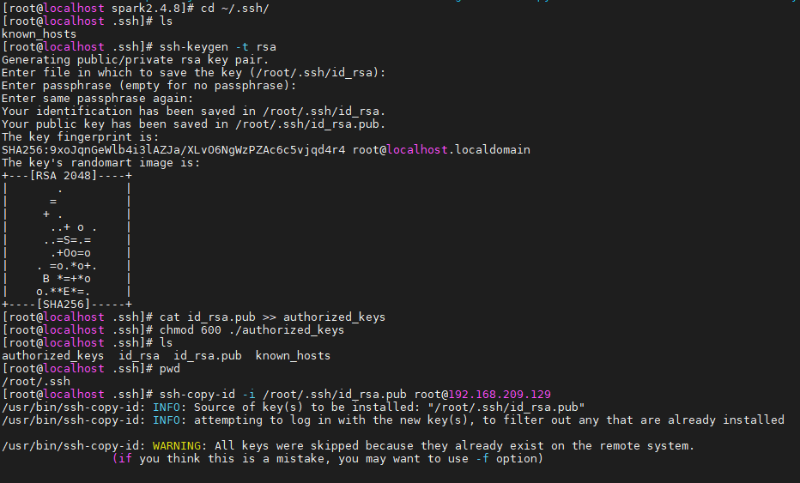
启动成功,jps命令查看Master和Worker节点是否已启动
[root@localhost sbin]# jps
14084 Master
14244 Jps
14186 Worker
验证spark环境启动是否成功
浏览器输入 ip+8080端口 如:http://192.168.209.129:8080/
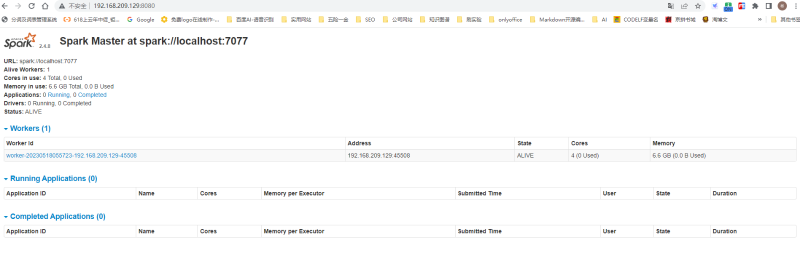
关闭Spark
- 在sbin下执行 ./stop-all.sh,然后jps看master和worker进程是否关闭了
3.2 集群环境安装
服务器规划
- Spark也是一个主从架构的分布式计算引擎。主节点是Master,从节点是Worker。
| Server | IP | Master | Worker |
|---|---|---|---|
| bigdata02 | 192.168.173.132 | √ | √ |
| bigdata03 | 192.168.173.133 | √ | |
| bigdata04 | 192.168.173.134 | √ |
环境准备
设置hostname
在Master节点的bigdata02机器上,将hostname置为bigdata02
hostnamectl set-hostname bigdata02同样的方式在另外两台worker节点上分别设置hostname为bigdata03、bigdata04
配置hosts文件信息
在三个节点都需要配置 vim /etc/hosts
192.168.173.132 bigdata02
192.168.173.133 bigdata03
192.168.173.134 bigdata04设置节点之间的ssh免密登录
配置132节点到133节点和134节点的ssh免密登录,一定要配,具体配法此处不做说明,可参考网上搜索的博文:https://www.cnblogs.com/shireenlee4testing/p/10366061.html
下载并安装Spark
在主节点服务器上的路径/spark,将spark压缩包放入此路径,并解压。
[root@bigdata02 spark]# tar -zxvf spark-2.4.8-bin-hadoop2.7.tgz修改配置文件
在主节点上进入解压后的文件对应的conf路径下
将slaves.template拷贝并改名slaves
[root@bigdata02 conf]# cp slaves.template slaves修改slaves文件如下
bigdata02
bigdata03
bigdata04
将spark-env.sh.template拷贝并改名spark-env.sh
[root@bigdata02 conf]# cp spark-env.sh.template spark-env.shvim spark-env.sh,在最后添加如下内容,如下配置路径视情况修改
export JAVA_HOME=/usr/local/src/jdk8
export SCALA_HOME=/usr/local/src/scala-2.12.11
export SPARK_HOME=/spark/spark-2.4.8-bin-hadoop2.7
export SPARK_MASTER_HOST=bigdata02
export SPARK_EXECUTOR_MEMORY=1G
分发Spark安装配置信息到从节点
在bigdata02上依次执行
[root@bigdata02 spark]# scp -r spark-2.4.8-bin-hadoop2.7 root@bigdata03:/spark/spark-2.4.8-bin-hadoop2.7/
[root@bigdata02 spark]# scp -r spark-2.4.8-bin-hadoop2.7 root@bigdata04:/spark/spark-2.4.8-bin-hadoop2.7/修改环境变量配置文件
在主节点bigdata02上修改配置文件 vim /etc/profile,以下路径视本机情况而定
export JAVA_HOME=/usr/local/src/jdk8
export JRE_HOME=${JAVA_HOME}/jre
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/hadoop/hadoop-2.7.7
export SCALA_HOME=/usr/local/src/scala-2.12.11
export SPARK_HOME=/spark/spark-2.4.8-bin-hadoop2.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin保存修改并退出后,执行加载命令使之生效
source /etc/profile
启动集群Spark
在Master节点即bigdata02上,进入sbin路径并执行启动Spark集群命令 ./start-all.sh
[root@bigdata02 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /spark/spark-2.4.8-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-bigdata02.out
bigdata02: starting org.apache.spark.deploy.worker.Worker, logging to /spark/spark-2.4.8-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata02.out
bigdata03: starting org.apache.spark.deploy.worker.Worker, logging to /spark/spark-2.4.8-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata03.out
bigdata04: starting org.apache.spark.deploy.worker.Worker, logging to /spark/spark-2.4.8-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata04.out分别在三个节点用jps命令查看启动节点内容(注:此三个节点之前做过ApacheHadoop的集群并启动着)
[root@bigdata02 sbin]# jps
1776 NameNode
2292 NodeManager
67574 Master
67722 Jps
67645 Worker
1919 DataNode[root@bigdata03 conf]# jps
1692 DataNode
1884 NodeManager
75053 Jps
1775 SecondaryNameNode
74990 Worker[root@bigdata04 spark-2.4.8-bin-hadoop2.7]# jps
2128 ResourceManager
1796 NodeManager
66361 Worker
66445 Jps
1677 DataNode
验证Spark集群环境
浏览器输入 ip+8080端口 如:http://192.168.173.132:8080/
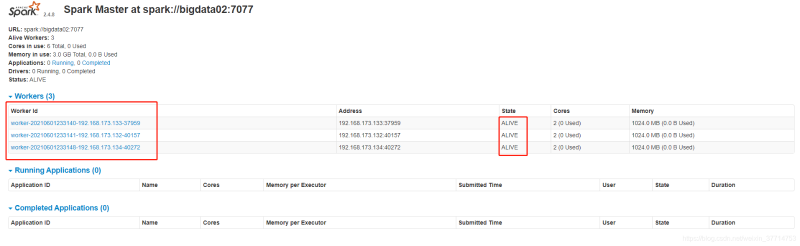 4. Centos 7安装配置Hadoop 2.7.7
4. Centos 7安装配置Hadoop 2.7.7
https://www.songbin.top/post_47911.html
注意:本文归作者所有,未经作者允许,不得转载

