前置知识
编程语言
至少应该掌握一门编程语言,计算机专业的同学大多学的第一门编程语言是 C 语言,然后再学 Java 语言,对于零基础的同学,可直接学习 Java 语言,至少应该把 Java SE 阶段学完!
计算机基础
如果你是计算机相关专业,相信你这些基础都已经会了,可以直接略过本节,往下看。但是如果你是零基础,还是需要先掌握下计算机行业必备知识,不管哪个岗位,只要是计算机相关,都应该熟悉,至少了解如下课程
-
计算机网络
-
操作系统
-
数据结构
-
计算机组成原理
以上课程也是计算机专业考研四门课,如果有时间,还是应该学习下!
如果时间紧迫,全部学完以上课程也不现实,所以可重点学习如下知识点
-
计算机网络(重点看 OSI 七层模型 或 TCP/IP 五层模型 理解每层含义)
-
数据结构(重点看 数组、栈、队列、链表、树)
-
算法(重点看 各种 排序算法、查找算法、去重算法,最优解算法,多去 LeetCode 刷算法题)
-
操作系统(重点看 进程、线程、IO、调度、内存管理)
大数据就业方向
因为大数据涉及到的知识相对比较广泛,全部学精难度太大,所以现在企业在招聘的时候会细分大数据岗位,专注于某个方向招聘,所以先解下大数据的都有哪些就业方向,然后你在后续的学习过程中对哪部分比较感兴趣就重点关注那部分
从上帝视角看一张图,了解下大数据所处的位置及与相关岗位的关系
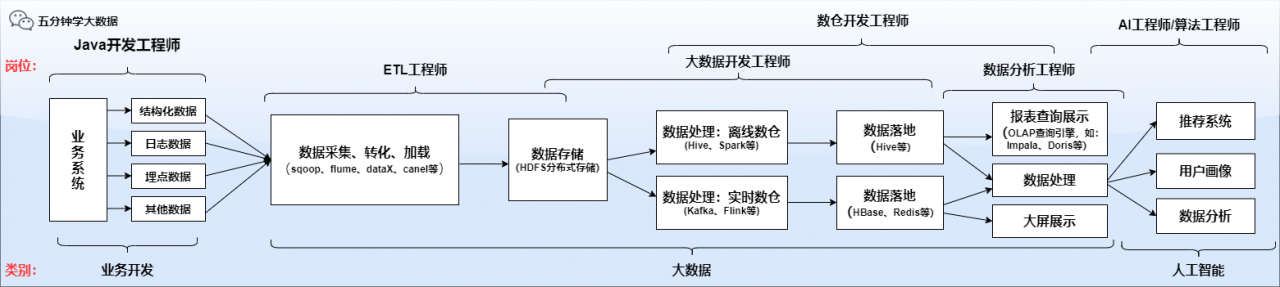

-
数仓工程师 (全称:数据仓库工程师)
数仓工程师日常工作一般是不写代码的,主要以写 SQL 为主!
数仓工程师是大数据领域公司招聘较多的岗位,薪资也较高,需要重点关注!
数据仓库分为离线数仓和*实时数仓*,但是企业在招聘时大多要求两者都会,进入公司之后可能会专注于离线或实时其中之一。
就目前来说,大多数的企业还是以离线数仓为主,不过未来趋势肯定是实时数仓为主,所以学习时,为了现在能找到工作,需要学习离线数仓,为了以后的发展,需要学习实时数仓。所以,离线和实时都是我们重点掌握的!
需要掌握的技能:
不管离线还是实时,重中之重就是:**SQL**
SQL 语法及调优一定要掌握,这里说的 SQL 包括 mysql 中的 sql,hive 中的 hive sql,spark 中的 spark sql,flink 中 的 flink sql。
在企业招聘的笔记及面试中,一般问的关于 sql 的问题主要是以 hive sql 为主,所以请重点关注!
除 sql 外,还需要重点掌握以下技能,分为离线和实时
离线数仓需要重点掌握的技能:
– Hadoop(HDFS,MapReduce,YARN)
– Hive(重点,包括 hive 底层原理,hive SQL 及调优)
– Spark(Spark 会用及了解底层原理)
– Oozie(调度工具,会用即可)
– 离线数仓建设(搭建数仓,数仓建模规范)
– 维度建模(建模方式常用的有范式建模和维度建模,重点关注维度建模)
实时数仓需要重点掌握的技能:
– Hadoop(这是大数据基础,不管离线和实时都必须掌握)
– Kafka(重点,大数据领域中算是唯一的消息队列)
– Flink(重中之重,这个不用说了,实时计算框架中绝对王者)
– HBase(会使用,了解底层原理)
– Druid(会用,了解底层原理)
– 实时数仓架构(两种数仓架构:Lambda 架构和 Kappa 架构)
-
大数据开发工程师
数据开发工程师一般是以写代码为主,以 Java 和 Scala 为主。
大数据开发分两类,第一类是编写 Hadoop、Spark、Flink 的应用程序,第二类是对大数据处理系统本身进行开发,如对开源框架的扩展开发,数据中台的开发等!
需要重点掌握的技能:
– 语言:Java 和 Scala(语言以这两种为主,需要重点掌握)
– Linux(需要对 Linux 有一定的理解)
– Hadoop(需理解底层,能看懂源码)
– Hive(会使用,能进行二次开发)
– Spark(能进行开发。对源码有了解)
– Kafka(会使用,理解底层原理)
– Flink(能进行开发。对源码有了解)
– HBase(理解底层原理)
通过以上技能,我们也能看出,数据开发和数仓开发的技能重复率较高,所以很多公司招聘时 大数据开发 和 数仓建设 分的没有这么细,数据开发包含了数仓的工作!
-
ETL 工程师
ETL 是三个单词的首字母,中文意思是抽取、转换、加载
从开始的图中也能看出,ETL 工程师是对接业务和数据的交接点,所以需要处理上下游的关系
对于上游,需要经常跟业务系统的人打交道,所以要对业务系统比较熟悉。比如它们存在各种接口,不管是 API 级别还是数据库接口,这都需要 ETL 工程师非常了解。
其次是其下游,这意味着你要跟许多数据开发工程师师、数据科学家打交道。比如将准备好的数据(数据的清洗、整理、融合),交给下游的数据开发和数据科学家。
需要重点掌握的技能
– 语言:Java/Python(会基础)
– Shell 脚本(需要对 shell 较为熟悉)
– Linux(会用基本命令)
– Kettle(需要掌握)
– Sqoop(会用)
– Flume(会用)
– MySQL(熟悉)
– Hive(熟悉)
– HDFS(熟悉)
– Oozie(任务调度框架会用其中一个即可,其他如 azkaban,airflow)
-
数据分析工程师
在数据工程师准备好数据维护好数仓后,数据分析师就上场了。
分析师们会根据数据和业务情况,分析得出结论、制定业务策略或者建立模型,创造新的业务价值并支持业务高效运转。
同时数据分析师在后期还有数据爬虫、数据挖掘和算法工程师三个分支。
需要重点掌握的技能:
– 数学知识(数学知识是数据分析师的基础知识,需要掌握统计学、线性代数等课程)
– 编程语言(需要掌握 Python、*R*语言)
– 分析工具(*Excel*是必须的,还需要掌握 Tableau 等可视化工具)
– 数据敏感性(对数据要有一定的敏感性,看见数据就能想到它的用处,能带来哪些价值)
大数据学习路线
系统的学习大数据相关的课程,可按照如下顺序学习
需要先掌握 Java SE 阶段,Linux 基础命令,MySQL 数据库
如果上述基础技能没有掌握,可网上搜索相关课程进行学习(这类基础课程网上免费的特别多)
Java 只需要学习 Java SE 阶段即可
会在虚拟机中安装 Linux 发行版本(建议安装 CentOS),学完 Linux 基础即可。
MySQL 需要学习 sql 语法,范式,事务等。
如果以上技能你都掌握的话,接下来就进入大数据框架
可按照如下顺序进行学习(涵盖 ETL、数仓、开发等岗位)
hadoop -> zookeeper -> hive -> flume && sqoop -> azkaban && oozie -> 数仓建模理论+实践 -> hbase -> redis -> kafka -> elk -> scala -> spark -> kylin -> flink -> 实时数仓项目
以上为大数据学习必备知识!!!
学完以上技能后,有时间还需要学习比较流行的 OLAP 查询引擎
Impala 、 Presto、Druid 、 Kudu 、 ClickHouse 、 Doris
如果还有时间,可以学习数据治理相关的内容,如元数据管理,数据湖等
Atlas 、 Hudi
大数据必备技能学习
先来看下大数据各个组件的图标,根据图标我们先来猜一下部分组件的作用。


我作的这幅图把 Hadoop 放在了核心位置,旁边都是围着它的组件,说明了 Hadoop 的重要性,需要重点学习,后面的一切都是以 Hadoop 为基础的。
从图中能看出这些组件的图标大多是动物,而左下角的 zookeeper 的图标是人,为动物园管理者,所以从图标中我们也能猜出 zookeeper 是用来管理这些大数据框架的。
再来看下 Hive,大象头,蜜蜂的身体,大象是 Hadoop,蜜蜂是采蜜的,所以我们猜测 Hive 作为数据仓库和 Hadoop 密不可分的,并且收集数据的。
HBase 作为数据库,图标是鲸鱼,鲸鱼是世界上最大的动物,代表 HBase 是存储巨量的数据。
Impala 是一个 OLAP 查询分析引擎,图标是一个斑羚羊,斑羚羊的特点就是跑的特别快,所以 Impala 是查询速度特别快的一个交互式查询分析引擎。
Flink 是一个松鼠,松鼠的特点就是快速和灵巧,和 Flink 的理念相吻合。
版权声明: 本文为 InfoQ 作者【大数据技术指南】的原创文章。
原文链接:【https://xie.infoq.cn/article/9bc68ee9416fcb4d2d6db700f】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。
本文来自infoq,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://xie.infoq.cn/article/9bc68ee9416fcb4d2d6db700f
注意:本文归作者所有,未经作者允许,不得转载

