信息论中的熵对于离散的随机变量是比较直观的,也就是信息量的数学期望,具体来说,就是:
(1) 

但是对于连续的随机变量,熵的概念就要复杂得多,这篇文章来探讨一下。
现实世界中有很多连续随机变量的例子,比如每天12:00pm的温度,或者17岁男子的身高,等等。连续随机变量的特点在于它的值域是连续的(也就是实数R,或者说有无限多的可能的值)。对于连续随机变量,取每一个具体的值的概率都是无限接近无穷小,而概率只对一个取值的区间才有意义。
连续随机变量的概率通常用概率密度函数来描述,如下图所示:
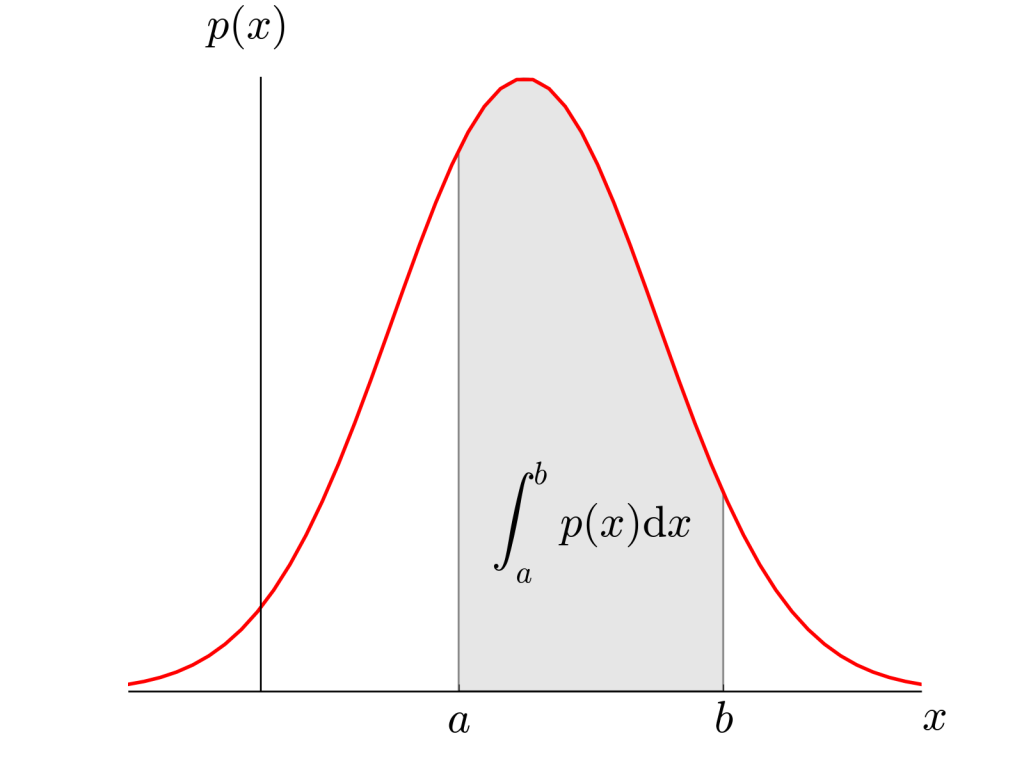

在上图中函数
 就是概率密度函数,x的值落在区间(a,b)的概率相当于:
就是概率密度函数,x的值落在区间(a,b)的概率相当于:
(2) 

根据概率的定义,我们有:
(3) 

有了概率密度函数以后,按照离散变量的熵,连续变量的熵可以表示如下:
(4) 

然而上述的积分值在 
 的时候趋近于无穷大。推导如下:
的时候趋近于无穷大。推导如下:
(5) 

上式中的第二项,考虑到积分的定义就是 的过程中求和的极限,但是在逼近极限过程中的每一个时刻  都是一个确定的常量,再考虑到概率密度函数的定义:
都是一个确定的常量,再考虑到概率密度函数的定义: ,上式可以进一步化简如下:
,上式可以进一步化简如下:
(6) 

很明显 
 在 的时候趋近于无穷大,所以整个熵的值就是无穷大。
在 的时候趋近于无穷大,所以整个熵的值就是无穷大。
在实践中,如果我们把  看作随机变量值域上的区间,那么在区间划分得越来越小的时候,计算所得的熵确实是越来越大,但是对于所有的连续随机变量,这一项()的大小是一样的(也就是相互等价),因此对于连续的随机变量,如果我们舍去上面的第二项而只保留第一项,我们就得到了微分熵的定义如下:
看作随机变量值域上的区间,那么在区间划分得越来越小的时候,计算所得的熵确实是越来越大,但是对于所有的连续随机变量,这一项()的大小是一样的(也就是相互等价),因此对于连续的随机变量,如果我们舍去上面的第二项而只保留第一项,我们就得到了微分熵的定义如下:
(7) 

这个将会是一个有限的值,而且可以在不同的连续随机变量之间互相比较。
连续随机函数的传统熵定义为无限大,这一点怎么理解呢? James V Stone 在他的书中提供了一种直觉的解释。连续随机函数的取值为实数,而实数的精度是无限位的,这在信息学的角度来说就相当于提供了无限的信息,自然其熵为无限大。正是他在书中把 看作随机变量的取值区间,然后在 的条件下推出来每个区间越来越小,里面的熵也就越来越大。如前所述,对于所有的连续随机变量,后面这一部分(也就是第二部分)无穷大全部都是互相等价的,所以去掉它以后留下的微分熵 (7) 就为一个连续随机变量的信息量提供了可以互相比较的描述。
本文来自zhangxiaopan.net,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhangxiaopan.net/?p=2897&continueFlag=f6af37f48f4447fcbea8a2ccfd8fca78
注意:本文归作者所有,未经作者允许,不得转载

