第一部分
1.数据基本情况探索
2.数据来源及预处理
3.数据相关性探索
第二部分
1.Cox风险比例模型建模
2. Cox风险比例模型效果评估
3.Cox风险比例模型预测流失用户
4.改善运营策略,防止用户流失
生存分析(survivalanalysis)源于生物医学,早期主要是是对生存时间进行分析,后来该方法也应用于各类商业分析,主要研究用户从一种状态转变到另一种状态所经历的时间。举个例子来说,在互联网行业,用户流失是较为常见的分析主题,生存分析法就可以运用于探究用户从进入互联网产品到流失这一过程的转变时长。这一期内容,小编会运用生存分析方法通过Python预测用户流失周期。
1
数据基本情况探索
此处笔者使用IBM用户流失数据集,该数据及来源于Kaggle,包括每个客户所签署的服务、客户账号信息以及用户个人信息等多个维度的用户属性数据。在该数据集中,流失用户的定义为在上个月之内离开的用户,数据集已经给出用户流失标签。
在正式作数据预处理之前,数据分析师需要了解数据的基本情况,比如查看数据有哪些字段、各个字段是什么类型、有没有缺失值、异常值等情况。数据分析师对数据的基本情况做到心中有底对后续的数据预处理和分析都是有极大帮助的。首先,通过如下代码读入数据并且查看基本情况。
#导入此次分析所需要的包
import math as mt
import numpy as np
import pandas as pd
from scipy.stats import norm
import scipy
import matplotlib.pyplot as plt
import seaborn as sns
survival_data=pd.read_csv("survival_ananlysis_data.csv")
survival_data.info()
<class'pandas.core.frame.DataFrame'>
RangeIndex:7043 entries, 0 to 7042
Datacolumns (total 21 columns):
Column Non-Null Count Dtype
customerID 7043 non-null object
gender 7043 non-null object
SeniorCitizen 7043 non-null int64
Partner 7043 non-null object
Dependents 7043 non-null object
tenure 7043 non-null int64
PhoneService 7043 non-null object
MultipleLines 7043 non-null object
InternetService 7043 non-null object
OnlineSecurity 7043 non-null object
OnlineBackup 7043 non-null object
DeviceProtection 7043 non-null object
TechSupport 7043 non-null object
StreamingTV 7043 non-null object
StreamingMovies 7043 non-null object
Contract 7043 non-null object
PaperlessBilling 7043 non-null object
PaymentMethod 7043 non-null object
MonthlyCharges 7043 non-null float64
TotalCharges 7043 non-null object
Churn 7043 non-null object
dtypes:float64(1), int64(2), object(18)
memoryusage: 1.1+ MB由上述的结果可知,IBM用户流失数据集中,包括了数值变量,也包括了分类变量。对于数值变量来说,数据分析师需要了解数值变量的数值范围,而对于分类变量来说,数据分析师则需要知道分类变量有多少种类别。在数值类型字段中,’TotalCharges’字段不仅存在缺失值,而且不是数值类型,所以需要先填补缺失值并将其转换为数值形式。如下代码实现了’TotalCharges’缺失值的填补、数值类型的转换以及数值变量基本信息的展示。
survival_data['TotalCharges']= survival_data[['TotalCharges']].replace([' '], '0')
survival_data['TotalCharges']= pd.to_numeric(survival_data['TotalCharges'])
survival_data.describe().transpose()
count mean std min 25% 50% 75% max
SeniorCitizen 7043.0 0.16 0.37 0.00 0.00 0.00 0.00 1.00
tenure 7043.0 32.37 24.56 0.00 9.00 29.00 55.00 72.00
MonthlyCharges 7043.0 64.76 30.09 18.25 35.50 70.35 89.85 118.75
TotalCharges 7043.00 2279.73 2266.79 0.00 398.55 1394.55 3786.60 8684.80
了解了数值变量的基本信息,如下代码实现了分类变量的基本信息的展示。
survival_data.describe(include='object').T
count unique top freq
customerID 7043 7043 6128-AQBMT 1
gender 7043 2 Male 3555
Partner 7043 2 No 3641
Dependents 7043 2 No 4933
PhoneService 7043 2 Yes 6361
MultipleLines 7043 3 No 3390
InternetService 7043 3 Fiberoptic 3096
OnlineSecurity 7043 3 No 3498
OnlineBackup 7043 3 No 3088
DeviceProtection 7043 3 No 3095
TechSupport 7043 3 No 3473
StreamingTV 7043 3 No 2810
StreamingMovies 7043 3 No 2785
Contract 7043 3 Month-to-month 3875
PaperlessBilling 7043 2 Yes 4171
PaymentMethod 7043 4 Electronic check 2365
Churn 7043 2 No 5174对于较为重要的字段,我们进行数据可视化展示,如下代码实现了用户留存时间、每月付费、总付费三个字段在流失用户和留存用户之间的差异对比以及整个数据集中流失和留存用户的数量展示。
fig,axes= plt.subplots(nrows=2,ncols=2, figsize=(10,8))
keyvalue= survival_data[['tenure','MonthlyCharges','TotalCharges']]
for ax,column in zip(axes.ravel(),keyvalue):
sns.boxplot(x=survival_data['Churn'],
y=keyvalue[column], ax=ax)
plt.tight_layout()
sns.countplot(x=survival_data['Churn'],alpha=.95)如图1所示,该数据集中留存用户远远多于流失用户,留存用户的留存时间、总消费金额长于流失用户,但留存用户的月付费金额少于流失用户。
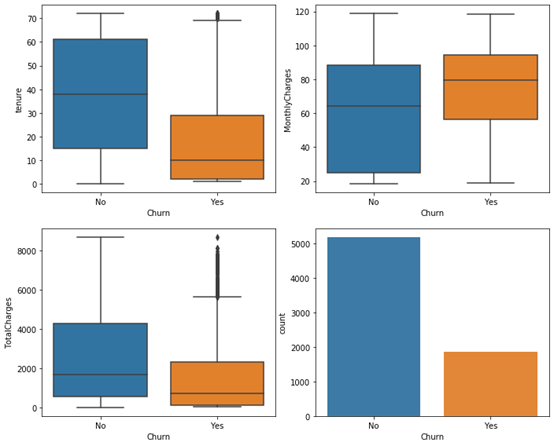

图1流失与费流失用户各个特征对比
Cox风险比例模型是用户流失分析中较为常用的方法,该模型不仅可以预测用户是否会流失,还能预测用户何时流失,下面一起来看看Cox风险比例模型如何预测用户流失。
1
Cox风险比例模型预测流失用户
经过上述一系列的铺垫,终于进入了Cox风险比例模型。首先,我们通过sklearn的train_test_split函数将数据集按照8:2的便利分为训练集和测试集;其次,利用lifelines包中的CoxPHFitter函数实现数据拟合,如下代码是Cox风险比例模型建模的过程。
from sklearn.model_selection import train_test_split
train_data,test_data = train_test_split(data, test_size=0.2)
from lifelines import CoxPHFitter
formula= 'MultipleLines_No+ `MultipleLines_No phone service`+ MultipleLines_Yes+InternetService_DSL+ `InternetService_Fiber optic`+ InternetService_No+ OnlineSecurity_No+`OnlineSecurity_No internet service`+ OnlineSecurity_Yes+`Contract_Month-to-month`+ `Contract_One year`+ `Contract_Two year`+OnlineBackup_No+ `OnlineBackup_No internet service`+ OnlineBackup_Yes+DeviceProtection_No+ `DeviceProtection_No internet service`+DeviceProtection_Yes+ TechSupport_No+ `TechSupport_No internet service`+TechSupport_Yes+ StreamingTV_No+ `StreamingTV_No internet service`+StreamingTV_Yes+ StreamingMovies_No+ `StreamingMovies_No internet service`+StreamingMovies_Yes+ `PaymentMethod_Bank transfer (automatic)`+`PaymentMethod_Credit card (automatic)`+ `PaymentMethod_Electronic check`+`PaymentMethod_Mailed check`+ gender+ Partner+ Dependents+ PhoneService+PaperlessBilling+ MonthlyCharges+ TotalCharges'
model =CoxPHFitter(penalizer=0.01, l1_ratio=0)
model =model.fit(train_data.drop("customerID",axis=1), 'tenure',event_col='Churn',formula=formula)
model.print_summary()模型的汇总信息如下所示,生存模型中我们输入的生存时间列为’tenure’,观察的事件列为’Churn’,代表用户是否流失。在训练集中一共有5634个样本,其中观察到1478个流失事件。
model lifelines.CoxPHFitter
durationcol 'tenure'
eventcol 'Churn'
penalizer 0.01
l1 ratio 0
baselineestimation breslow
numberof observations 5634
numberof events observed 1487
partiallog-likelihood -9985.37模型的效果相关的指标,包括了一致性指数(Concordance Index)、赤池信息量准则(Akaike information criterion)以及似然比检验(Likelihood ratio test)等等指标。一致性指数最大值为1,此处生存分析模型的一致性指数高达93%,说明Cox风险比例模型效果还是不错的。
Concordance 0.93
PartialAIC 20046.74
log-likelihoodratio test 4270.54 on 38 df
-log2(p)of ll-ratio test inf部分特征的模型系数如下图所示,如果系数是正的,那么该特征更容易是客户流失;如果是负的,那么拥有该特征客户则不太容易流失。模型还给出了特征的显著性。从分析结果来看,签署两年合同,即‘Contract_Two year’特征对于用户的留存是具有积极正向作用的,且在95%的置信度下是具有显著性的,这个分析结果和之前相关分析的结果是一致的。除此之外,‘同伴’即‘Partner’这个特征对用户留存也是具有积极的影响,同样在95%的置信度下也是显著的。
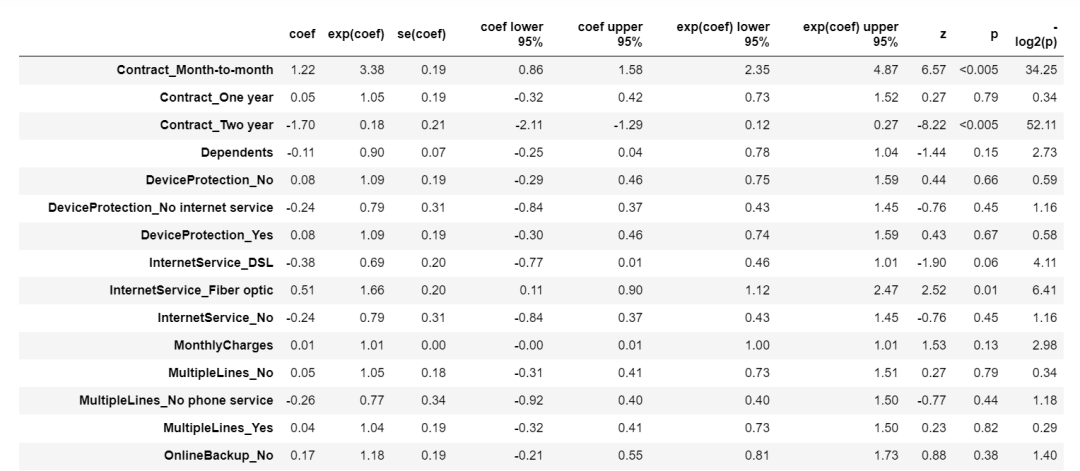

2
Cox风险比例模型效果评估
(1)一致性指数
Cox风险比例模型的评判标准是一致性指数(Concordance Index),该指标是针对模型内不一致性的评估。对于Cox风险比例模型的一致性可以这样理解,如果某个特征的风险增加了,那么具有该特征的观察结果风险会高。如果Cox回归模型满足上述原则,那么模型一致性会上升;如果不是,一致性会下降。如下代码绘制了Cox风险比例模型风险比例。
plt.figure(figsize= (8,10))
model.plot(hazard_ratios=True)
plt.xlabel('HazardRatios (95% CI)')Cox风险比例模型的一致性趋势如图1所示,分析结果显示该模型满足一致性原则。
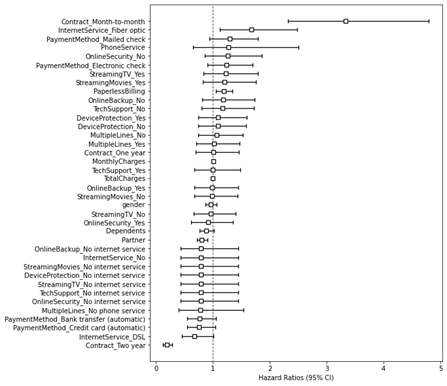

图 1 Cox比例风险模型的一致性检验
最后,输出Cox模型的一致性指数,实现过程如下代码所示。
from lifelines.utils import concordance_index
C_index =concordance_index(train_data['tenure'],-model.predict_partial_hazard(train_data.drop('customerID',axis=1)),train_data['Churn'])
print('The concordance of the Cox model on the testsubsample is: ', round(C_index*100),'%')
The concordance of the Cox model on the testsubsample is: 93 %(2)校准曲线(Calibration )
校准曲线是使用连续数据离散化的方法判断模型的预测概率是否接近于真是概率。理想情况下,校准曲线是一条对角线,即预测概率等于真是概率。Cox风险比例模型的校准曲线可以通过如下代码实现。
from sklearn.calibration import calibration_curve
plt.figure(figsize=(10, 10))
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
ax1.plot([0, 1], [0, 1], "k:",label="Perfectly calibrated")
probs =1-np.array(model.predict_survival_function(test_data).loc[13])
actual = test_data['Churn']
fraction_of_positives, mean_predicted_value =calibration_curve(actual, probs, n_bins=10, normalize=False)
ax1.plot(mean_predicted_value,fraction_of_positives, "s-", label="%s" %("CoxPH",))
ax1.set_ylabel("Fraction of positives")
ax1.set_ylim([-0.05, 1.05])
ax1.legend(loc="lower right")
ax1.set_title('Calibration plots (reliabilitycurve)')如图2所示,Cox风险比例模型的校准曲线接近对角线,但在曲线底端高估了用户的留存概率,即低估了流失率;而在曲线的上端则低估了用户的留存概率,即高估了流失率。
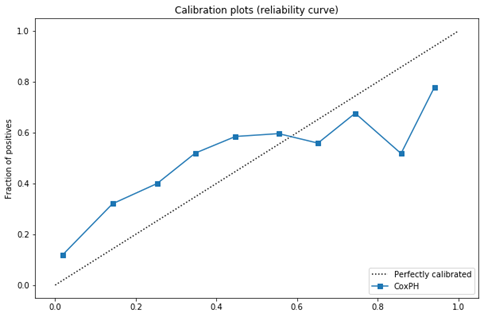

图2 Cox风险比例模型的校准曲线
本文来自cloud.tencent.com,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://cloud.tencent.com/developer/article/1854510
注意:本文归作者所有,未经作者允许,不得转载

