基本概念
Cochran-Armitage检验,是一种线性趋势检验,指经过logistic变换后呈现线性变化趋势。适用于处理分组变量为有序分类变量(K≥3),结局变量为二分类变量,即K×2列联表资料,因此又称趋势卡方检验。
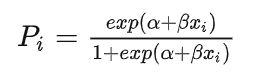
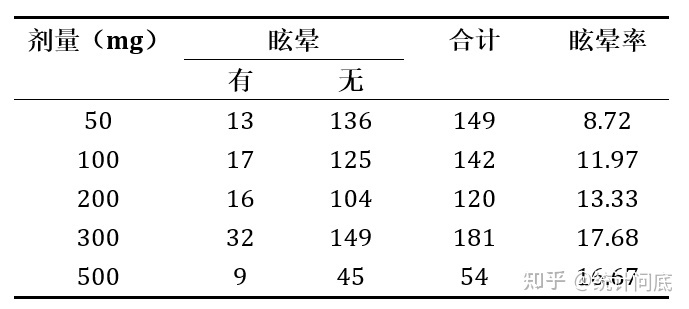
例:研究者想分析偏头痛药物的剂量与药物眩晕副作用是否存在线性关系。

无效假设
H0:P1=P2=……=Pk
备择假设
单侧(上升趋势):H1:P1<P2<……<Pk
单侧(下降趋势):H1:P1>P2>……>Pk
双侧:H1:P1<P2<……<Pk或H1:P1>P2>……>Pk
在线性趋势检验中,需要用到变量在卡方检验中没有用到的顺序信息,这就面临着如何对变量进行赋值的问题,不同的赋值方法得到的检验结果显然不同。
《Cochran-Armitage趋势检验不同赋值的模拟研究》一文对Cochran-Armitage趋势检验中的三种赋值方法,即等距赋值、均秩赋值、MERT法赋值,通过计算机模拟进行比较,发现三种方法的检验效能非常接近,但Ⅰ类错误率以等距赋值方法最低。综合模拟结果和应用的便利性,有序分类数据的Cochran-Armitage趋势检验采用等距赋值更值得提倡。
等距赋值:指相邻两个等级赋值的差为一个不等于0的常数。如本例的五个等级可以赋值为1、2、3、4、5,也可以赋值为1、3、5、7、9,也可以赋值为50、100、150、200、250,这些赋值最终的分析结果都是一样的。
均秩赋值:即按照每个等级的平均秩次进行赋值赋值。如本例的五个等级可以赋值为x1=(1+149)/2=75、x2=149+(1+142)/2=220.5、x3=149+142+(1+120)/2=351.5、x4=149+142+120+(1+181)/2=502、x5=149+142+120+181+(1+54)/2=619.5
MERT法:采用极大极小效率原理进行赋值。
R语言
1. Cochran-Armitage检验
CochranArmitageTest(),默认等距赋值
CAT <- matrix(c(13, 136, 17, 125, 16, 104, 32, 149, 9, 45), nrow = 5, byrow = T)
dimnames(CAT) <- list("Dose" = c("50", "100", "200", "300", "500"),
"Dizziness" = c("Yes", "No"))
CAT

library(DescTools)
CochranArmitageTest(CAT)

2. Logistic回归(将Dose作为连续型变量)
H0:β=0
library(rstatix)
CAT_df <- counts_to_cases(CAT)
CAT_df$DoseC <- NA
CAT_df$DoseC[CAT_df$Dose == "50"] <- 1
CAT_df$DoseC[CAT_df$Dose == "100"] <- 2
CAT_df$DoseC[CAT_df$Dose == "200"] <- 3
CAT_df$DoseC[CAT_df$Dose == "300"] <- 4
CAT_df$DoseC[CAT_df$Dose == "500"] <- 5
fit <- glm(Dizziness ~ DoseC, family = binomial(link = "logit"), CAT_df)
summary(fit)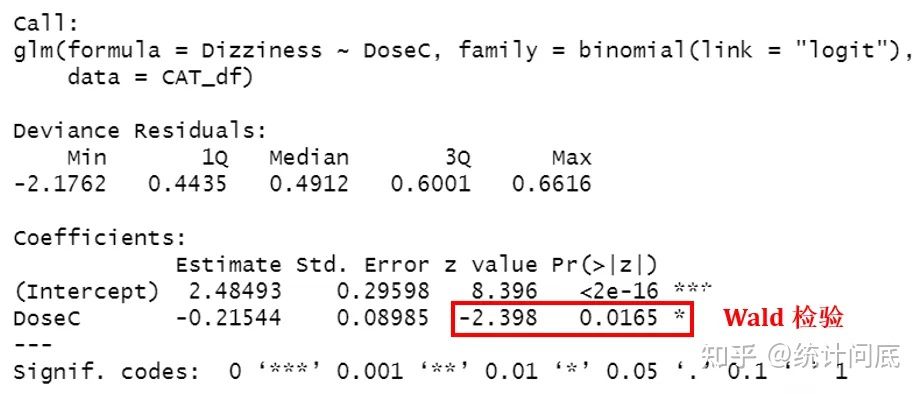

3. CMH检验(Correlation统计量)
library(vcdExtra)
CMHtest(CAT, types = "cor")

SAS
1. Cochran-Armitage检验
默认原始数值,不另外赋值
data CAT;
input Dose Dizziness Count;
cards;
50 1 13
50 0 136
100 1 17
100 0 125
200 1 16
200 0 104
300 1 32
300 0 149
500 1 9
500 0 45
run;
proc freq data = CAT;
table Dose * Dizziness / trend nocol nopercent scores = table;
weight Count;
run;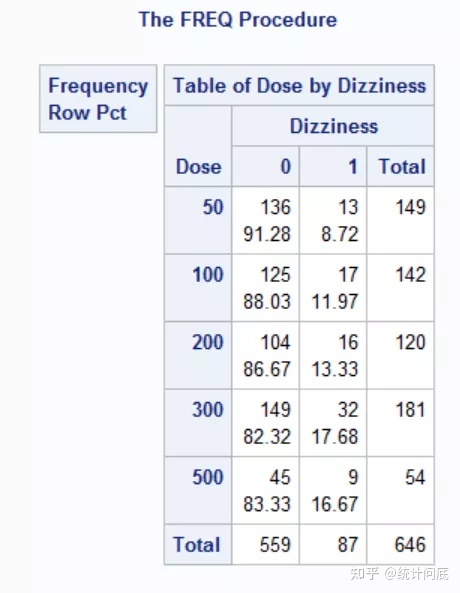

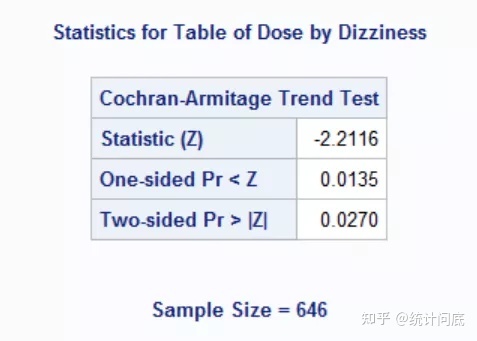

等距赋值
data CAT2;
set CAT;
if Dose = 50 then DoseC = 1;
if Dose = 100 then DoseC = 2;
if Dose = 200 then DoseC = 3;
if Dose = 300 then DoseC = 4;
if Dose = 500 then DoseC = 5;
run;
proc freq data = CAT2;
table DoseC * Dizziness / trend nocol nopercent scores = table;
weight Count;
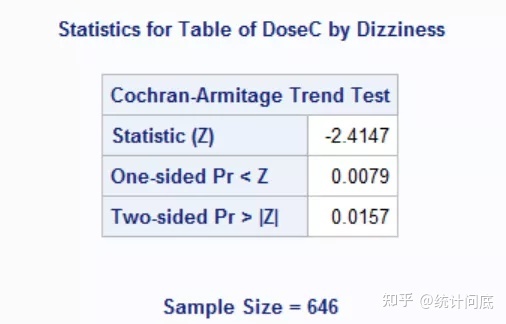
run;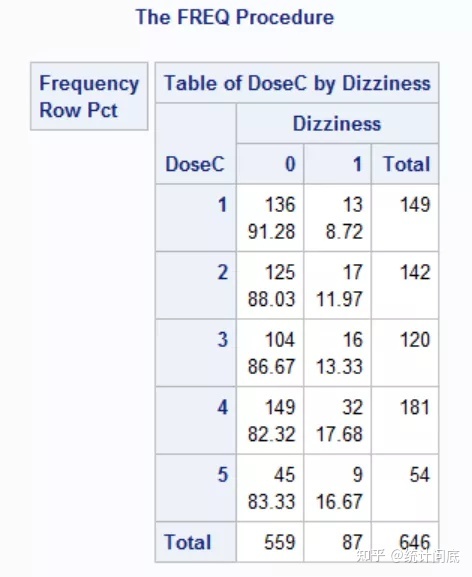


2. Logistic回归(将Dose作为连续型变量)
Score检验的结果等价于Cochran-Armitage检验的结果
proc logistic data = CAT2;
Model Dizziness = DoseC / cl rl;
weight Count;
run;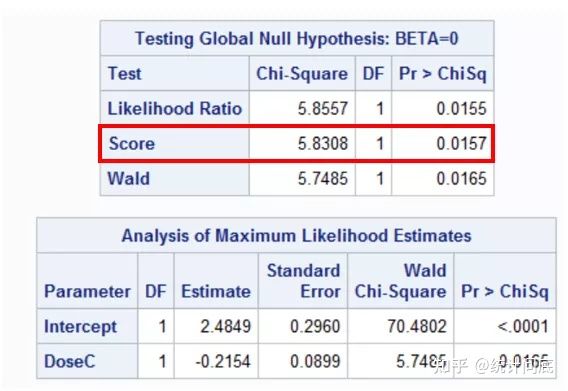

SPSS
SPSS不直接提供Cochran-Armitage Trend Test,可用Linear-by-Linear Association (LLA) test代替进行线性趋势检验。
![]()
![]()
N为样本量,r为两个变量之间的Pearson相关系数
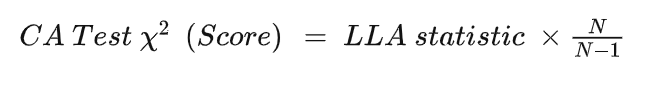
1. Linear-by-Linear Association (LLA) Test
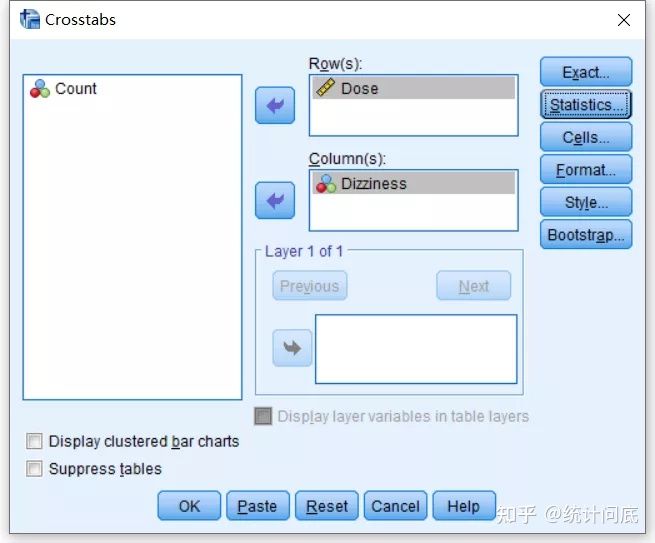

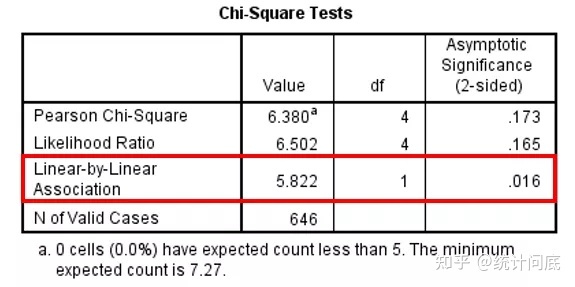

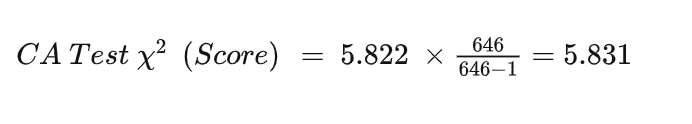
2. Logistic回归(将Dose作为连续型变量)
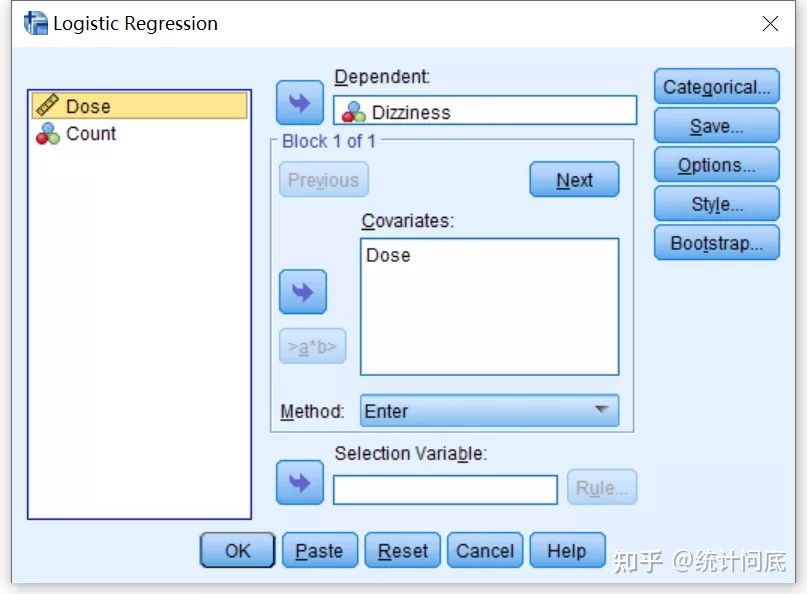

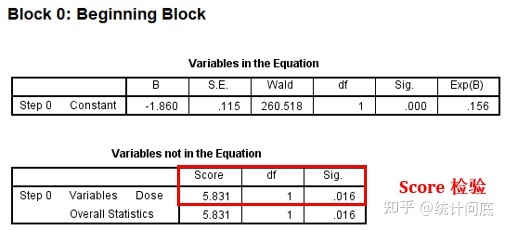

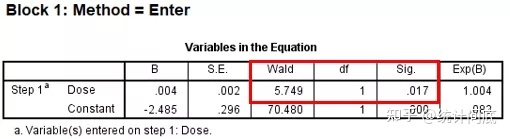
Block0为空模型,即只有截距,没有其他协变量。Variables not in the Equation为每一个协变量单独加入模型中时的contribution。

手动计算
N为样本量,Y为事件数,ni为各等级的样本量,yi为各等级的事件数,xi为有序分类变量的赋值
1. 正态近似法
采用等距赋值(1、2、3、4、5)
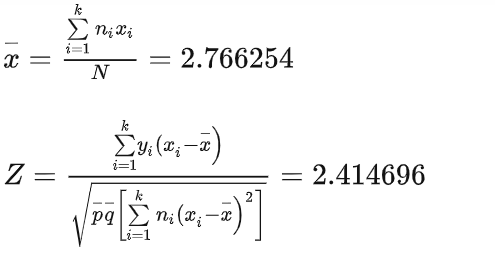
不另外赋值(50、100、200、300、500)

2. 构建卡方统计量
采用等距赋值(1、2、3、4、5)
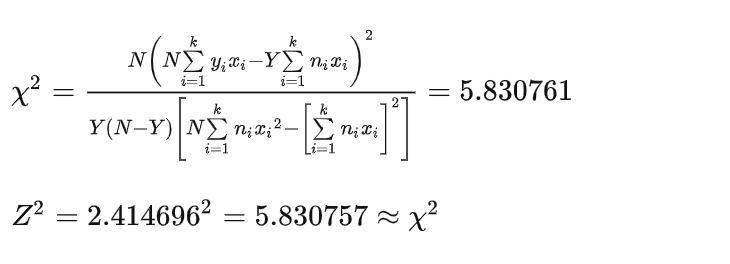
不另外赋值(50、100、200、300、500)
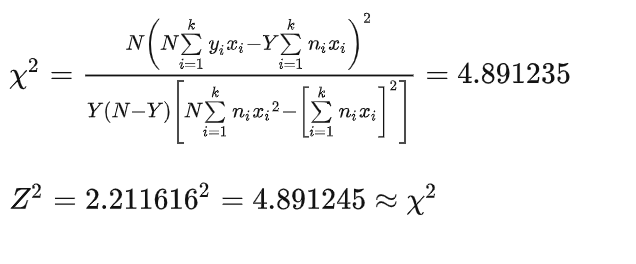
其它
1. 卡方检验 vs 单因素logistic回归
单因素logistic回归的结果和卡方检验的结果是等价的。在logistic回归中,对于整个模型和回归系数的检验采用的是似然比检验(LR)、Wald检验以及Score检验,三者输出的统计量均服从卡方分布。Score检验的 值等于卡方检验的Pearson 值,同样似然比检验的 值等于卡方检验的似然比 值。
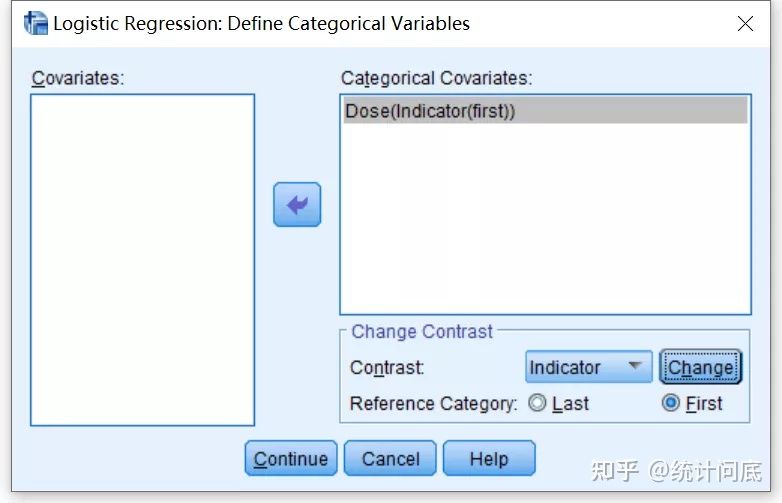
2. 在回归分析中,对于分类变量, SPSS和SAS默认Last作为Reference,R语言默认First作为Reference。我个人比较习惯以First作为Reference,SPSS和SAS改为First Reference的操作如下:
SPSS

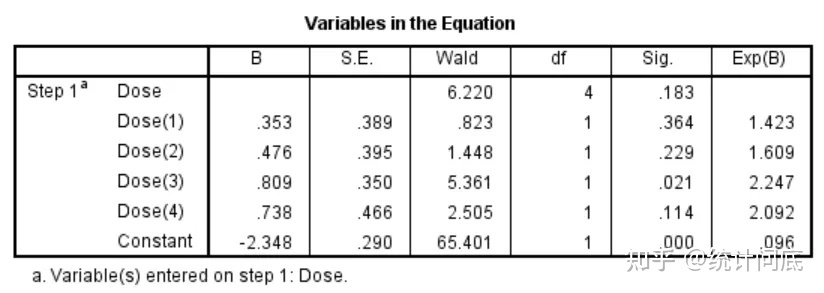

SAS
proc logistic data = CAT;
class Dose (param = ref ref = first);
Model Dizziness = Dose / cl rl;
weight Count;
run;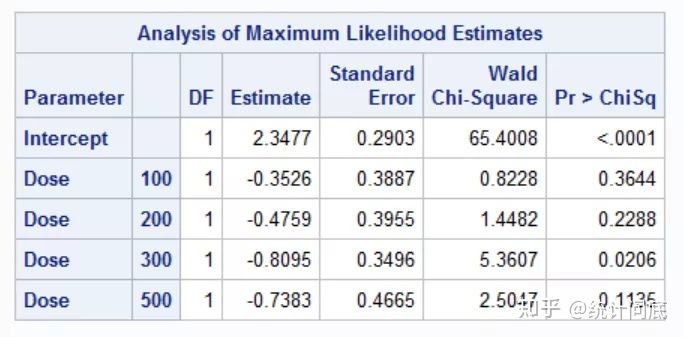

R
CAT_df$Dizziness <- factor(CAT_df$Dizziness)
CAT_df$Dose <- factor(CAT_df$Dose)
fit2 <- glm(Dizziness ~ Dose, family = binomial(link = "logit"), CAT_df)
summary(fit2)

参考文献
Cochran-Armitage趋势检验不同赋值的模拟研究《中国卫生统计》
Cochran-Armitage Trend Test Using SAS
https://www.lexjansen.com/pharmasug/2007/sp/SP05.pdf
Cochran-Armitage test for trend for 2xI tables
https://www.ibm.com/support/pages/cochran-armitage-test-trend-2xi-tables
搞懂传统单因素分析和单因素回归分析的纠葛,有这篇文章
本文来自zhihu,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhuanlan.zhihu.com/p/450066515
注意:本文归作者所有,未经作者允许,不得转载

