概述
奇异值分解 (Singular Value Decomposition),是一种矩阵分解技术,经常用于机器学习降维处理。它通过将空间维度从 N 维减少到 K 维(其中 K<N)来减少数据集的特征数量。SVD 也常作为协同过滤技术在推荐系统中发挥不可忽视的作用。它使用矩阵结构,其中每一行代表一个用户,每一列代表一个项目。 该矩阵的元素是用户对项目的评分 。
这个矩阵的分解是通过奇异值分解来完成的。 它从高级(用户-项目-评分)矩阵的分解中找到矩阵的因子。奇异值分解是一种将矩阵分解为其他三个矩阵的方法:
A = USVT
其中A是一个m x n的效用矩阵,U是一个m x r的正交左奇异矩阵,表示用户与潜在因素之间的关系,S是一个r x r的对角矩阵,描述每个潜在因素的强度,V是一个r x n的对角右奇异矩阵,表示项目和潜在因素之间的相似性。这里的潜在因素是项目的特征,例如音乐的流派。SVD 通过提取其潜在因子来降低效用矩阵 A 的维数。它将每个用户和每个项目映射到一个 r 维潜在空间。 这种映射有助于清楚地表示用户和项目之间的关系。
让每个项目由一个向量 xi 表示,每个用户由一个向量 yu 表示。用户对项目的预期评分r^ui可以如下给出:
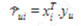

这里,是奇异值分解中的一种分解形式。 xi 和 yu 可以通过它们的点积与用户项目矩阵中的期望评分之间的平方误差差最小的方式获得。 它可以表示为:


为了让模型能够很好地泛化而不过度拟合训练数据,在上面的公式中添加了一个正则化项作为惩罚:


为了减少模型预测值与实际值之间的误差,该算法使用了偏差项。对于一个用户-项目对 (u, i),μ 是所有项目的平均评分,bi 是项目 i 的平均评分减去 μ,bu 是用户 u 给出的平均评分减去 μ,添加了正则化项和偏差项的最终方程可以如下给出:


上述等式是适用于基于奇异值分解的推荐系统的算法的主要组成部分。
基于奇异值分解 (SVD) 的电影推荐
下面是电影推荐任务中基于协同过滤的奇异值分解(SVD)的实现。 这个任务是用 Python 实现的。 为简单起见,我们使用了 MovieLens 1M 数据集。 选择此数据集是因为它不需要任何预处理。
导入所需的python库:
import numpy as np
import pandas as pd从系统中下载数据集的位置读取数据集。 它由两个需要读取的文件“ratings.dat”和“movies.dat”组成:
data = pd.io.parsers.read_csv('data/ratings.dat', names=['user_id', 'movie_id', 'rating', 'time'],
engine='python', delimiter='::')
movie_data = pd.io.parsers.read_csv('data/movies.dat', names=['movie_id', 'title', 'genre'],
engine='python', delimiter='::')创建评级矩阵,其中行作为电影,列作为用户:
ratings_mat = np.ndarray(shape=(np.max(data.movie_id.values), np.max(data.user_id.values)),
dtype=np.uint8)
ratings_mat[data.movie_id.values-1, data.user_id.values-1] = data.rating.values标准化矩阵:
normalised_mat = ratings_mat - np.asarray([(np.mean(ratings_mat, 1))]).T计算奇异值分解 (SVD):
A = normalised_mat.T / np.sqrt(ratings_mat.shape[0] - 1)
U, S, V = np.linalg.svd(A)定义一个函数来计算余弦相似度。 按最相似排序并返回前 N 个结果:
def top_cosine_similarity(data, movie_id, top_n=10):
index = movie_id - 1 # Movie id starts from 1 in the dataset
movie_row = data[index, :]
magnitude = np.sqrt(np.einsum('ij, ij -> i', data, data))
similarity = np.dot(movie_row, data.T) / (magnitude[index] * magnitude)
sort_indexes = np.argsort(-similarity)
return sort_indexes[:top_n]定义一个函数来打印前 N 个相似的电影:
def print_similar_movies(movie_data, movie_id, top_indexes):
print('Recommendations for {0}: n'.format(
movie_data[movie_data.movie_id == movie_id].title.values[0]))
for id in top_indexes + 1:
print(movie_data[movie_data.movie_id == id].title.values[0])初始化 k 个主成分的值、数据集中给定的电影 id 以及要打印的top项目的数量:
k = 50
movie_id = 10 # (getting an id from movies.dat)
top_n = 10
sliced = V.T[:, :k] # representative data
indexes = top_cosine_similarity(sliced, movie_id, top_n)打印前 N 个相似的电影:
print_similar_movies(movie_data, movie_id, indexes)下面给出了一些示例输出:


Reference:
Aharon, M., Elad, M., & Bruckstein, A. (2006). K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Transactions on signal processing, 54(11), 4311-4322.
Ba, Q., Li, X., & Bai, Z. (2013, May). Clustering collaborative filtering recommendation system based on SVD algorithm. In 2013 IEEE 4th International Conference on Software Engineering and Service Science (pp. 963-967). IEEE.
本文来自zhihu,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://zhuanlan.zhihu.com/p/471215062
注意:本文归作者所有,未经作者允许,不得转载

