So, What is the Kano Model?
Noriaki Kano,一名日本研究学者、咨询师,他在1984年发表了一篇论文,提出一套帮助我们确定用户(和潜在用户)对产品性能满意度的想法和技术。这些想法通常被称为卡诺模型,它基于以下几项前提:
·用户对产品功能的满意程度取决于所提供功能的完善程度(即实现的程度或效果);
·功能需求可以被分为四类;
·可以通过问卷调查来确定用户对某项功能的看法。
接下来就各项展开论述。
Satisfaction vs Functionality
一切始于我们的目标 —— 用户满意度Satisfaction。卡诺将满意度维度的度量,从很满意(或高兴、兴奋)到很不满意(或失望)。
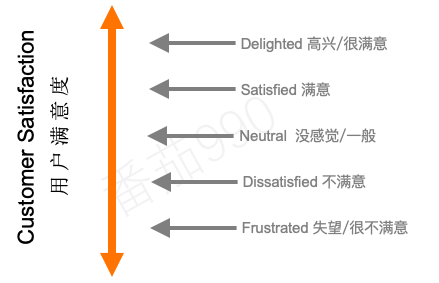

上图标注了用户不同的满意度,用来度量用户对某个功能/需求的满意程度。但需要注意的是,这并不是(总是)线性比例。
虽然我们想让用户的满意度一直处于Delighted程度,然而但是现实是…it’s not possible.
为什么?现在把话筒?️传给功能完备度Functionality。也可以称为投资度、成熟度或实现程度,它指的是用户获得多少特定功能、或某功能需求的实现程度,或某功能需求在开发中的投入程度。
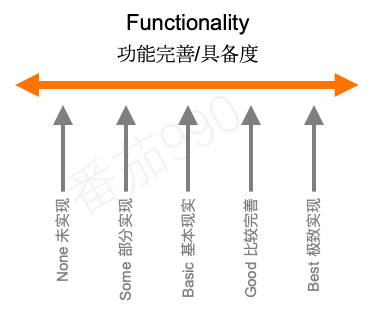

这一维度对某功能实现程度进行度量,从未实现到最佳实现。功能的不同实现程度对应的成本投入不同,因此称为投资量也是可以理解。
撇开命名不谈,最重要的是这两个维度放在一起便构成了卡诺模型的基础,且决定了用户对产品功能的感觉。
The Four Categories of Features
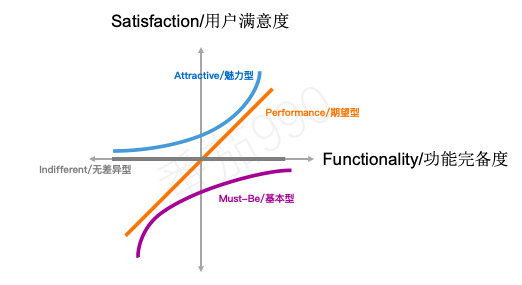
卡诺模型依照“功能完备度”及对应“用户满意度”,将功能需求分为四个类型,

Performance期望型
有些产品功能表现的正如我们对满意度直觉上的感受:我们提供的越多,用户就越满意。 由于功能完备度和满意度之间存在这种比例关系,这些功能在卡诺文献中通常称为线性,期望型或一维属性(推荐期望型)。
当你买车时,它的油耗通常就是期望型属性。 其他例子比如上网的网速;笔记本电脑的电池寿命; 或Dropbox帐户中的存储空间。每一种你拥有的越多,满意度就越高。
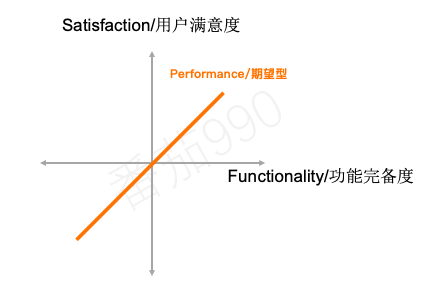

回到图示模型,从图中可以看出用户对这类功能的满意度变化。功能的每一次完善都会带来更高的满意度。但同时需要注意的是添加的功能越多,投资越大(例如,构建团队、所需资源等)
Must-be必须型
有些产品功能是用户预期的。 如果产品没有这些功能,就会被认为是不完整或完全没用的。 这种类型的功能通常称为“必须型”或“基本型”。
对于这类功能:产品是必须具备的,但具备并不代表用户会更加满意。用户对此的态度就只是没有不满意。
就像我们认为手机能打电话。旅馆房间应该有自来水和一张床。一辆车应该有刹车。具备这些功能并不会让我们兴奋,但缺少它们肯定会让我们对产品或服务感到愤怒。
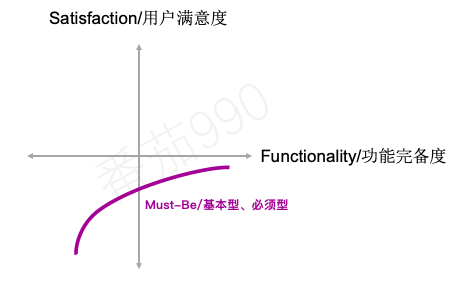

如这条满意度曲线所示,对于这类功能即使很少的投资,也能有明显的满意度提升。但需要注意的是,这类功能下的满意度是不可能有超“Neutral”程度的提升。 也就是说无论在产品功能上投入多少,用户都不会对产品表现出更高的满意度。好消息是,这类功能一旦达到基本的预期水平,就不必继续投资了。
Attractive魅力型
还有这样一类意想不到的功能,当这些功能被提出时总会引起积极的反馈。 这类功能通常被称为“魅力型”,“兴奋型”或“高兴型”。 推荐“魅力型”,因为它传达了一种观念,即我们谈论的是一种范围/程度。 我们的反应从温和的吸引到完全兴奋,都可以涵盖在“魅力型”的范围内。
第一次使用iPhone时,会因流畅的触摸屏界面感到惊喜。 第一次使用Google Maps或Google Docs。 正如当你体验到那些超出你对同类产品了解和期望时会有的那种感觉。
只要记住,对于这类功能不一定非要倾尽所有。任何功能都有可能让人赞一个:“哈!真8错!”。
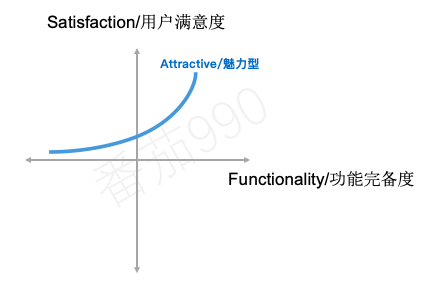

如上图曲线所示,可以看出横轴代表的不同程度的功能完备度所带来的用户满意度的提升,以及提升的速度。这对于我们在权衡某项给定功能的投资时至关重要。超过某一点,say BYEBYE。
Indifferent无差异型
当然,我们也会对某些功能毫不在意。它们的存在(或缺失)并不会对产品产生实质性的影响。
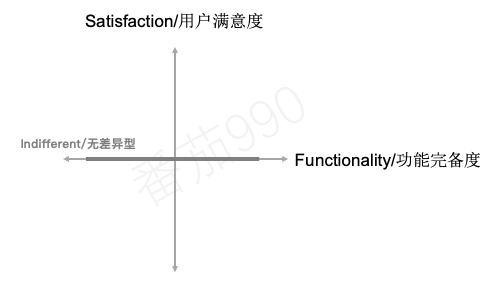

这类功能处于“满意度”维度的中间(与横轴相交)。这意味着无论我们投入多少精力,用户都不会真正在意。 换种说法,就是应该避免这类功能,它们本质上就是浪费金钱。
The Natural Decay of Delight
现在我们已经全面了解了Kano模型的所有功能分类,这里需要注意的是:它们并不是静态的——而是会随着时间的推移而发生变化。
用户现在对某些产品功能的特定感受不能代表将来的感受。现在属于魅力型的功能会随着时间的推移逐渐变成期望型和必须型。
再举iPhone这个例子,2007年让人兴奋不已的那种流畅的触摸屏交互放在现在就只是基本的预期。
想想过去那些让人们感到惊喜的产品。如果同样的产品现在呈现给你,会有什么感觉?在足够的时间过去后,那些曾经视为神奇的功能现在很可能已然成为一种期望型或必须型。
造成这种幻灭有许多因素,包括技术的发展和竞争对手的出现,这些都会促进对新功能神速般的复制。
这表明我们在某个特定时间点所做的任何分析都只是一张反映当时现实的照片。离那一时间点越远,相关度就越低。与钻石不同,卡诺分类并非恒定。
The Question Pair that Uncovers Customer Perceptions/揭示用户看法的问题对
现在我们已经介绍了Kano模型的前两个部分:分析的维数以及它们之间的相互作用,以定义功能需求的分类。
为了揭示用户对产品属性的看法,我们需要使用Kano问卷。问卷由多组问题对构成,每组问题对都是为某个功能设计,其中:
·一个问题是向用户提问,如果产品具备该功能,您觉得怎么样;
·另一个问题是向用户提问,如果产品不具备该功能,您觉得怎么样。
第一个问题是功能具备 的形式 ,第二个问题是 功能缺失的形式。但这些问题不是开放性问题,而是有非常具体的被选项。 对于每个“如果有/没有此功能,您的感觉如何”,备选项是:
·很喜欢
·应该如此
·无所谓,没感觉
·不喜欢,但还能忍受
·很不喜欢,难以接受
在使用这些选项时,还需要考虑一些事情,稍后将会讨论这些部分。
向用户(或潜在用户)提出这两个问题并获得他们的答案之后,下一步就可以对每个功能进行分类。
Evaluation table
关于Kano模型的一大优点是它同时考虑了具备和不具备某项功能。 这可以表明用户对某项功能实际想要,需要或漠不关心的程度。
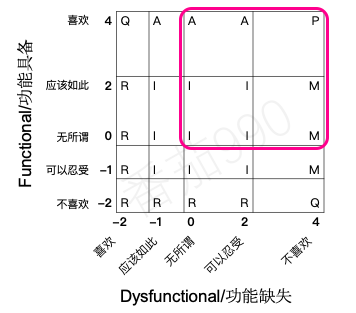
我们通过一份评估表来达到这一点,该评估表的行和列分别是功能具备和功能不具备的答案组合而得出的功能分类。每一对答案都指向其中的一个分类,使用该问题模版会多出两个新的分类。
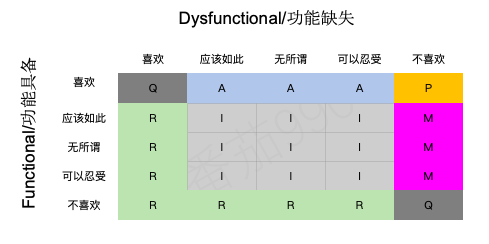

Two new categories
鉴于我们是从同一个功能的两个方面提出问题,由此可以判断是否:
·有人没能完全理解所描述的问题或功能;
·问题实际上与他们想要的正好相反。
这些并不是真正的卡诺分类;它们仅仅是问卷调查的产物(但仍然有用)。
如果有人说她“不喜欢”功能具备,而“喜欢”功能缺失,那么她显然对我们所提供的不感兴趣,或者说也许实际上想要的是相反的。这个新的功能类别被称为反向型。如果大多数用户都反馈某个功能是反向型,则只需交换功能具备和功能缺失问题并按此顺序提问统计答案。
当两个问题的回答相互矛盾时(例如“喜欢”和“喜欢”),那就会产生一个有疑问的结果。 Fred Pouliot建议将标准Kano评估表中的单元格(2,2)和(4,4)改为“可疑型”。这些结果中有些是可以预期的,但如果你得到大多数用户的答案有疑问的,那这份问卷的设计可能是有问题的。
A (slightly) revised evaluation table
现在,我们使用Pouliot稍微修改过的评估表来对用户答案进行分类。


要努力将每个分类从一对答案中推导出来的过程内在化,这样有助于更好地理解模型,且避免每次都要引用这张表。
之前已经讨论了有疑问的结果(相互矛盾的回答组合);除去中间的单元格,它们在评估表中形成对角线。
期望型功能最容易定位。 它们是用户喜欢拥有而不喜欢缺失的功能。 这种极端的反应转化成了这两个维度之间“越多越好”的线性关系。
必须型功能是用户“不喜欢”功能缺失的剩余情况。从可以容忍功能到理应具备功能。
魅力型功能是用户喜欢拥有的超预期功能。这是对于既新颖又有吸引力的功能描述的另一种说法。
无差异型功能。 对于那些“无所谓”或“可以容忍它”的答案,无论是功能具备问题还是功能缺失问题,都归于这类功能。 也就是说,它们占据了评估表的中间单元(除去前面描述的任何类别)。
最后是反向型功能。它沿两个轴定位,要么是喜欢没有该功能要么是不喜欢有该功能。可以通过翻转功能具备/功能缺失的值来查看它是哪个分类的反向。然后就可以判断出这是一个反向期望型、魅力型或者是必须型功能。
Using the Kano Model
现在我们已经对Kano模型的工作原理有了基本的了解,是时候就真实场景感受一下了。
产品经理和用户体验设计师的目标是确定哪些功能可以让用户更满意,并利用这些信息对产品功能需求进行排序。为了达到目的,还需要考虑一些重要的细节。
本节凝聚了多位研究学者在卡诺模型实践中得出的经验和总结的教训,包括每一步过程:
·选择功能和适合的用户;
·获取(尽可能有效的)用户数据;
·分析数据。
Step 1: Choose your target features and users
首先要考虑的是分析范围——包括功能和用户。
Choosing features
所要选择研究的功能应是那些用户能从中受益的功能。在备选池可能包含各种不同类型的功能诉求,比如技术负债清理、销售或营销团队报告系统、设计更新等。但这些都不在Kano分析的范围之内。
Kano模型研究的是用户对可感知、可操作功能的满意度,可产品的功能远不于此。如果是要获取能拒绝管理层等内部干系人某些诉求的支撑数据,使用Kano模型是危险的,它会让你的团队,用户和你自己产生混乱。
此外,还要限制问卷中包含的功能数量,特别是有志愿参与用户的情况。这样可以提高用户的参与度和专注度。
Selecting customers
在选择用户(或潜在用户)参与研究时,一定要考虑用户所属的人口统计学特征、社会群组或角色。否则最后得到的数据很可能是散布整张地图。
用户/潜在用户群可能不是同质的,他们对功能的感受也不相同。但如果考虑到他们所属的某些分组,就可以显著减少分析中的噪音。
Jan Moorman在向潜在用户介绍新产品功能时,意识到了这一点的重要性。该产品的核心功能已经存在,而且(据推测)是因竞争对手的产品而广为人知。 尽管如此,仍有一部分用户认为它是魅力型,而另一部分用户则认为它是必须型。 然后她得出结论,这些不同的反应是由于用户对市场的敏锐度。 当她按用户的个人资料对他们的回答进行细分时,每个功能的结果就更加清晰了。
虽然有各种细分可能性,但必须得选择对产品有意义的细分。 假设你正致力于B2B SaaS。 正在考虑添加一个允许用户将发票与采购订单相关联的功能,那这功能对小型企业和大企业客户的吸引力就有很大不同。
无论是在选择要研究的用户(因为你了解功能的目标),还是之后的分析所得的数据,都要记住这一点。
Step 2: Getting the (best possible) data from your customers
调查问卷及其显示方式是Kano研究的唯一输入。 因此,要确保此步骤的有效性。
Write clear questions
尽可能清晰、简洁的问题设计问卷的关键。每个问题都应该只代表单一功能。如果功能很复杂,而且包含多个步骤和子流程,那就需要进行拆分。
问题应该以用户利益相关的角度进行表述,而不是产品作用的角度。 例如,“如果您可以选择自动改善照片,您觉得怎么样?” 就好于“如果您拥有MagicFix™,您觉得怎么样?”。
同时要注意问题对的极性措词。 就是说,功能缺失问题并不一定是功能具备问题的对立面,它只是缺少功能而已。 来围观这个视频编辑app的示例,该示例考虑优化其导出速度:
功能具备问题:“如果导出任何视频的时间都在10秒以内,您觉得怎么样?”
错误的功能缺失问题:“如果导出任何视频的时间都超过10秒,您觉得怎么样?”
更合适的功能缺失问题:“如果导出某些视频的时间超过10秒,您觉得怎么样?”
Better than writing about features is to show them
尽可能直接给用户演示功能然后问她具备或不具备功能时的看法,这样比表述清楚的问题效果更好。
可以用文字描述功能优势,再用原型和交互式线框或模型来代替文本问题。 通过视觉和动态的“解释”,用户可以更清楚地了解这些功能和提问。
如果你以这种形式提出问题,那就应在用户与功能原型互动之后立即询问用户对标准备选答案的选择。 就像之前文字描述版问题一样。 这样用户就能始终保持清晰的记忆,不至于把这个功能与同一调查中的其他功能混淆。
Be mindful of the answers’ phrasing and understanding
有些人对Kano问卷中标准答案的顺序感到困惑。通常,他们不明白为什么“我喜欢那样”出现在“必须是那样”之前,而那样似乎是一种更为温和的说法。
以这种方式呈现答案的逻辑是,它们从高兴的程度一路啪啪啪降到避免不高兴的程度。还有一些可参考的替代措词,例如:
我喜欢那样
这是基本必需品,或者我希望这样
我是中立的
我不喜欢它,但可以容受
我不喜欢它,不能接受
或是这种,由Robert Blauth的团队撰写的:
这对我很有帮助
这是我的基本要求
这对我没影响
这有点麻烦
对我来说这是个严重的问题
实际上,我认为本指南开头介绍的选项列表在清晰性和简洁性之间达到了最佳平衡。
要点是我们要注意如何解释这些选项,且确保受访者理解调查问卷的目的也很重要。 选择最匹配的答案选项集,并事先向参与者解释说明各选项,这样可以有更好的结果。
Ask the customer about the feature’s importance
多个团队提出对Kano方法学的一个重要补充,是在功能具备/功能缺失组合之后加入另一个问题。这个问题询问用户这个功能对他们的重要程度。
获得这条信息对于区分彼此的功能、了解与用户最相关的功能非常有用。 它提供了一种区分大型功能与小型功能区的工具,以及它们是如何影响用户对产品的决策。
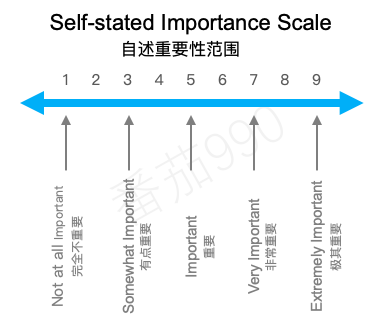
自述的重要性问题可以以下列形式提出:“它有多重要,如果:<条件>?”. 例如,“它有多重要,如果:导出视频所需时间总是不到10秒?”。
答案的范围应从1到9,从“完全不重要”到“极其重要”。

Test your questionnaire
如果可能的话,在将问卷传给用户之前,先与团队成员测试这个问卷。如果内部对问卷有任何困惑,那与外部人士探讨时肯定也存在。
Step 3: Analyze the Results
现在正式进入激动人心的快车道(我编的?️)。 在对收集的结果进行制表和处理后,就能够对功能进行分类,并深入了解确定功能优先级排序的最佳方法。
分析可以分为离散分析和连续分析。 这些术语只是我想出的,因为这些方法缺乏任何标准(或更好)的术语。 二者都是对数学概念的引用,并且与它们如何将参与者的结果与Kano的分类进行映射有关。
每种方法都很有用,具体取决于你需要的类型。
Discrete Analysis离散分析
我们处理Kano结果的最简单方法是:
根据所属的人口统计属性/角色标准来划分受访者;
使用评估表对每个受访者的答案进行分类;
统计每个功能(和人口统计属性)在每个分类的所有回答的数量;
功能的类别将是出现频次最高的回答(即模式);
如果各类别之间的结果接近,则使用以下规则(最左赢):必须型>期望型>魅力型>无差异型;
如果已要求受访者提供自述的重要性排名(并且应该这样做),请对每个功能取平均值。
最后你将得到这样一张表:


如果出现多个结果而没有一个明确的分类,则可能有隐藏的用户资料没有考虑到。 这种情况下,就要回到用户问卷中去寻找线索;尝试检查哪些用户的答案经常与其他用户的答案相同,从而找出可能没被发现的“人口统计集群”。
从结果表中,可以根据功能的重要性对其进行排序。此后,在确定优先级时使用的一般经验法则是:首当其冲所有的必须型功能,然后添加尽可能多的期望性功能,最后来一丢丢魅力型功能。
这种分析类型非常有助于获得初步了解,在许多不需要更严格方法(如测试设计思想或草拟路线图)的情况下非常有用。
Continuous Analysis连续分析
尽管离散分析可以很好地帮助我们入门并对结果有全面了解,但是它仍然存在一些问题。 即:
·在此过程中丢失了很多信息。 首先,从每位受访者的25个答案组合转变为六个Kano分类中的一个。 其次,所有受访者的答案进一步简化为每个功能的单一分类;
·对数据中存在的差异一无所知;
·赋予温和答案与强烈答案一样的权重。 只需想想对于魅力型功能,在功能缺失维度“应该如此”与“勉强忍受”的差别就能领会。
接下来的几节介绍的是Bill DuMouchel 提出的一种很不错的连续分析方法。 不用担心这些计算;本指南随附的电子表格已经完成了这些工作(拉到底部点击原文获取数据)。 目前仅专注于理解每个步骤。
Scoring Answers
首先,将每个答案选项转换为满意度量表范围内的对应数值,从-2到4。数值越大,答案就越能反映客户对该功能的想要程度。重要性也从1分到9分,和之前一样。
功能具备:-2(不喜欢), -1(忍受), 0(无所谓), 2(必须), 4(喜欢);
功能缺失:-2(喜欢), -1(必须), 0(无所谓), 2(忍受), 4(不喜欢);
重要性:1(完全不重要),…,9(极其重要)
你可能会认为功能缺失量值似乎是反向的。 NO。 分数(正)越高,表示满意度潜力越大。 对于功能缺失的答案,不喜欢某些功能意味着强烈反对该功能的缺失。 所以如果将其包括在内,则将有更高满意度的潜力,这就是为什么它具有更高的分数。
这种不对称比例(从-2开始而不是-4)是因为,从负向的答案中得出的分类(反向型和可疑型)比从正向的答案中获得的分类(必须型和期望型)更弱。 因此DuMouchel决定强化正向值。
这些分数将功能在一个二维平面内进行分类,就不再需要标准评估表。

分析的重点应放在正象限上,这个象限是最强烈的正面情绪回答。 除此之外表格中还有其他较弱的答案以及“可疑型”和“反向型”分类。 如果某个功能是“反向型”,可以利用之前介绍的技巧将其定位为对应的逆向分类,将分数分别调整为“功能具备”和“功能缺失”问题对调后的数值,这样一来就了有新的分类,biu!再去掉“反向型”分类。
A sidenote: Satisfaction and Dissatisfaction coefficients
在翻阅各种Kano资料时,经常会看到有关满意度和不满意度系数的引用。本节介绍的DuMouchel连续分析方法有更好的替代方法。 但考虑到它们被引用的频率,先得简单做个概述。
Mike Timko使用“Better”和“Worse”系数来反映用户对某个功能具备/缺失的满意或不满意变化。 但他并没在原稿中将其命名为“满意系数”和“不满意系数”,只是约定俗成的叫法。 先统计给定功能在每个分类中的答案总数,再套用以下公式进行计算:
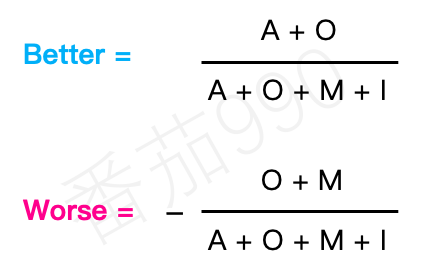

尽管它们确实产生了可用于相对比较的数值结果,但这些系数是有些问题的,Timko本人在他的文章中也提到了这些问题。最主要的是,它面临着和离散分析相同的问题:这些数值是建立在对所有受访者答案的合并简化得出的某一Kano分类基础之上。 这类信息的丢失会导致数据的不稳定性增加,以及对所有答案赋予相等权重而忽视其原有强烈/较弱的情绪。
使用DuMuchel的连续分析方法计算出的功能具备和功能缺失评分也能达到同样的目的,且没有该类问题,这也是重点关注它的原因。
Categorizing Features
如果对每个可能的答案都标有数值,那就意味着可以使用平均数。以下是我们需要为每个功能进行的计算:
1、所有功能具备、功能缺失和重要性答案的平均分值;
2、功能具备、功能缺失和重要性评分的标准差。
根据每个功能的功能具备和功能缺失的平均分值,可以将它们放在二维分类平面上,如下图所示:


当然目前讨论的是平均分值,但它们隐藏了数据中可能存在的巨大差异。这也是为什么将标准差以误差线的形式添加到图形中,这样可以从图中了解这个分类是符合还是偏离目标。如下图所示:
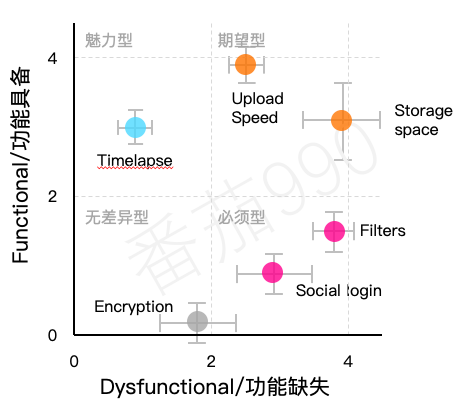

最后一步是添加重要性分数。可以通过将散点图中的点转换成气泡来可视化这一维度,气泡的大小与其重要性成比例。这样就能很容易地比较具有相似定位的功能需求。
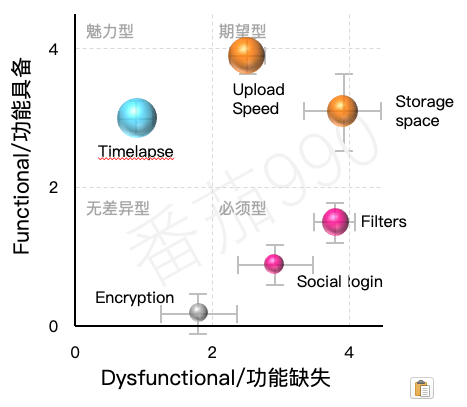

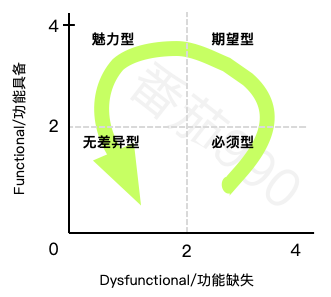
之前关于离散分析给出的一般优先级规则在这里仍然适用:必须型>期望型>魅力型>无差异型。这可以很好地转化为图形术语:

对于小功能集,另一种(可能更好的)可视化方法是通过堆栈排名列表。 表格分三列(从高分到低分)对功能进行排名:潜在不满意度,潜在满意度和重要性。 在这个案例中,前两列分别是功能缺失评分和功能具备评分。 如下图所示:
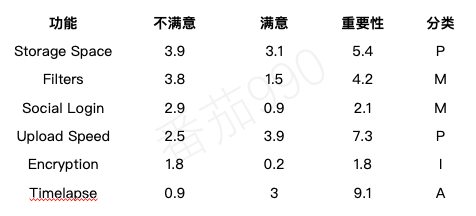

注意最后两行。 在那种情况下你会怎么做? 一个是对不满意有更大影响的无差异型功能(但其实非常接近必须型)。 另一个是能明显提高满意度并且用户认为很重要的功能。 在某些情况下我们需要优先考虑其中一个。 由此可见仅遵循一些排序并不能解决实际中的所有难题;很多情况下我们仍然需要做出艰难的选择,进行实验,测量和迭代。
Get started today: an approach (and toolset) to launch your own Kano study
是时候了!现在你已经了解了Kano模型的每个重要方面。现在是时候实际运用它了。
我知道现在还不能快速理清如何掌握这些知识并使之为你所用。但只要你想你就可以,即使是今天。
在本节中,我们将介绍一种实用的方法和工具组,你可以使用它们来进行自己的Kano分析。现在回到本指南第二部分中介绍的3个步骤。
第一步:选择你的目标功能和用户
你可能正致力于下一个产品版本的一些新的功能和想法。如果不是这样,即使可能暂时用不到也继续跟着做。
在你正在研究的功能/想法中:
·哪些让你有严重的选择困难症
·哪些对你的用户有直接影响?
·最多选3个(你可以在熟悉了所有这些之后,再做更多的研究,)
这些功能定位的是具有哪些人口统计特征的群体(或角色)?每个群体选择15个(或更多)用户。 如果你使用的是Intercomor或者Mixpanel,可以很容易地在目标范围内选择一部分用户。
第二步: 获取(最好的)用户数据
此步骤分为两部分:
·确定向用户(或潜在用户)提出的问题;
·创建和分发调查问卷以收集用户数据。
Defining the questions
调查问卷有两种呈现问题的方式:基于交互的和基于文本的。
基于交互
如果你开发的是软件产品,那可能会有关于想法和功能说明的线框图或原型。如果是这样,你就已经有了呈现给受访者的最好的“问题”。
你需要的做的是使这些线框图或原型具有交互性(如果还没有的话)。
使用ebalsamiq或者invision这样的工具,将线框链接在一起,以便它们可以交互。这将使该功能变得生动,还可以避免问题在文字措辞中的问题。
基于文本
如果没有任何可用的线框图或原型,可以使用传统的基于文本的问题形式。 但在提出清晰有效的问题时,要格外小心措辞。
Creating and distributing the survey
当然现在你需要创建一个问卷调查会获取用户反馈。 以下是需要考虑的事项:
·对问卷调查的目标,答案格式以及受访者需要做的事情做一个简短的解释;
·如果使用的是交互式线框图,需简要地描述功能的目标,提供线框图链接,并要求用户返回调查【在线框图末尾添加特殊注释,要求用户关闭选项卡并返回调查】;
·应在调查中标记一个用户标识符(例如他们的电子邮件),以便以后知道哪些用户已回复以及他们所属的特征群体/角色。
你可以使用URL参数创建一个带有电子邮件字段的Google表单。 在你向用户发送这样的消息时,就无需用户输入电子邮件地址(或其他标识符),你就收到被标识符标记的用户回答。
第三步:分析结果
在收集了足够的答案之后,进入分析步骤。
连同本指南一起,还有一个Excel电子表格,该电子表格将快速启动你的分析(下拉到底点击原文下载)。 它能执行以下操作:
·根据每个答案(功能具备,功能缺失和重要性),计算出离散分类,功能具备分数和功能缺失分数;
·计算每个功能的离散分析和连续分析的Kano分类;
·根据潜在不满意度,满意度和重要性对功能进行自动排名;
·绘制散点图,以显示每个功能的位置,相对重要性以及以误差线显示的数据方差。
你只需要将将问卷调查结果复制并粘贴到电子表格中,添加一些有关数据的详细信息(功能和用户)。
就可以立即得到基于Kano模型的优先级建议。 由此,你可以轻松地处理数据,创建一些数据透视表,开始深入研究细节。
Final thoughts
在确定产品功能的优先顺序时没有灵丹妙药。虽然我们要考虑许多不同的维度,但用户满意可能是最重要的。引出我们最开始讨论的问题:
·How do we measure satisfaction?
·How do we choose what to build in order to provide it?
·How do we go beyondsatisfaction and intodelight?
这些问题没有明确的答案(如果有的话,我们都需要另找工作)。
希望本指南为你提供的另一种工具可以添加到你用来打造kick-ass产品的兵工厂:Kano模型。 你已经了解了它是什么,如何使用它以及如何开始使用。
试试看。调整它。让它为你所用。把你的产品推向兴奋,让我知道进展如何。
本文来自简书,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://www.jianshu.com/p/affb22cb95c6
注意:本文归作者所有,未经作者允许,不得转载

