作者:彭碧辉
现任广州数驰信息科技有限公司技术总监,负责金融领域数据分析解决方案与实施。
一直懒于写作,没有把自己的知识点给大家分享,多谢朋友和同事提点,把自己在SAS领域的学习研究分享一下。先简单介绍下自己吧,本人接触SAS也有5年了,但这5年里我跟别人使用SAS不一样,大家可能是偏向SAS的coding和数据分析,而我则是更偏向SAS产品的使用。废话少说,今天给大家带来的是如何使用SAS EM里的信用评分模块快速开发信用评分卡。
首先,上个信用评分卡的流程,来个抛砖引玉,如下图:
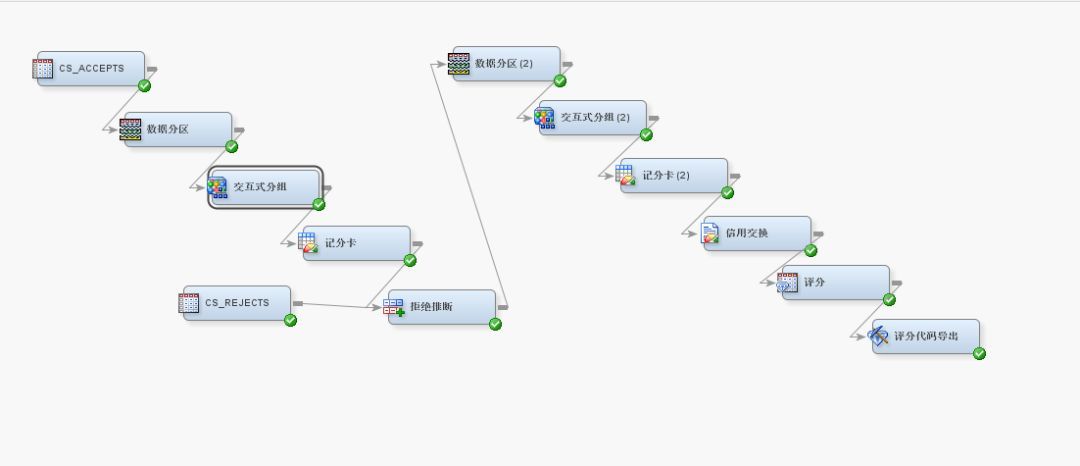

在SAS EM信用评分模块里几个主要组件有:
交互式分组:将变量值划分为若干个类,这些类可用作预测建模的输入。
记分卡:计算记分卡的尺度调整参数、显示各评分相关统计量的分布以及确定最优截止评分。
拒绝推断:通过推断未标记的评分数据集中的目标值来增加训练数据。该方法常用于解决样本选择偏差。
信用交换:创建跨记分卡桶的统计量表,与“信用风险”解决方案相整合。
下面我将详细介绍一下这几个组件,以便我们以后根据EM熟悉快捷开发评分卡。
1交换式分组
首先我们看看“交换式分组”的结果里有些什么,如下图:
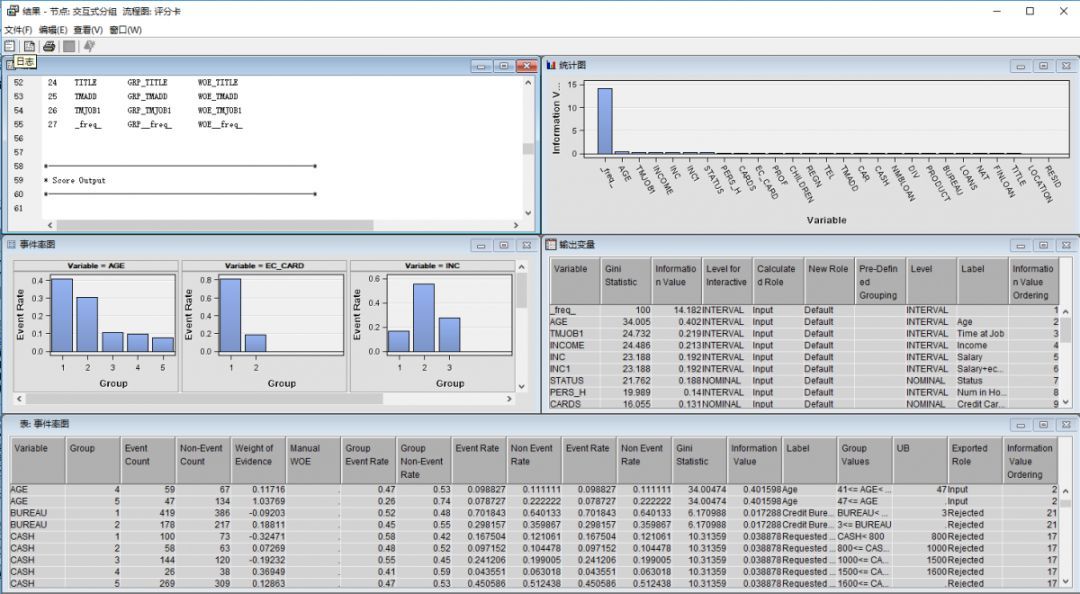

在这里我们能找到很多有价值的信息,譬如在“输出变量”里,可以看到输入变量的基尼统计量和信息价值(IV)。大家知道在分类模型中,基尼统计量衡量好坏样本的均匀程度。基尼统计量越大,好坏样本的均匀程度越不均匀,也意味着好坏样本分得越开。
基尼统计量的分割点为20。基尼统计量大于规定分割点的变量讲被选作为评分卡的输入。而IV值则为该特征属性的WOE的加权,该权值为这个属性中好客户在总好客户数中的比例与坏客户在总坏客户中的比例的差值。用于衡量一个变量的预测能力。IV值默认的分割点为0.1,如果IV值大于0.5,就是过预测变量。对于变量的一个分组,这个分组的响应和未响应的比例与样本整体响应和未响应的比例相差越大,IV值越大,否则,IV值越小。
一般来说,名义变量和连续变量都采用最优准则分段。对于名义变量来说,当类别数大于12个时,降低基数就变得非常必要,运用最优准则的算法是基于决策树模型所用的方法,是的某些预测力指标最大化,实现最优分群。对于连续变量来说,连续变量必须要分段,才能使用标准评分卡格式。信用评分卡开发中一般有等距分段和最优分段法。
若分箱结果不理想,可手动进行调整。调整后需要重新运行交互式分组。
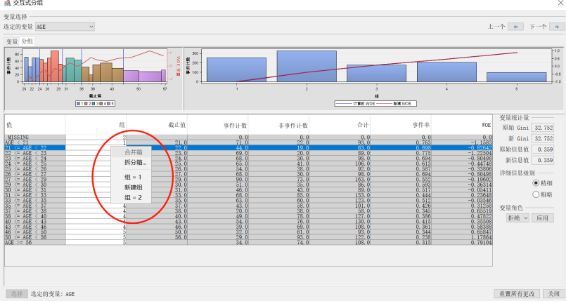

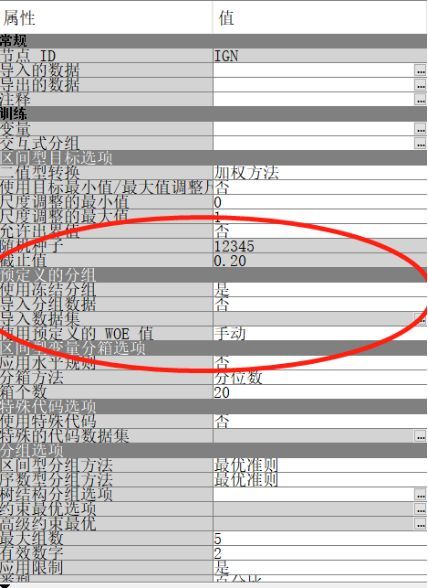

2记分卡
“记分卡”的运行结果,如下:
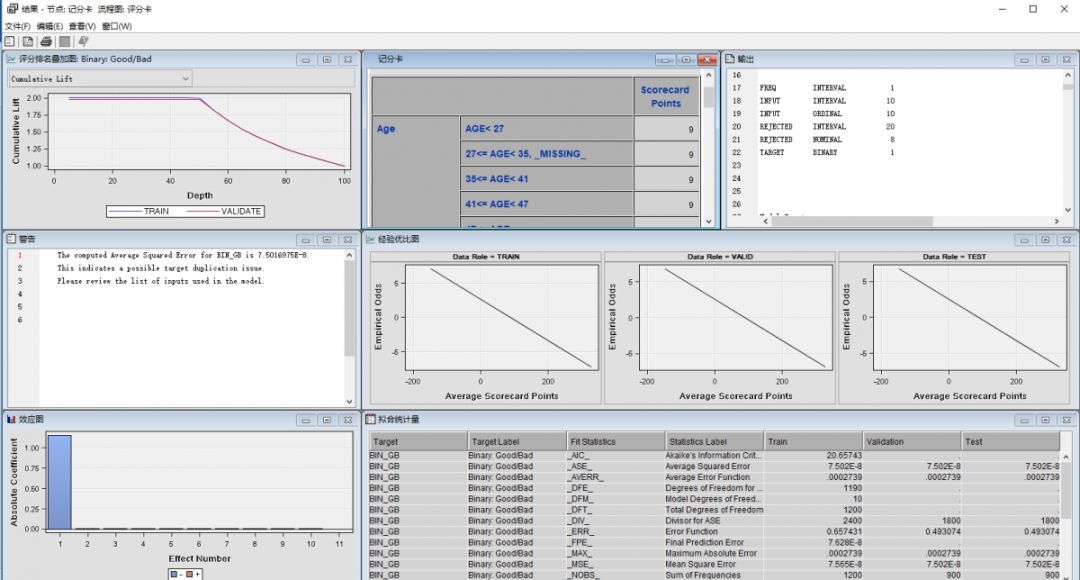

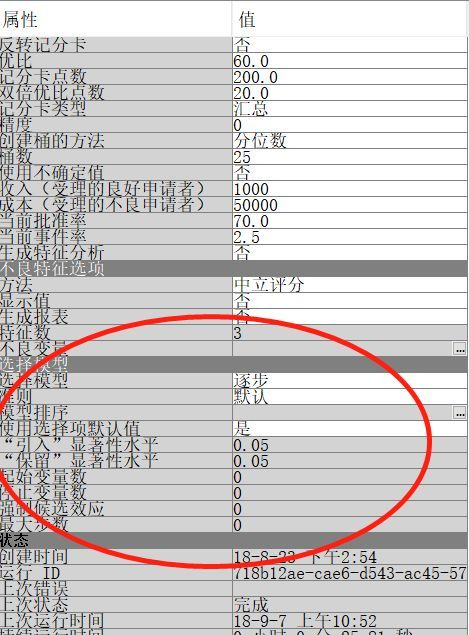
通过结果图我们来看看“记分卡”的相关属性设置。首先在“选择模型”里选择“逐步”(“选择模型”其实是指回归模型的属性选择,其包括“向前”、“向后”、“逐步”和“无”),选择逐步回归模型,也可以调整显著性水平等选项。

☞
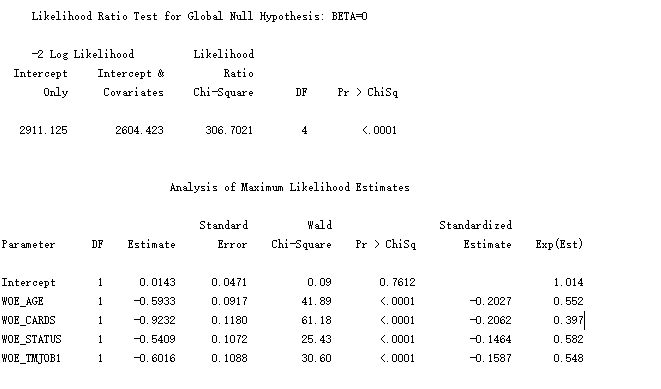

从结果中可以看到,WOE_AGE, WOE_CARDS, WOE_STATUS, WOE_TMJOB1在模型中是显著的。得到Logistic回归模型为:
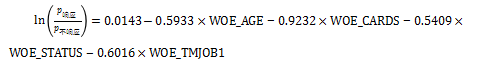

Logistic回归模型也可以改写为:
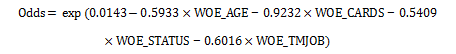

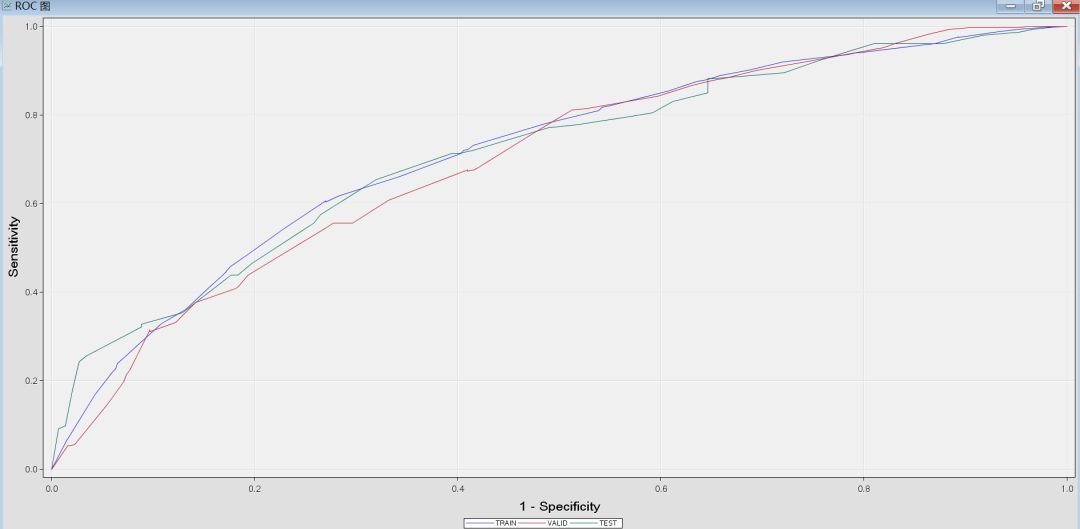
可以看出:
WOE_AGE每增加1个单位值时,发生比将会相应地缩小1.81倍;
WOE_CARDS每增加1个单位值时,发生比将会相应地缩小2.52倍;
WOE_STATUS每增加1个单位值时,发生比将会相应地缩小1.72倍;
WOE_TMJOB1每增加1个单位值时,发生比将会相应地缩小1.83倍;
模型评估:
①提升图与随机选择相比,模型的预测力提高了1.6倍。

②基尼系数(衡量坏账户数在好账户数上的累积分布与随机分布曲线之间的面积差异,好账户与坏账户分布之间的差异越大,GINI指标越高,表明模型的风险区分能力越强。)
训练集的基尼系数为0.43,测试集为0.42,好坏客户的差异较大,一般超过0.6以上表示模型精确分类程度很高。
| 基尼系数 | 解释能力 |
| 0 | 无 |
| 0-0.4 | 低 |
| 0.4-0.6 | 中 |
| 0.6-0.8 | 高 |
| >0.8 | 极高 |
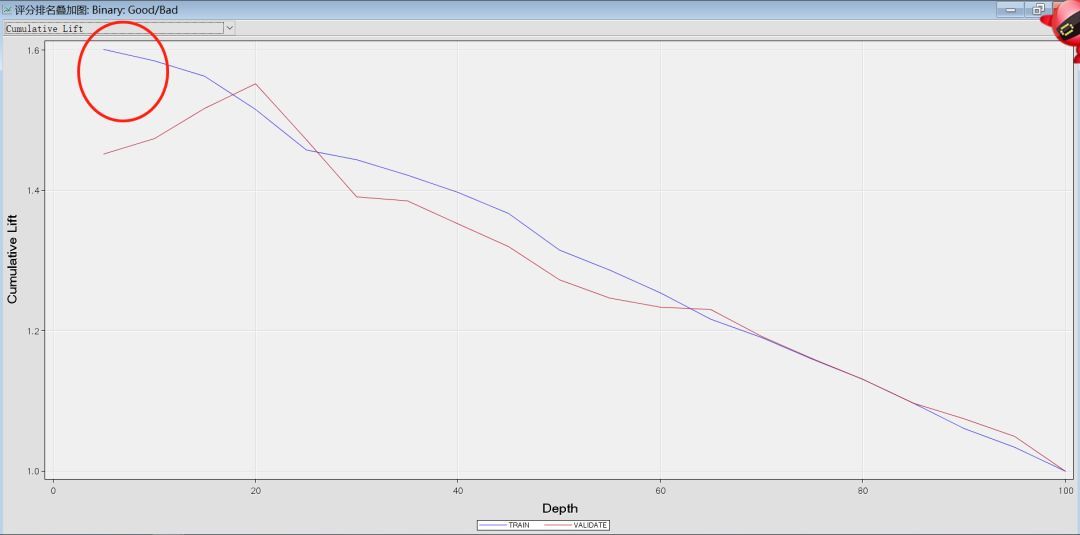
③K-S图(度量正例/反例分开的能力,指标衡量的是好坏样本累计分部之间的差值,检验这两组样本信用评分的分布是否有显著差异。好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。)

训练集中KS值约为0.34,测试集约为0.34,均大于0.2,认为模型有好的预测准确性。
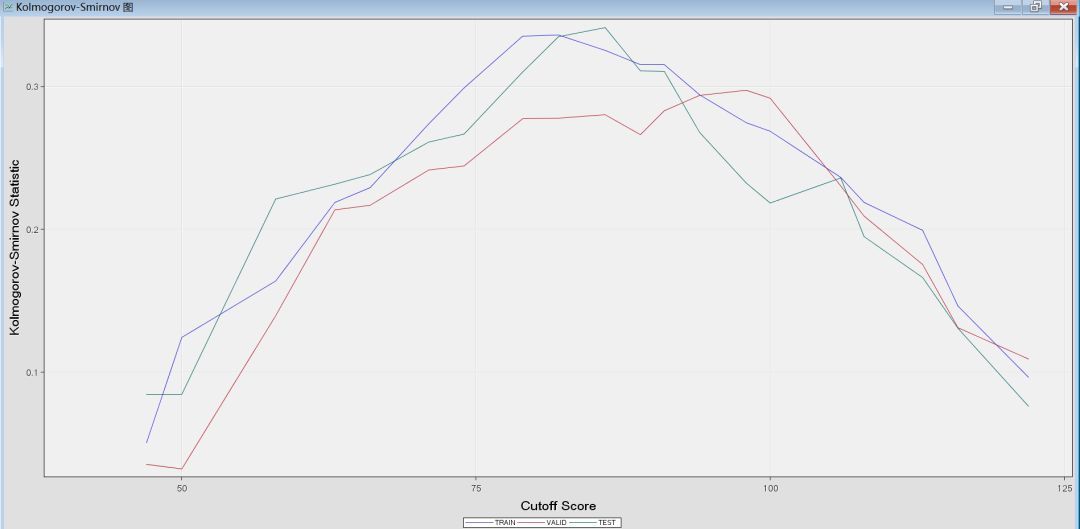
④ROC图和AUC值(ROC曲线描述了在一定累计好客户比例下的累计坏客户的比例,模型的分类能力越强,ROC曲线越往左上角靠近。AUC系数表示ROC曲线下方的面积。模型的风险区分能力越强。)
| KS值 | 解释能力 |
| <0.20 | 无 |
| 0.21-0.40 | 低 |
| 0.41-0.50 | 中 |
| 0.51-0.60 | 高 |
| 0.61-0.75 | 极高 |
| >0.9 | 太高,可能有问题 |



AUR值约为0.71,信用评分卡行业的最优时间建议AUC统计量≥0.75时,建立的行为评分卡是可靠的。如果模型是用于建立申请评分卡,AUC统计量的值较低也可以接受。
⑤稳定度指标PSI
衡量测试样本及模型开发样本评分的分布差异, PSI表示的就是按分数分档后,针对不同样本,或者不同时间的样本,人数分布是否有变化,就是看各个分数区间内人数占总人数的占比是否有显著变化。
| PSO | 模型稳定度 |
| >25% | 低 |
| 10%-25% | 中 |
| <10% | 高 |
将Logistic回归模型转换为标准的信用卡评分格式。若对评分卡的分值和结果不满意,可以对评分卡点数、评分范围、及评分卡设置进行调整。评分卡刻度:
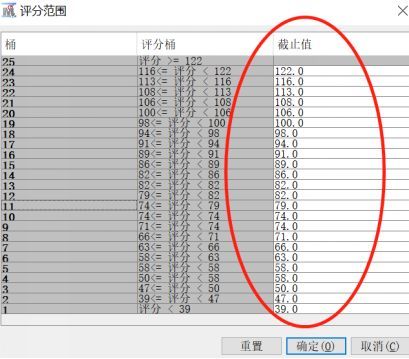

分值分配:
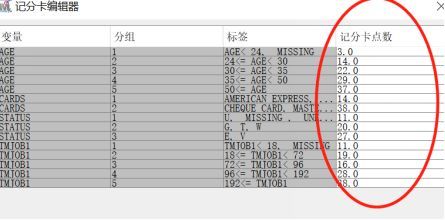

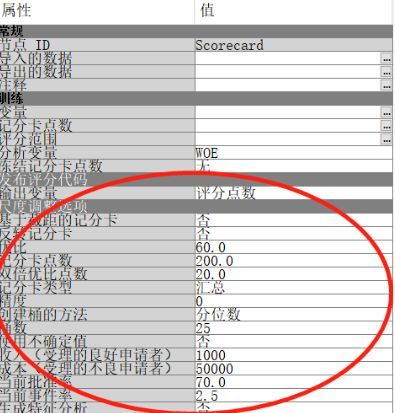

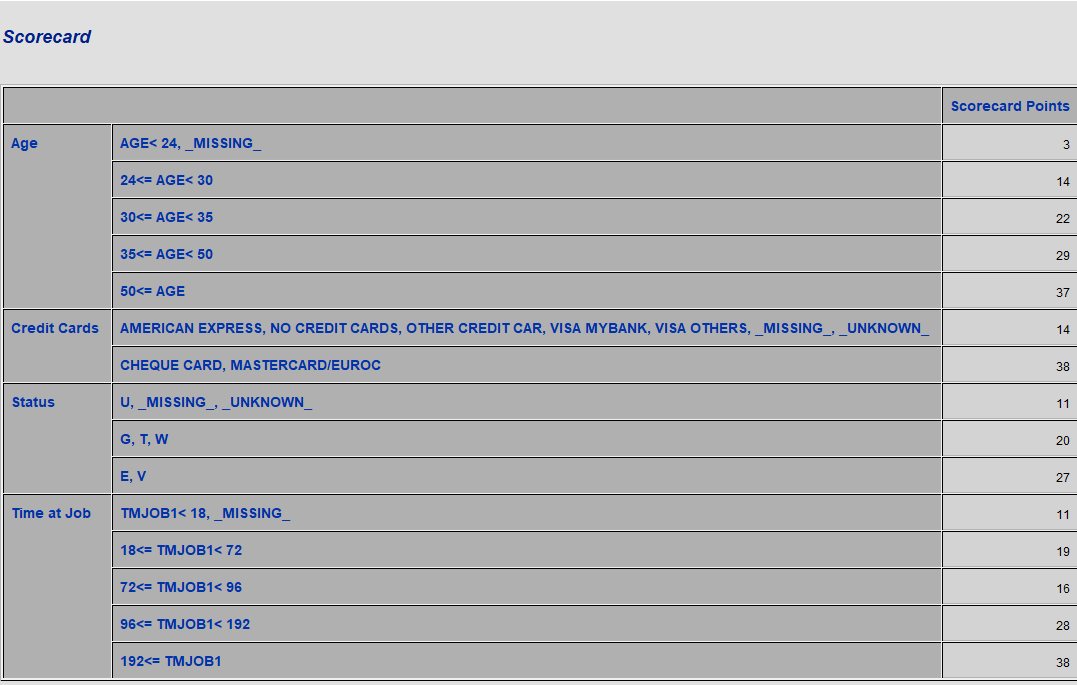
得到的评分卡如下:

3拒绝推断
输入被拒绝数据集,设置推断方法。
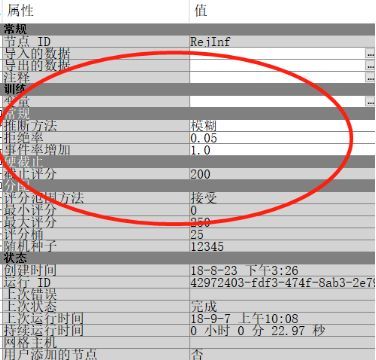

☞
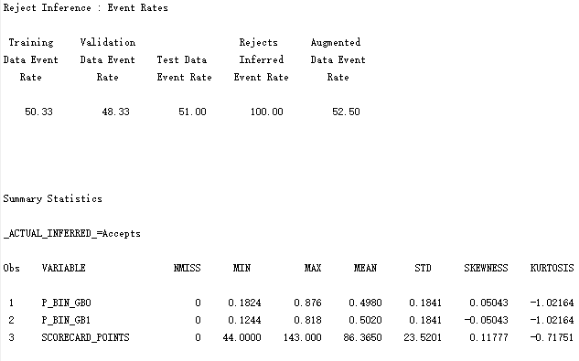

在申请评分卡的情况下,模型开发使用的数据仅仅是对过去已经被接受的账户中选择的。因此,将模型结果应用于全部总体隐含着对被拒绝账户的忽视。进而,建立评分卡时将拒绝账户的状态进行演绎并将其纳入评分卡开发数据集。拒绝演绎方法有简单赋值法、模糊强化法、分配法。
一般在做完拒绝演绎后重新建立评分卡流程,以便让评分卡达到更优的效果。
4信用交换
“信用交换”主要是创建跨记分卡桶的统计量表,用于分析。作为评分卡的门外汉的我就不多说了,展示结果图给大家看看吧。

以上主要介绍了在开发评分卡中的几个关键组件,SAS EM提供的信用评分模块通过几个组件和鼠标的托拉拽方式,让我们快速地完成了评分卡的开发。
曾经阅读过一本《信用评分卡研究》的书,相信做评分卡的朋友都有看过,里面几百页满满的都是sas代码,与之相比,SAS EM的信用评分模块可以让你在短短十来二十分钟里就能开发完成一个信用评分模型,工作效率提高不是同日而语的。
这次分享到此就结束了,虽然在开发评分卡的过程中还有很多细节的地方,不能做到面面俱到,这些就要靠大家在日常工作中和学习业务知识中慢慢积累,也欢迎大家与我互相交流。第一次写SAS的分享文章,如果广受欢迎的话,将向大家分享更多的SAS产品的应用场景。
本文作者:彭碧辉 ,现任广州数驰信息科技有限公司技术总监,负责金融领域数据分析解决方案与实施。在SAS Viya和SAS 9应用平台的架构规划、系统管理、安全性和应用优化与实现等方面有着丰富的知识技术经验。参与过营销平台、SAS网格数据分析平台和申请反欺诈系统的规划和实施。
本文来自SAS数据分析,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://www.sohu.com/a/273953139_649951
注意:本文归作者所有,未经作者允许,不得转载

