Optuna: 一个超参数优化框架
Optuna 是一个特别为机器学习设计的自动超参数优化软件框架。它具有命令式的,define-by-run 风格的 API。由于这种 API 的存在,用 Optuna 编写的代码模块化程度很高,Optuna 的用户因此也可以动态地构造超参数的搜索空间。
主要特点
Optuna 有如下现代化的功能:
基本概念
我们以如下方式使用 study 和 trial 这两个术语:
- Study: 基于目标函数的优化过程
- Trial: 目标函数的单次执行过程
一个优化小例子
import optuna
#待优化函数
def objective(trial):
#suggest_uniform()给定范围均匀选择参数
x = trial.suggest_uniform('x', -10, 10)
return (x - 2) ** 2
#开始优化过程,创建一个study对象,并将目标函数传递给她的一个方法.optimize
study = optuna.create_study()
study.optimize(objective, n_trials=100)
结果:
�[32m[I 2021-06-13 11:03:32,868]�[0m A new study created in memory with name: no-name-92b95d43-a1f4-4520-91af-9ab759adfd93�[0m
···
�[32m[I 2021-06-13 11:03:33,126]�[0m Trial 99 finished with value: 3.0832545651220173 and parameters: {'x': 3.755919862955601}. Best is trial 89 with value: 2.1818699199841563e-05.�[0m
#获取最佳参数
study.best_params
结果:
{'x': 1.9953289509529613}
- 当Optuna被用于机器学习中的超参数搜索时,目标函数通常是对应模型的损失 (loss) 或者准确度 (accuracy).
#获取目标函数值
study.best_value
结果:
2.1818699199841563e-05
#获得最佳 trial:
study.best_trial
结果:
FrozenTrial(number=89, values=[2.1818699199841563e-05], datetime_start=datetime.datetime(2021, 6, 13, 11, 3, 33, 94211), datetime_complete=datetime.datetime(2021, 6, 13, 11, 3, 33, 96606), params={'x': 1.9953289509529613}, distributions={'x': UniformDistribution(high=10.0, low=-10.0)}, user_attrs={}, system_attrs={}, intermediate_values={}, trial_id=89, state=TrialState.COMPLETE, value=None)
#获得所有trials
study.trials
结果:
[FrozenTrial(number=0, values=[8.902710095411337], datetime_start=datetime.datetime(2021, 6, 13, 11, 3, 32, 869319), datetime_complete=datetime.datetime(2021, 6, 13, 11, 3, 32, 871302), params={'x': -0.9837409564858905}, distributions={'x': UniformDistribution(high=10.0, low=-10.0)}, user_attrs={}, system_attrs={}, intermediate_values={}, trial_id=0, state=TrialState.COMPLETE, value=None),
···
FrozenTrial(number=99, values=[3.0832545651220173], datetime_start=datetime.datetime(2021, 6, 13, 11, 3, 33, 124493), datetime_complete=datetime.datetime(2021, 6, 13, 11, 3, 33, 126463), params={'x': 3.755919862955601}, distributions={'x': UniformDistribution(high=10.0, low=-10.0)}, user_attrs={}, system_attrs={}, intermediate_values={}, trial_id=99, state=TrialState.COMPLETE, value=None)]
#获得 trial 的数目:
len(study.trials)
结果:
100
#(在优化结束后)通过再次执行 optimize(),我们可以继续优化过程
study.optimize(objective, n_trials=100)
结果:
�[32m[I 2021-06-13 11:03:33,169]�[0m Trial 100 finished with value: 1.537235278040247 and parameters: {'x': 0.7601470740284366}. Best is trial 89 with value: 2.1818699199841563e-05.�[0m
···
�[32m[I 2021-06-13 11:03:33,486]�[0m Trial 199 finished with value: 1.1332274505781779 and parameters: {'x': 0.9354684360817769}. Best is trial 89 with value: 2.1818699199841563e-05.�[0m
#获得更新(再次优化后)的 trial 数量:
len(study.trials)
结果:
200
基于pytorch的优化实例
在这个实例中,我们使用PyTorch和FashionMNIST优化手写数字识别验证集准确率,我们优化神经网络结构同样也配置优化器,使用FishionMNIST数据集太费时间,我们使用子数据集。
导入需要的包
import os
import optuna
from optuna.trial import TrialState
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
from torchvision import datasets
from torchvision import transforms
设置参数
DEVICE = torch.device("cpu")
BATCHSIZE = 128
CLASSES = 10 #10分类
DIR = os.getcwd()#'/Users/zhou/code/optuna'
EPOCHS = 10
LOG_INTERVAL = 10
N_TRAIN_EXAMPLES = BATCHSIZE * 30 #128*30
N_VALID_EXAMPLES = BATCHSIZE * 10 #128*10
定义模型并选择参数范围
def define_model(trial):
# We optimize the number of layers, hidden units and dropout ratio in each layer.
# 我们优化layers层数量、每一层的隐藏单元和dropout率
n_layers = trial.suggest_int("n_layers", 1, 3) #设置层数为1-3
layers = []
in_features = 28 * 28
for i in range(n_layers):
out_features = trial.suggest_int("n_units_l{}".format(i), 4, 128)#隐藏单元4-128
layers.append(nn.Linear(in_features, out_features))
layers.append(nn.ReLU())
# dropout_ratio越大舍弃的信息越多,loss下降的越慢,准确率增加的越慢
p = trial.suggest_float("dropout_l{}".format(i), 0.2, 0.5)#dropout_ratio从0.2-0.5
layers.append(nn.Dropout(p))
in_features = out_features
layers.append(nn.Linear(in_features, CLASSES))
layers.append(nn.LogSoftmax(dim=1))
return nn.Sequential(*layers)
获取数据集
def get_mnist():
# Load FashionMNIST dataset.
train_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST(DIR, train=True, download=True, transform=transforms.ToTensor()),
batch_size=BATCHSIZE,
shuffle=True,
)
valid_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST(DIR, train=False, transform=transforms.ToTensor()),
batch_size=BATCHSIZE,
shuffle=True,
)
return train_loader, valid_loader
优化器
def objective(trial):
# Generate the model.
model = define_model(trial).to(DEVICE)
# Generate the optimizers.
#生成优化器
optimizer_name = trial.suggest_categorical("optimizer", ["Adam", "RMSprop", "SGD"])
#设置学习率 1e-5到1e-1
lr = trial.suggest_float("lr", 1e-5, 1e-1, log=True)
optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr)
# Get the FashionMNIST dataset.
train_loader, valid_loader = get_mnist()
# Training of the model.
for epoch in range(EPOCHS):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# Limiting training data for faster epochs.
if batch_idx * BATCHSIZE >= N_TRAIN_EXAMPLES:#batch_idx*128>30*128
break
data, target = data.view(data.size(0), -1).to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()#清空过往梯度,设为0
output = model(data)
loss = F.nll_loss(output, target)#计算损失
loss.backward()#反向传播,计算当前梯度
optimizer.step()#根据梯度更新网络参数
# 评估模型
model.eval()
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(valid_loader):
# Limiting validation data.
if batch_idx * BATCHSIZE >= N_VALID_EXAMPLES: #batch_idx*128>=30*128
break
data, target = data.view(data.size(0), -1).to(DEVICE), target.to(DEVICE)
output = model(data)
# Get the index of the max log-probability.
#获得最大log概率的索引
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
accuracy = correct / min(len(valid_loader.dataset), N_VALID_EXAMPLES)
trial.report(accuracy, epoch)
# Handle pruning based on the intermediate value.
#根据中间值处理修剪
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy
if __name__ == "__main__":
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100, timeout=600)
pruned_trials = study.get_trials(deepcopy=False, states=[TrialState.PRUNED])
complete_trials = study.get_trials(deepcopy=False, states=[TrialState.COMPLETE])
print("Study statistics: ")
print(" Number of finished trials: ", len(study.trials))
print(" Number of pruned trials: ", len(pruned_trials))
print(" Number of complete trials: ", len(complete_trials))
print("Best trial:")
trial = study.best_trial
print(" Value: ", trial.value)
print(" Params: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
�[32m[I 2021-06-13 11:03:34,345]�[0m A new study created in memory with name: no-name-710ccb27-9c8c-4aff-8ec5-bdecee1b6c9e�[0m
�···
�[32m[I 2021-06-13 11:05:22,702]�[0m Trial 98 pruned. �[0m
�[32m[I 2021-06-13 11:05:23,009]�[0m Trial 99 pruned. �[0m
Study statistics:
Number of finished trials: 100
Number of pruned trials: 75
Number of complete trials: 25
Best trial:
Value: 0.84453125
Params:
n_layers: 2
n_units_l0: 122
dropout_l0: 0.27085269973254716
n_units_l1: 110
dropout_l1: 0.4061131541476391
optimizer: Adam
lr: 0.008711744845419098
可视化高维参数关系
import optuna
# 这个冗长的更改只是为了简化笔记本的输出
optuna.logging.set_verbosity(optuna.logging.WARNING) # This verbosity change is just to simplify the notebook output.
study = optuna.create_study(direction='maximize', pruner=optuna.pruners.MedianPruner())
study.optimize(objective, n_trials=100)
等高线图
- 在 study.optimize 执行结束以后,通过调用optuna.visualization.plot_contour,并将 study 和需要可视化的参数传入该方法,Optuna 将返回一张等高线图。
- 如果不指定 params 也是可以的,optuna 将画出所有的参数之间的关系,在这里两者等价。
optuna.visualization.plot_contour(study)


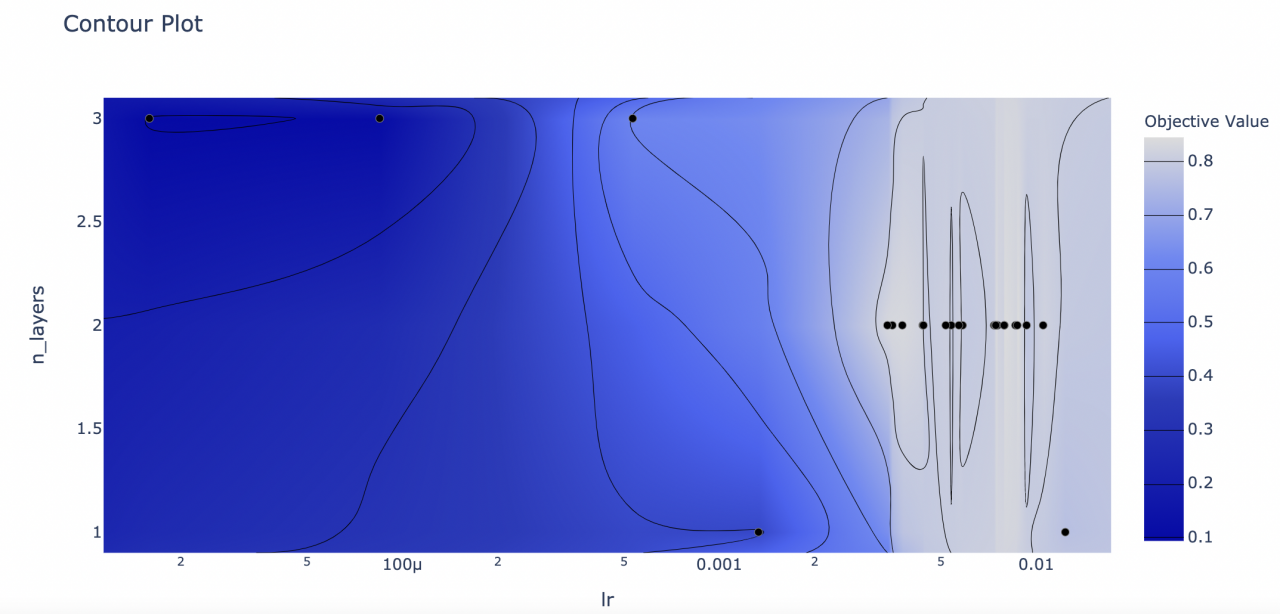
- 例如,当在上面的例子中,我们想要查看参数 n_layer 和 lr 的关系以及它们对于函数值贡献的话,只需要执行下面的语句即可:
选择可视化参数
optuna.visualization.plot_contour(study, params=['n_layers', 'lr'])

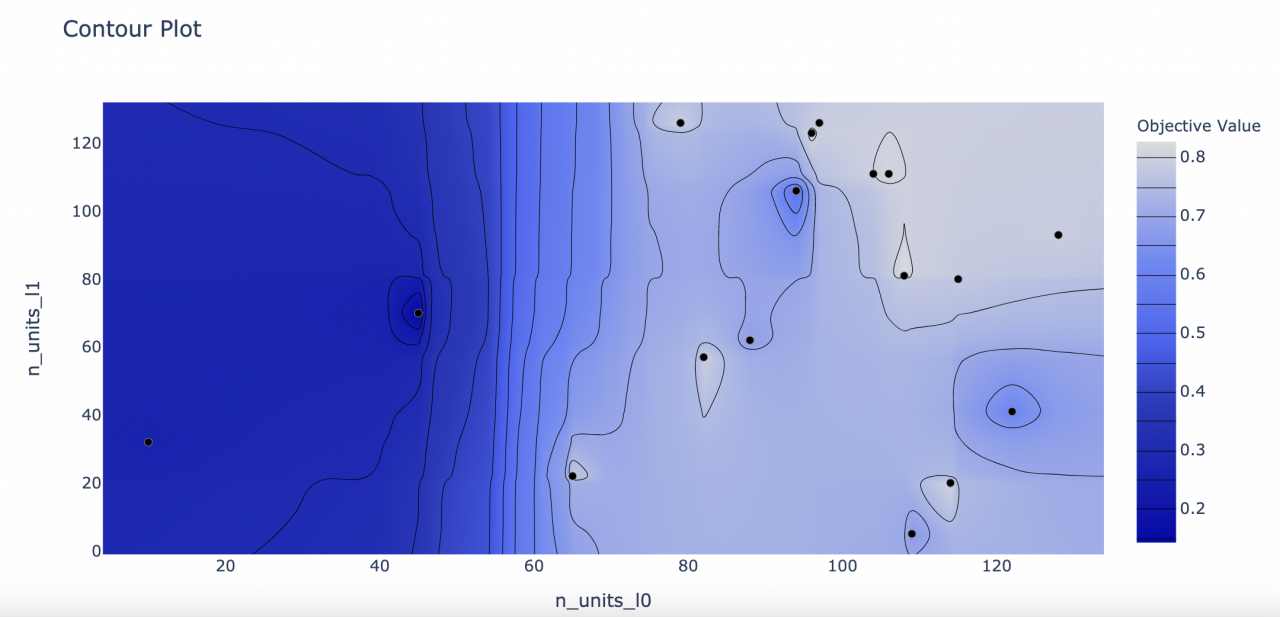
plot_contour(study, params=['n_units_l0', 'n_units_l1'])

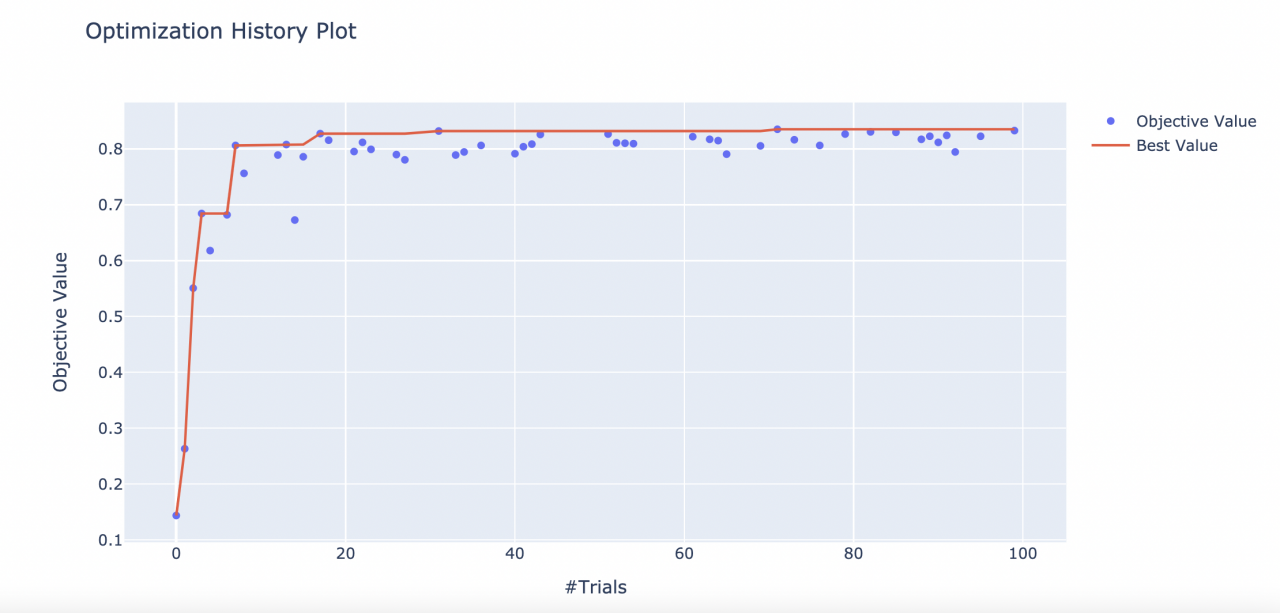
可视化优化历史
from optuna.visualization import plot_optimization_history
plot_optimization_history(study)

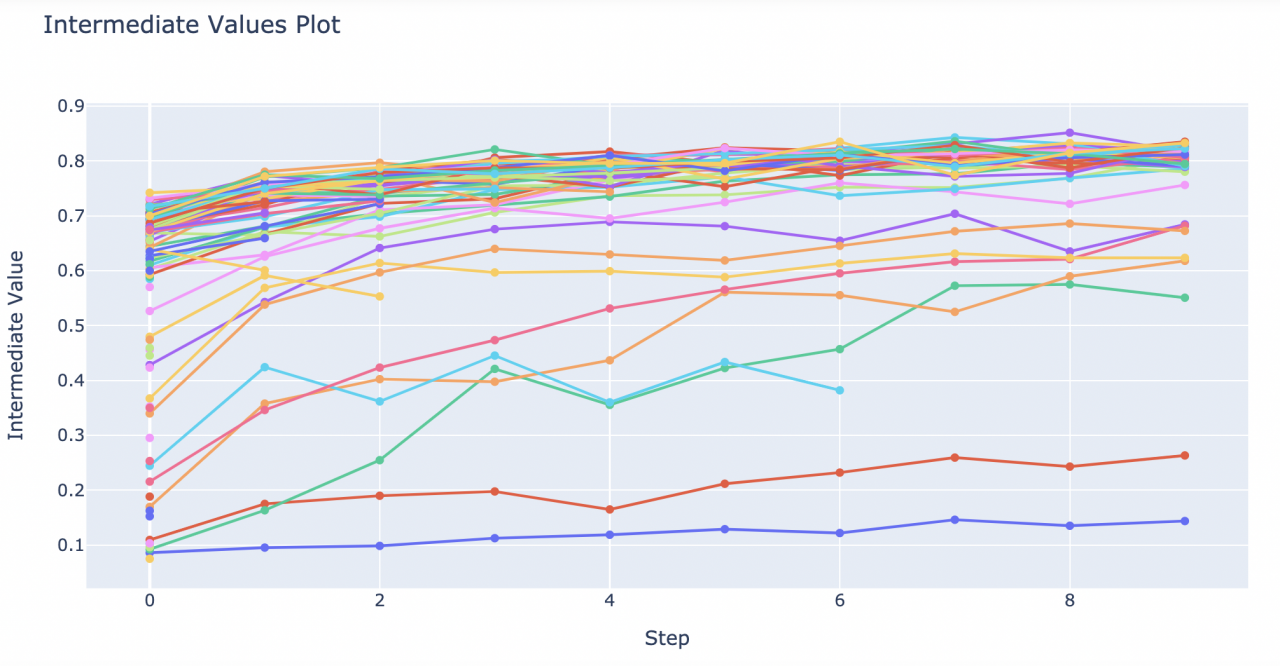
可视化Trials的学习曲线
from optuna.visualization import plot_intermediate_values
plot_intermediate_values(study)

可视化高维度参数的关系
from optuna.visualization import plot_parallel_coordinate
plot_parallel_coordinate(study)
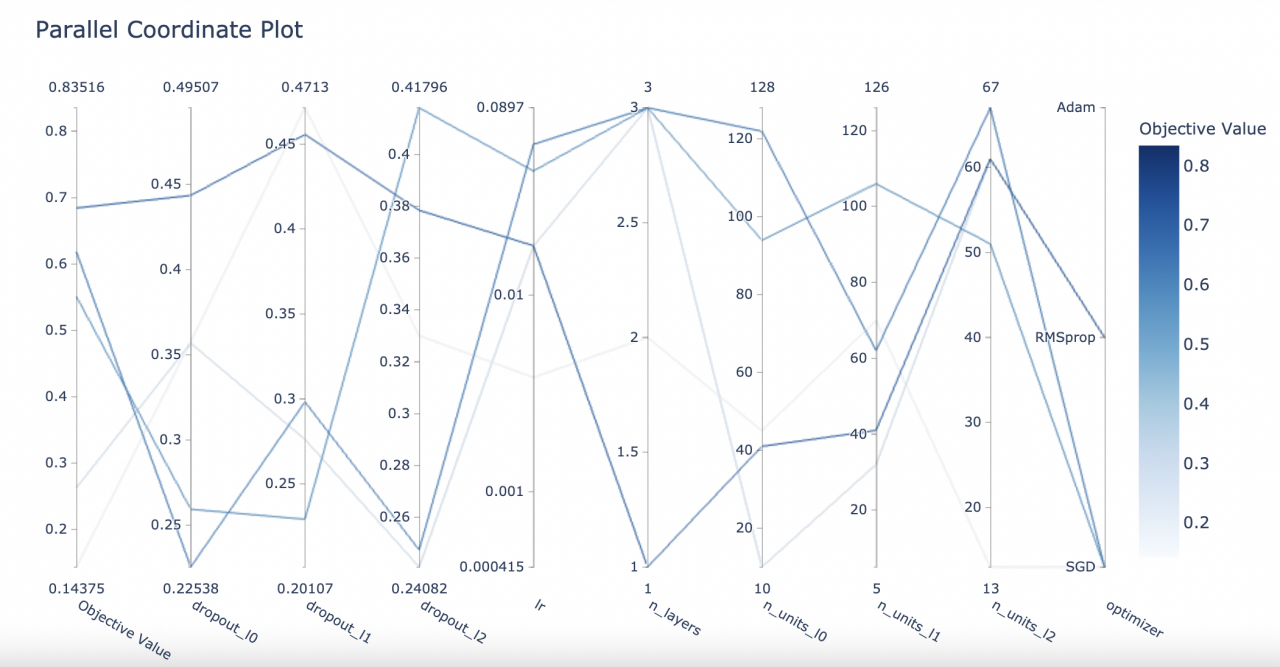

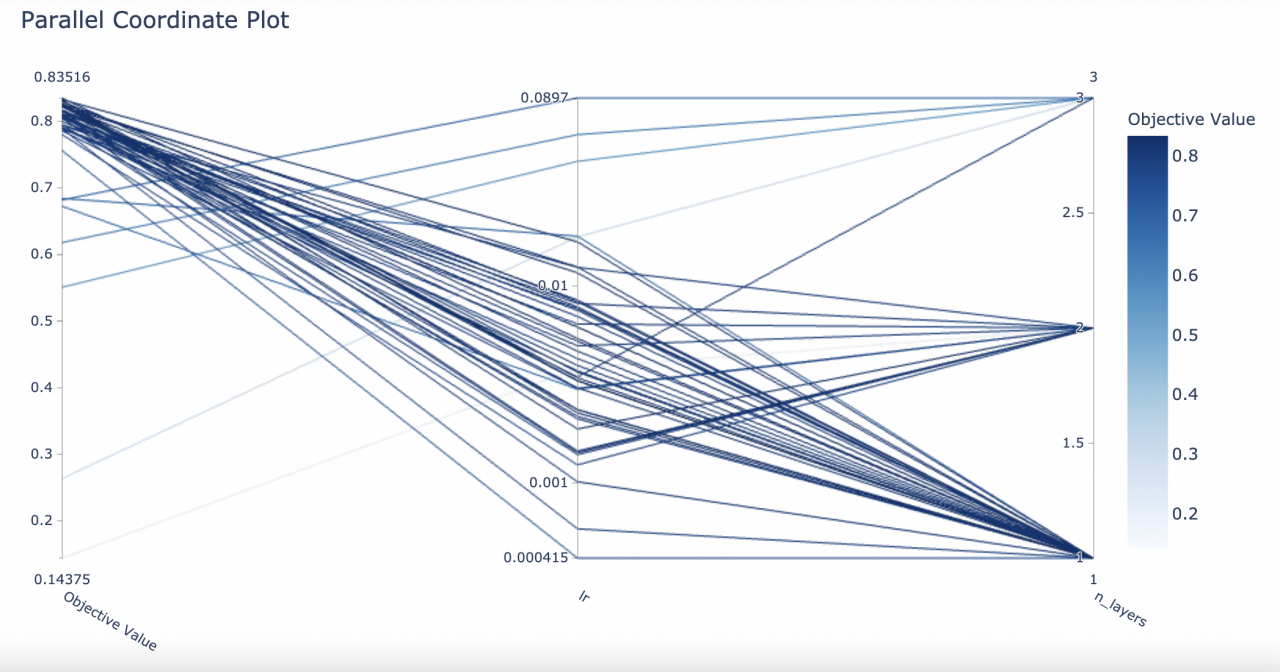
选择参数可视化
plot_parallel_coordinate(study, params=['lr', 'n_layers'])

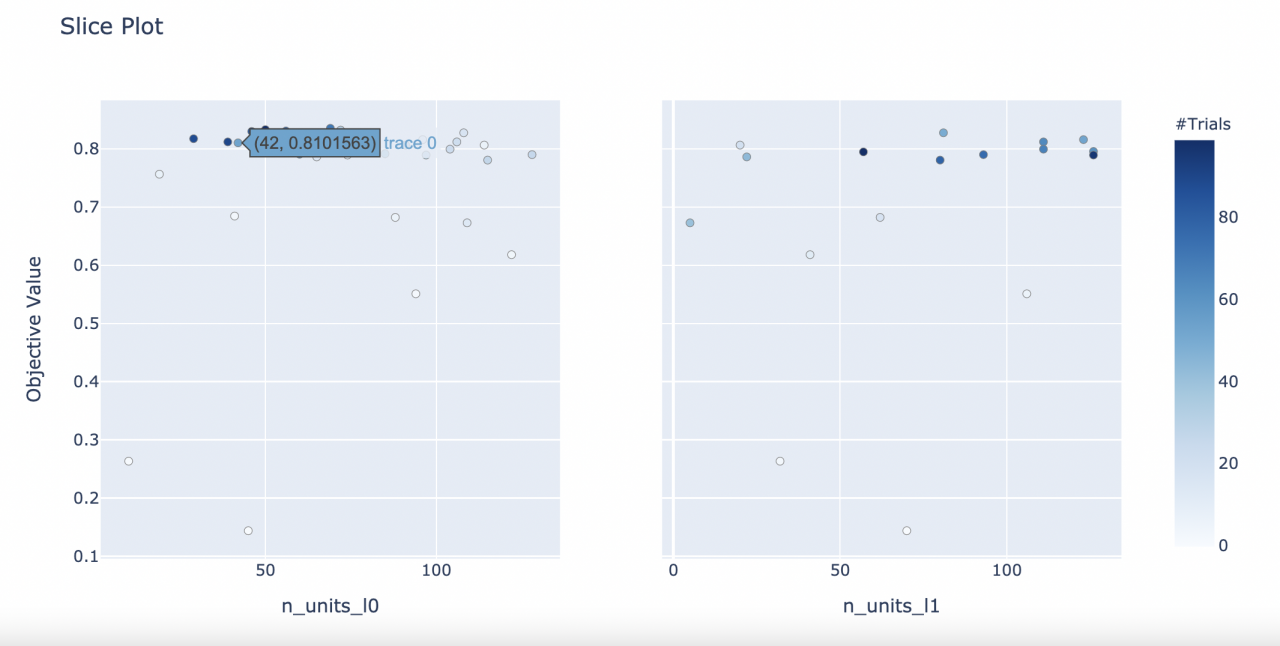
可视化独立参数
from optuna.visualization import plot_slice
plot_slice(study)


选择参数可视化
plot_slice(study, params=['n_units_l0', 'n_units_l1'])

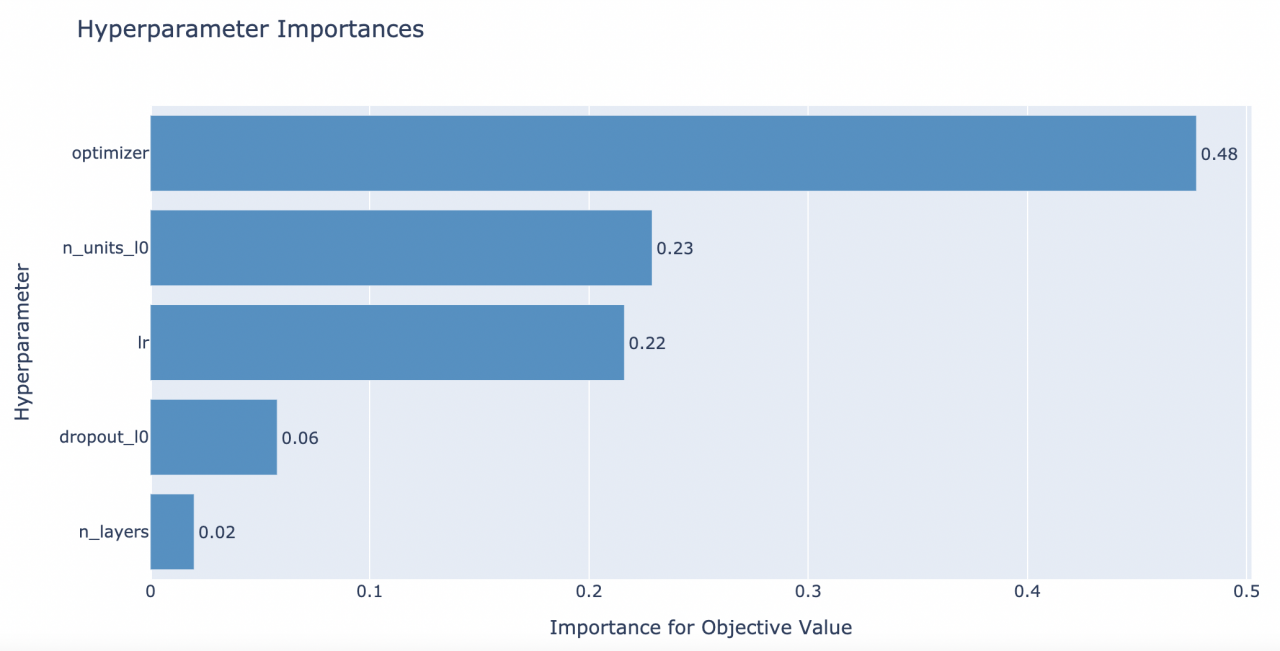
可视化参数的重要性
from optuna.visualization import plot_param_importances
plot_param_importances(study)

本文来自简书,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://www.jianshu.com/p/437084b8b18e
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

