#以存在3个兼并备选企业的情形为例进行讨论。
#根据我国企业兼并现状和发展趋势的发展,企业兼并备选目标的评价包括以下六个方面:
#财务经济状况F1产品市场状况F2发展环境F3
#技术进步潜力F4 组织管理状况F5 工艺-技术相关性F6
require(pmr)
zp <- c(1,3,7,5,1,1,
1/3,1,9,1,1,1,
1/7,1/9,1,1/7,1/5,1/4,
1/5,1,7,1,1/4,1/3,
1,1,5,4,1,3,
1,1,4,3,1/3,1)
m <- matrix(data = zp, nrow = 6, ncol = 6, byrow = TRUE)
zp <- c(1,9,3,
1/9,1,1/5,
1/3,5,1)
f1 <- matrix(data = zp, nrow = 3, ncol = 3, byrow = TRUE)
zp <- c(1,7,4,
1/7,1,1/3,
1/4,3,1)
f2 <- matrix(data = zp, nrow = 3, ncol = 3, byrow = TRUE)
zp <- c( 1,9,3,
1/9,1,1/5,
1/3,5,1)
f3 <- matrix(data = zp, nrow = 3, ncol = 3, byrow = TRUE)
zp <- c(1,6,3,
1/6,1,1/2,
1/3,2,1)
f4 <- matrix(data = zp, nrow = 3, ncol = 3, byrow = TRUE)
zp <- c(1,1/9,1/5,
9,1,4,
5,1/4,1)
f5 <- matrix(data = zp, nrow = 3, ncol = 3, byrow = TRUE)
zp <- c(1,1/7,1/3,
7,1,3,
3,1/3,1)
f6 <- matrix(data = zp, nrow = 3, ncol = 3, byrow = TRUE)
m1 <- ahp(m)$weighting
m2 <- rbind(ahp(f1)$weighting,ahp(f2)$weighting,ahp(f3)$weighting,ahp(f4)$weighting,
ahp(f5)$weighting,ahp(f6)$weighting)
m1%*%m2
结果:0.4182073 0.3418864 0.2399064
接下来的内容来自百度百科,很详细。
层次分析法(Analytic Hierarchy Process,简称AHP)是将与决策总是有关的元素分解成目标、准则、方案等层次,在此基础之上进行定性和定量分析的决策方法。该方法是美国运筹学家匹茨堡大学教授萨蒂于20世纪70年代初,在为美国国防部研究”根据各个工业部门对国家福利的贡献大小而进行电力分配”课题时,应用网络系统理论和多目标综合评价方法,提出的一种层次权重决策分析方法。
目录
1 应用实例
2 定义
3 优缺点
- 优点
- 缺点
4 基本步骤
5 注意事项
1、建立递阶层次结构;
对各指标之间进行两两对比之后,然后按9分位比率排定各评价指标的相对优劣顺序,依次构造出评价指标的判断矩阵A。
3、针对某一个标准,计算各备选元素的权重;
关于判断矩阵权重计算的方法有两种,即几何平均法(根法)和规范列平均法(和法)。
(1)几何平均法(根法)
计算矩阵A各行各个元素的乘积,得到一个n行一列的矩阵B;
计算矩阵每个元素的n次方根得到矩阵C;
对矩阵C进行归一化处理得到矩阵D;
该矩阵D即为所求权重向量。
(2)规范列平均法(和法)
矩阵A每一列归一化得到矩阵B;
将矩阵B每一行元素的平均值得到一个一列n行的矩阵C;
矩阵C即为所求权重向量。
定义
所谓层次分析法,是指将一个复杂的多目标决策问题作为一个系统,将目标分解为多个目标或准则,进而分解为多指标(或准则、约束)的若干层次,通过定性指标模糊量化方法算出层次单排序(权数)和总排序,以作为目标(多指标)、多方案优化决策的系统方法。
层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后得用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递阶归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。这里所谓“优先权重”是一种相对的量度,它表明各备择方案在某一特点的评价准则或子目标,标下优越程度的相对量度,以及各子目标对上一层目标而言重要程度的相对量度。层次分析法比较适合于具有分层交错评价指标的目标系统,而且目标值又难于定量描述的决策问题。其用法是构造判断矩阵,求出其最大特征值。及其所对应的特征向量W,归一化后,即为某一层次指标对于上一层次某相关指标的相对重要性权值。
1. 系统性的分析方法
层次分析法把研究对象作为一个系统,按照分解、比较判断、综合的思维方式进行决策,成为继机理分析、统计分析之后发展起来的系统分析的重要工具。系统的思想在于不割断各个因素对结果的影响,而层次分析法中每一层的权重设置最后都会直接或间接影响到结果,而且在每个层次中的每个因素对结果的影响程度都是量化的,非常清晰、明确。这种方法尤其可用于对无结构特性的系统评价以及多目标、多准则、多时期等的系统评价。
2. 简洁实用的决策方法
这种方法既不单纯追求高深数学,又不片面地注重行为、逻辑、推理,而是把定性方法与定量方法有机地结合起来,使复杂的系统分解,能将人们的思维过程数学化、系统化,便于人们接受,且能把多目标、多准则又难以全部量化处理的决策问题化为多层次单目标问题,通过两两比较确定同一层次元素相对上一层次元素的数量关系后,最后进行简单的数学运算。即使是具有中等文化程度的人也可了解层次分析的基本原理和掌握它的基本步骤,计算也经常简便,并且所得结果简单明确,容易为决策者了解和掌握。
3. 所需定量数据信息较少
层次分析法主要是从评价者对评价问题的本质、要素的理解出发,比一般的定量方法更讲求定性的分析和判断。由于层次分析法是一种模拟人们决策过程的思维方式的一种方法,层次分析法把判断各要素的相对重要性的步骤留给了大脑,只保留人脑对要素的印象,化为简单的权重进行计算。这种思想能处理许多用传统的最优化技术无法着手的实际问题。[1]
缺点
1. 不能为决策提供新方案
层次分析法的作用是从备选方案中选择较优者。这个作用正好说明了层次分析法只能从原有方案中进行选取,而不能为决策者提供解决问题的新方案。这样,我们在应用层次分析法的时候,可能就会有这样一个情况,就是我们自身的创造能力不够,造成了我们尽管在我们想出来的众多方案里选了一个最好的出来,但其效果仍然不够企业所做出来的效果好。而对于大部分决策者来说,如果一种分析工具能替我分析出在我已知的方案里的最优者,然后指出已知方案的不足,又或者甚至再提出改进方案的话,这种分析工具才是比较完美的。但显然,层次分析法还没能做到这点。
2. 定量数据较少,定性成分多,不易令人信服
在如今对科学的方法的评价中,一般都认为一门科学需要比较严格的数学论证和完善的定量方法。但现实世界的问题和人脑考虑问题的过程很多时候并不是能简单地用数字来说明一切的。层次分析法是一种带有模拟人脑的决策方式的方法,因此必然带有较多的定性色彩。这样,当一个人应用层次分析法来做决策时,其他人就会说:为什么会是这样?能不能用数学方法来解释?如果不可以的话,你凭什么认为你的这个结果是对的?你说你在这个问题上认识比较深,但我也认为我的认识也比较深,可我和你的意见是不一致的,以我的观点做出来的结果也和你的不一致,这个时候该如何解决?
比如说,对于一件衣服,我认为评价的指标是舒适度、耐用度,这样的指标对于女士们来说,估计是比较难接受的,因为女士们对衣服的评价一般是美观度是最主要的,对耐用度的要求比较低,甚至可以忽略不计,因为一件便宜又好看的衣服,我就穿一次也值了,根本不考虑它是否耐穿我就买了。这样,对于一个我原本分析的‘购买衣服时的选择方法’的题目,充其量也就只是‘男士购买衣服的选择方法’了。也就是说,定性成分较多的时候,可能这个研究最后能解决的问题就比较少了。
对于上述这样一个问题,其实也是有办法解决的。如果说我的评价指标太少了,把美观度加进去,就能解决比较多问题了。指标还不够?我再加嘛!还不够?再加!还不够?!不会吧?你分析一个问题的时候考虑那么多指标,不觉得辛苦吗?大家都知道,对于一个问题,指标太多了,大家反而会更难确定方案了。这就引出了层次分析法的第三个不足之处。
3. 指标过多时数据统计量大,且权重难以确定
当我们希望能解决较普遍的问题时,指标的选取数量很可能也就随之增加。这就像系统结构理论里,我们要分析一般系统的结构,要搞清楚关系环,就要分析到基层次,而要分析到基层次上的相互关系时,我们要确定的关系就非常多了。指标的增加就意味着我们要构造层次更深、数量更多、规模更庞大的判断矩阵。那么我们就需要对许多的指标进行两两比较的工作。由于一般情况下我们对层次分析法的两两比较是用1至9来说明其相对重要性,如果有越来越多的指标,我们对每两个指标之间的重要程度的判断可能就出现困难了,甚至会对层次单排序和总排序的一致性产生影响,使一致性检验不能通过,也就是说,由于客观事物的复杂性或对事物认识的片面性,通过所构造的判断矩阵求出的特征向量(权值)不一定是合理的。不能通过,就需要调整,在指标数量多的时候这是个很痛苦的过程,因为根据人的思维定势,你觉得这个指标应该是比那个重要,那么就比较难调整过来,同时,也不容易发现指标的相对重要性的取值里到底是哪个有问题,哪个没问题。这就可能花了很多时间,仍然是不能通过一致性检验,而更糟糕的是根本不知道哪里出现了问题。也就是说,层次分析法里面没有办法指出我们的判断矩阵里哪个元素出了问题。[1]
4. 特征值和特征向量的精确求法比较复杂
在求判断矩阵的特征值和特征向量时,所用的方法和我们多元统计所用的方法是一样的。在二阶、三阶的时候,我们还比较容易处理,但随着指标的增加,阶数也随之增加,在计算上也变得越来越困难。不过幸运的是这个缺点比较好解决,我们有三种比较常用的近似计算方法。第一种就是和法,第二种是幂法,还有一种常用方法是根法。
基本步骤
构造判断矩阵
层次分析法的一个重要特点就是用两两重要性程度之比的形式表示出两个方案的相应重要性程度等级。如对某一准则,对其下的各方案进行两两对比,并按其重要性程度评定等级。记为第 和第 因素的重要性之比,表3列出Saaty给出的9个重要性等级及其赋值。按两两比较结果构成的矩阵 称作判断矩阵。判断矩阵 具有如下性质:
且 / ( =1,2,… ) 即 为正互反矩阵
表3比例标度表
|
因素 比因素
|
量化值
|
|
同等重要
|
1
|
|
稍微重要
|
3
|
|
较强重要
|
5
|
|
强烈重要
|
7
|
|
极端重要
|
9
|
|
两相邻判断的中间值
|
2,4,6,8
|
计算权重向量
为了从判断矩阵中提炼出有用信息,达到对事物的规律性的认识,为决策提供出科学依据,就需要计算判断矩阵的权重向量。
定义:判断矩阵 ,如对 … ,成立 ,则称 满足一致性,并称 为一致性矩阵。
一致性矩阵A具有下列简单性质:
1、 存在唯一的非零特征值 ,其对应的特征向量归一化后 记为 ,叫做权重向量,且 ;
2、 的列向量之和经规范化后的向量,就是权重向量;
3、 的任一列向量经规范化后的向量,就是权重向量;
4、对 的全部列向量求每一分量的几何平均,再规范化后的向量,就是权重向量。
因此,对于构造出的判断矩阵,就可以求出最大特征值所对应的特征向量,然后归一化后作为权值。根据上述定理中的性质2和性质4即得到判断矩阵满足一致性的条件下求取权值的方法,分别称为和法和根法。而当判断矩阵不满足一致性时,用和法和根法计算权重向量则很不精确。
一致性检验
当判断矩阵的阶数 时,通常难于构造出满足一致性的矩阵来。但判断矩阵偏离一致性条件又应有一个度,为此,必须对判断矩阵是否可接受进行鉴别,这就是一致性检验的内涵。
定理:设 是正互反矩阵 的最大特征值则必有 ,其中等式当且仅当 为一致性矩阵时成立。
应用上面的定理,则可以根据 是否成立来检验矩阵的一致性,如果 比 大得越多,则 的非一致性程度就越严重。因此,定义一致性指标
(1)
CI越小,说明一致性越大。考虑到一致性的偏离可能是由于随机原因造成的,因此在检验判断矩阵是否具有满意的一致性时,还需将CI和平均随机一致性指标RI进行比较,得出检验系数CR,即
(2)
如果CR<0.1 ,则认为该判断矩阵通过一致性检验,否则就不具有满意一致性。
其中,随机一致性指标RI和判断矩阵的阶数有关,一般情况下,矩阵阶数越大,则出现一致性随机偏离的可能性也越大,其对应关系如表4:
表4 平均随机一致性指标RI标准值(不同的标准不同,RI的值也会有微小的差异)
|
矩阵阶数
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
RI
|
0
|
0
|
0.58
|
0.90
|
1.12
|
1.24
|
1.32
|
1.41
|
1.45
|
1.49
|
可见,AHP方法不仅原理简单,而且具有扎实的理论基础,是定量与定性方法相结合的优秀的决策方法,特别是定性因素起主导作用的决策问题。
注意事项
如果所选的要素不合理,其含义混淆不清,或要素间的关系不正确,都会降低AHP法的结果质量,甚至导致AHP法决策失败。
为保证递阶层次结构的合理性,需把握以下原则:
1、分解简化问题时把握主要因素,不漏不多;
2、注意相比较元素之间的强度关系,相差太悬殊的要素不能在同一层次比较。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e5%b1%82%e6%ac%a1%e5%88%86%e6%9e%90%e6%b3%95/
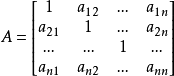



 要素
要素 与要素
与要素 重要性比较结果,并且有如下关系:
重要性比较结果,并且有如下关系:


 有9种取值,分别为1/9, 1/7, 1/5, 1/3, 1/1, 3/1, 5/1, 7/1, 9/1,分别表示
有9种取值,分别为1/9, 1/7, 1/5, 1/3, 1/1, 3/1, 5/1, 7/1, 9/1,分别表示 要素对于
要素对于 要素的重要程度由轻到重。
要素的重要程度由轻到重。
