【案例名称】药物选择决策支持
【案例类型】数据挖掘
【所属行业】医药卫生
【案例版本】1.0
【完成日期】2003年7月2日
【应用软件】Clementine 7.2英文版
【遵循标准】CRISP-DM
【案例数据来源】Clementine 7.2 Demo自带数据
【案例应用模型】神经网络、C5.0、Logistic回归
【案例制作】钟云飞
【案例用途】通过案例实现以下目的:
1、
2、
3、
【案例简要描述】
针对病人的病情和体质情况,医生往往需要采用不同的用药。本案例通过数据挖掘,对医院积累的历史数据进行分析,确定病人选择何种药物对治疗疾病最为有效。并开发了相应的药物选择决策支持系统的应用系统。
案例正文
【背景介绍】
【数据说明】
【数据挖掘过程】
1、
在这个阶段我们主要需要描述清楚业务问题,并对我们手头拥有的资源有一个非常清晰的认识。在这个案例中,我们需要根据病人的个人情况和身体特征来确定何种药物对它最为合适。由于问题比较简单,我们的商业理解也比较简单。
2、
数据理解阶段用来完成对数据质量、数据之间的基本关系进行探索性分析等项工作。在这个阶段,我们对历史数据中的1200条数据进行图形观察,初步观察病人的情况和身体特征是否与选择药物关系明显。数据流图见图1。
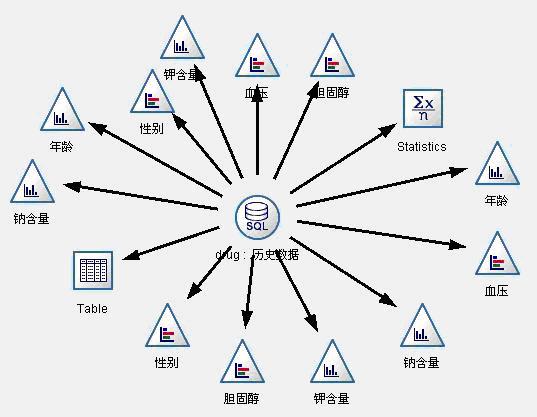
图1:数据理解
下面是产生的一些典型图形,图形解释略。

图2:对数据的初步探索性分析
3、
数据准备主要完成对不同的数据源的整合,并且对数据进行适当的变换,使之适合数据挖掘的需要,对于特定的模型,需要把原始数据集合拆分成训练数据集和检验数据集也在这个步骤中完成。
对于本案例来说,由于数据源只有一个,并且数据格式也相对单一简单,我们在数据准备中主要完成对原始数据集的拆分,从而用训练数据集建立模型,用检验数据集对模型的效果进行评估。
在Clementine中,对数据集的拆分,是通过引入一个中间变量来完成的。在本案例中,我们把全部1200条数据中的2/3左右(800左右)作为训练数据集,把1/3左右(400左右)作为检验数据集。我们引入了一个二分变量——拆分变量,这个二分变量对应1200条原始数据有2/3左右为“真”(T),1/3左右为“假”(F)。我们挑出那些拆分变量值取“真”(T)的记录作为训练数据集,那些拆分变量值取“假”(F)的记录作为检验数据集。实现该过程的数据流见图3。
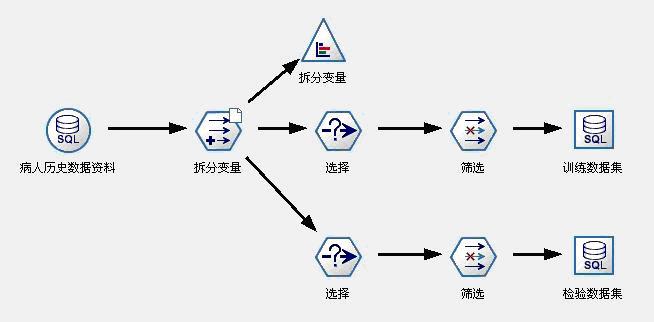
图3:数据准备
4、
在模型建立阶段,我们将逐步建立和调整模型,并对如何提高模型的预测效果进行尝试。
(1)
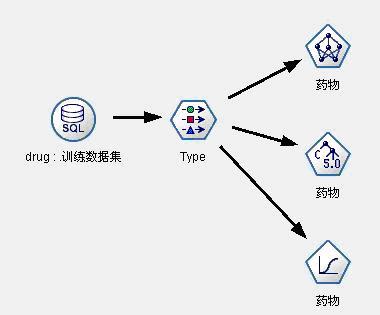
图4:药物选择决策支持模型1
接下来我们用检验数据集对模型进行检验,数据流图见图5。模型检验结果见图6。从检验结果我们可以看出,Logistic模型的评估效果最好,达到了96.21%。
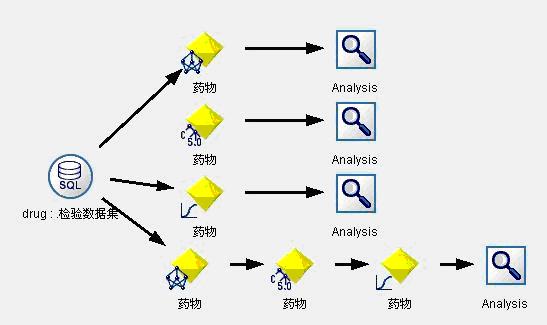
图5:药物选择决策支持模型1检验
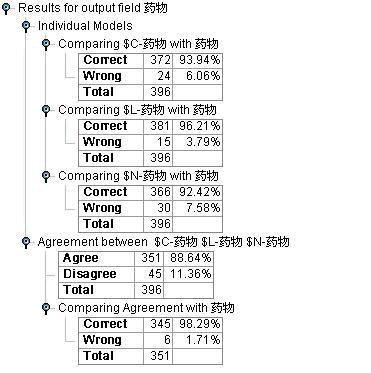
图6:药物选择决策支持模型1检验结果
讨论——如何提高模型的效果:从模型检验中我们可以看出,三个模型中可能有不一致的情况,这就使得我们有一种思路,即我们在发布模型的时候,可以考虑把那些三个模型预测一致的才作为预测,而把三者预测不一致的作为待判记录随后进行深入的分析,这样我们就使得模型的精度提高到了98.29%,但是作为牺牲,我们也会约有12%左右的病人是无法判断的,需要我们对记录做进一步的研究。
(2)
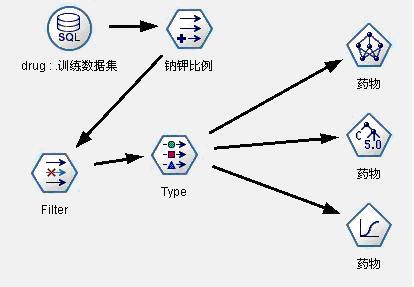
图7:药物选择决策支持模型2
类似(1),我们对模型效果进行检验,检验数据流和检验结果分别如图8和图9所示。
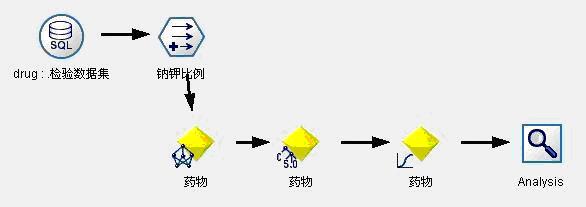
图8:药物选择决策支持模型2检验

图9:药物选择决策支持模型2检验结果
从结果中,我们可以看出,随着我们业务经验的引入,我们的模型效果有了显著的提高,并且我们选择模型也发生了变化。精度由原来的Logistic回归最优96.21%提高到了C5.0最优99.75%。
5、
模型建立是为了应用,我们前面的全部工作都在于我们建立的模型能够被最终的业务人员所使用,假设我们由以下10个病人的资料数据,需要根据他们的情况判断使用什么药物最好。
表1:病人资料
| 年龄 | 性别 | 血压 | 胆固醇 | 钠含量 | 钾含量 |
|
25 |
F | HIGH | HIGH |
0.675996 |
0.074834 |
|
17 |
F | HIGH | HIGH |
0.539756 |
0.030081 |
|
23 |
M | LOW | NORMAL |
0.556453 |
0.03618 |
|
24 |
M | NORMAL | NORMAL |
0.845236 |
0.055498 |
|
74 |
F | LOW | HIGH |
0.849624 |
0.076902 |
|
40 |
F | NORMAL | HIGH |
0.67683 |
0.049634 |
|
32 |
F | HIGH | HIGH |
0.581664 |
0.024803 |
|
70 |
M | LOW | HIGH |
0.716359 |
0.036936 |
|
64 |
M | HIGH | NORMAL |
0.640789 |
0.078302 |
|
45 |
M | HIGH | HIGH |
0.664105 |
0.047819 |
该病人资料也被我们存放在Access数据库中。我们可以考虑以下三种方式对我们的模型进行发布供业务人员(医生)使用。
(1)
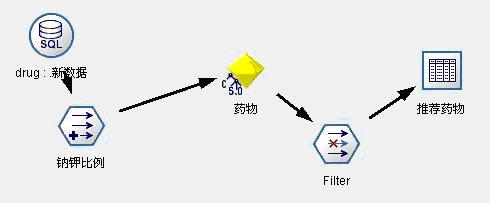
图10:模型发布数据流1
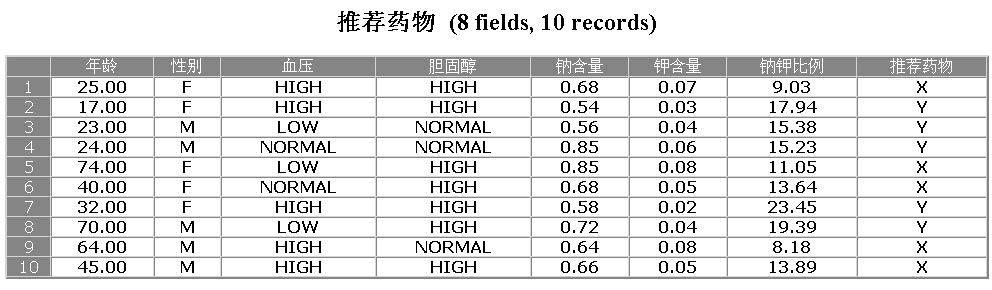
图11:报告方式发布结果示例
(2)

图12:模型发布数据流2

图13:模型发布—把结果写回数据库
(3)

图14:模型发布数据流3
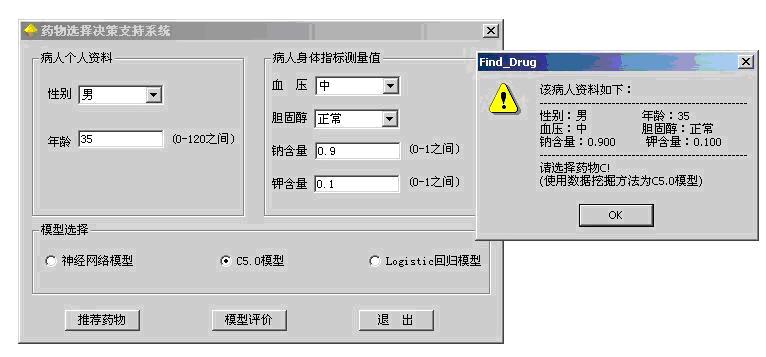
图15:模型发布——开发应用系统
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e6%95%b0%e6%8d%ae%e6%8c%96%e6%8e%98%e6%a1%88%e4%be%8b-%e8%8d%af%e7%89%a9%e9%80%89%e6%8b%a9%e5%86%b3%e7%ad%96%e6%94%af%e6%8c%81/
注意:本文归作者所有,未经作者允许,不得转载

