来自 http://blog.sciencenet.cn/blog-556556-860647.html
使用k-means进行聚类,常常被假定为数据是球状的,似乎是非球状数据就不灵了。
下面构造一个数据,看看非球状数据长什么样子:
library(dplyr)
library(ggplot2)
set.seed(2015)
n <- 250
c1 <- data_frame(x = rnorm(n), y = rnorm(n), cluster = 1)
c2 <- data_frame(r = rnorm(n, 5, .25), theta = runif(n, 0, 2 * pi),
x = r * cos(theta), y = r * sin(theta), cluster = 2) %>%
dplyr::select(x, y, cluster)
points1 <- rbind(c1, c2) %>% mutate(cluster = factor(cluster))
ggplot(points1, aes(x, y)) + geom_point()

图中非常明显地看出圆心应该属于一类,圆周数据应该属于一类,那么使用k-means看看效果:
library(broom)
plot_kmeans <- function(dat, k) {
clust <- dat %>% ungroup %>% dplyr::select(x, y) %>% kmeans(k)
ggplot(augment(clust, dat), aes(x, y)) + geom_point(aes(color = .cluster)) +
geom_point(aes(x1, x2), data = tidy(clust), size = 10, shape = “x”) +
labs(color = “K-means assignments”)
}
plot_kmeans(points1, 2)
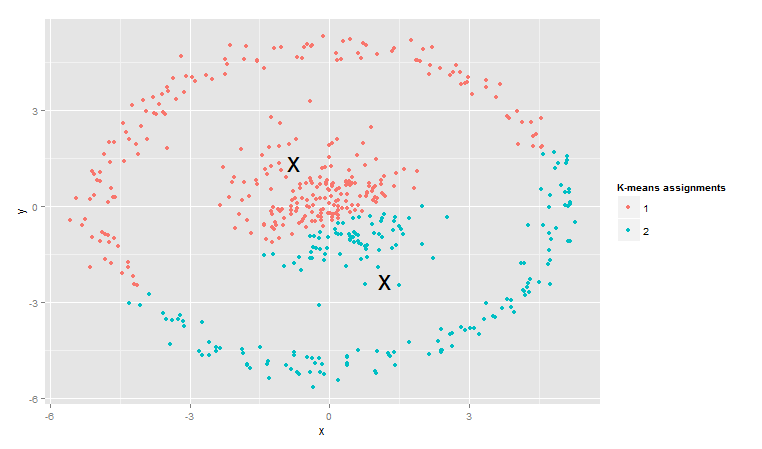
反差太大。如果用层次聚类看看:
points1$hclust_assignments <- points1 %>% dplyr::select(x, y) %>%
dist() %>% hclust(method = “single”) %>%
cutree(2) %>% factor()
ggplot(points1, aes(x, y, color = hclust_assignments)) + geom_point() +
labs(color = “hclust assignments”)
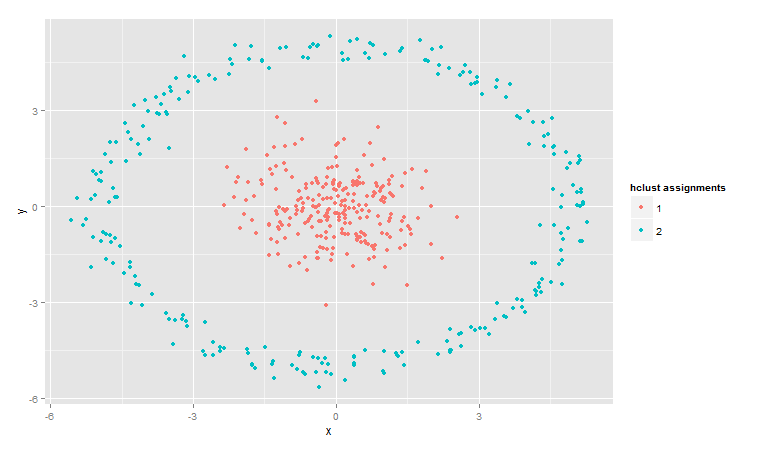
和我们事前预期一致,看样子数据形态对聚类还是有影响的。但如果换一个角度分析这个问题,把园用极坐标处理一下:
points1_polar <- points1 %>% transform(r = sqrt(x^2 + y^2), theta = atan(y / x))
clust <- points1_polar %>% ungroup %>% dplyr::select(r, theta) %>% kmeans(2)
ggplot(augment(clust, points1_polar), aes(r, theta)) + geom_point(aes(color = .cluster)) +
geom_point(aes(x1, x2), data = tidy(clust), size = 10, shape = “x”) +
labs(color = “K-means assignments”)
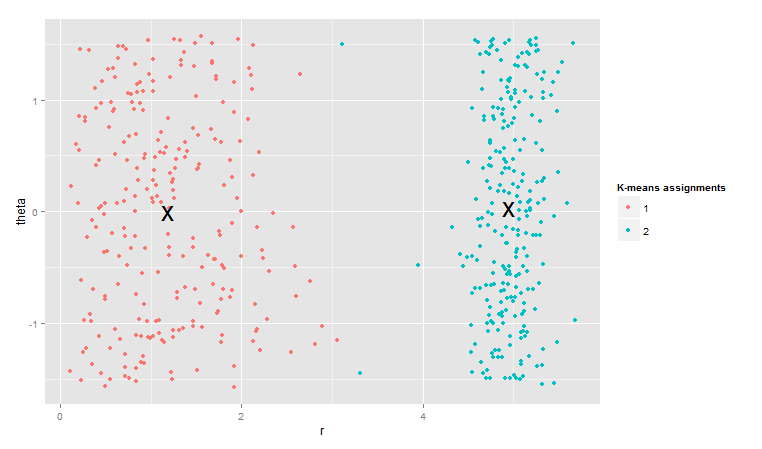
还是可以分得很清楚。
k-means的另一个假设是各个分类的先验概率应该一致,其实这个假设不成立。
把样本分别为20,100,500三个类:
sizes <- c(20, 100, 500)
set.seed(2015)
centers <- data_frame(x = c(1, 4, 6), y = c(5, 0, 6), n = sizes, cluster = factor(1:3))
points <- centers %>% group_by(cluster) %>%
do(data_frame(x = rnorm(.n,.x), y = rnorm(.n,.y)))
ggplot(points, aes(x, y)) + geom_point()
plot_kmeans(points, 3)
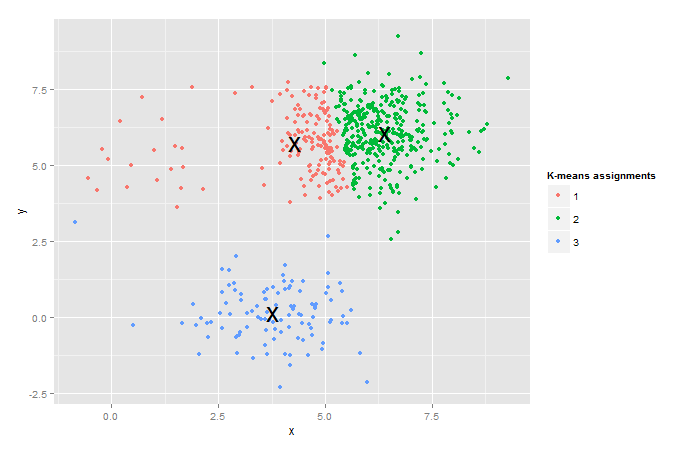
可以看出即使初始样本相差很大,但是还是可以清楚地进行聚类。
因此使用此法进行聚类时要注意实际问题实际分析。
原创文章,作者:xsmile,如若转载,请注明出处:http://www.17bigdata.com/%e5%a4%a7%e6%95%b0%e6%8d%ae%e5%88%86%e6%9e%90%e4%b9%8b-k-means%e8%81%9a%e7%b1%bb%e4%b8%ad%e7%9a%84%e5%9d%91/
注意:本文归作者所有,未经作者允许,不得转载

