作者:Barış KaramanFollow
编译:ronghuaiyang
正文共:8484 字 13 图
预计阅读时间:25 分钟
导读
我们通过客户分群和终生价值的预测得到了我们的最好的客户,对于这部分的客户,我们需要全力的留住他们,那么具体应该怎么做呢。
第四部分: 客户流失预测
在过去的三个部分的数据驱动的增长系列中,我们已经了解了跟踪重要指标,客户细分以及预测终生价值。既然我们通过细分和终生价值预测来了解我们最好的客户,我们也应该努力留住他们。这就是为什么留存率是最重要的指标之一。
留存率是一个指标,你的产品的市场适合度(PMF)有多好。如果你们的PMF不令人满意,你们应该会看到你们的客户很快就会流失。客户流失率预测是提高客户留存率(PMF)的有力工具之一。通过使用这种技术,你可以很容易地找出在给定的时间段内哪些人可能会频繁的流动。在本文中,我们会使用一个Telco数据集,并通过以下步骤来开发一个客户流失预测模型:
- 探索性数据分析
- 特征工程
- 使用Logistic回归研究特征如何影响留存率
- 使用XGBoost建立分类模型
探索性数据分析
我们首先检查数据的大致情况,并将其与标签的交互方式可视化。让我们导入数据,并打印前十行:
df_data = pd.read_csv('churn_data.csv')
df_data.head(10)
输出:

查看所有列及其数据类型的更好方法是使用.info()方法:
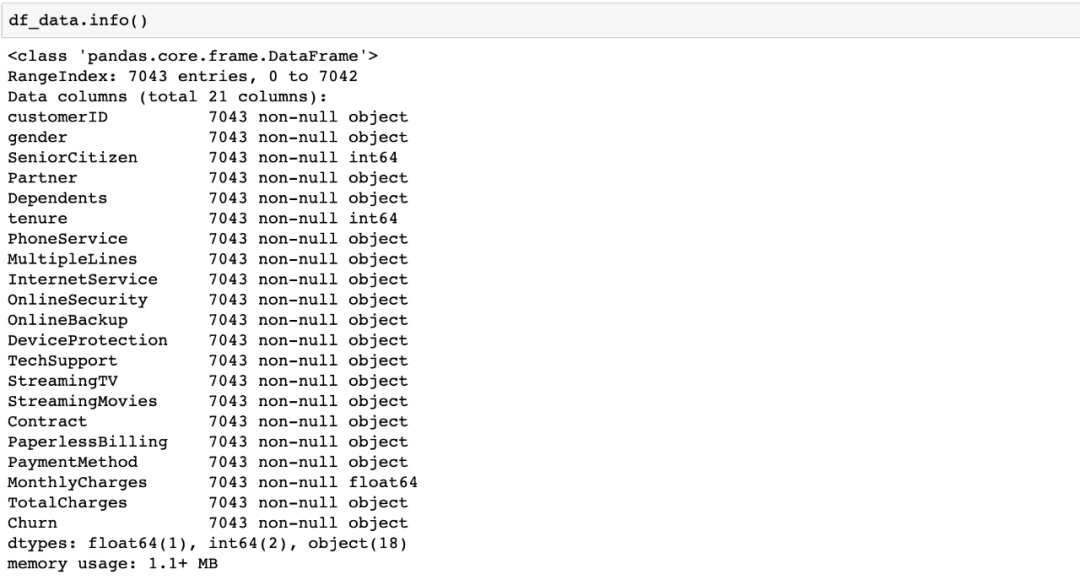

我们的数据似乎可以分为两类:
- 类别特征:gender,streaming tv,payment method等。
- 数值特征:tenure,monthly charges,total charges
现在,从类别特征开始,我们会分析所有的特征,看看它们对识别客户是否会流失有多大的帮助。
另外,在我们的数据集中,Churn(流失)那一列是string类型,值为Yes/No。我们将其转换为integer以便在分析中使用。
df_data.loc[df_data.Churn=='No','Churn'] = 0
df_data.loc[df_data.Churn=='Yes','Churn'] = 1
Gender
通过使用下面的代码,我们可以很容易地看对于每个值,流失率(1 – 留存率)是什么样的:
df_plot = df_data.groupby('gender').Churn.mean().reset_index()
plot_data = [
go.Bar(
x=df_plot['gender'],
y=df_plot['Churn'],
width = [0.5, 0.5],
marker=dict(
color=['green', 'blue'])
)
]plot_layout = go.Layout(
xaxis={"type": "category"},
yaxis={"title": "Churn Rate"},
title='Gender',
plot_bgcolor = 'rgb(243,243,243)',
paper_bgcolor = 'rgb(243,243,243)',
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
输出:
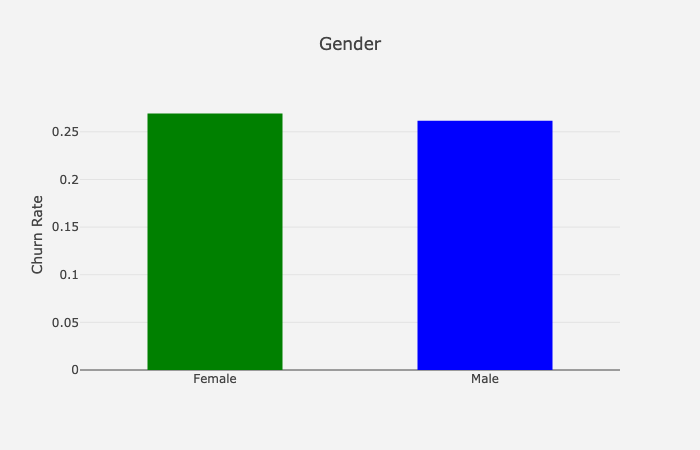

基于性别的流失率
流失率的性别分类:


女性顾客比男性顾客更容易流失,但差别很小(约0.8%)。
我们对其他所有的类别列重复上面的操作。
现在,我们来看看这些表现出最显著的差异的特征:
Internet Service
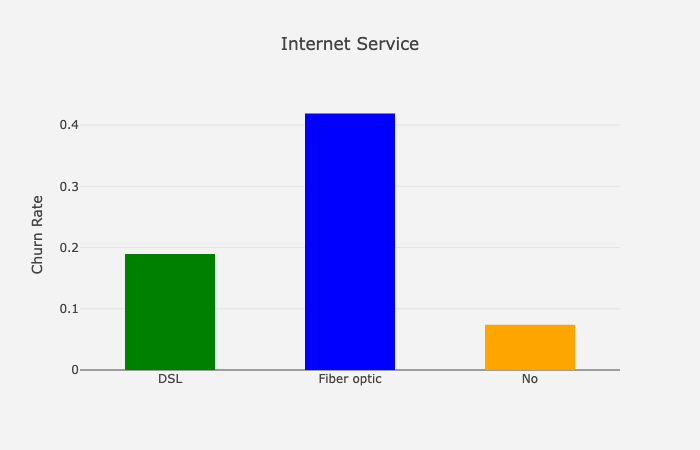

基于网络服务的流失率
这张图表显示,拥有光纤网络服务的客户更有可能流失。我通常希望光纤客户少流失,因为他们使用更优质的服务。但这可能是由于高价格、竞争、客户服务和许多其他原因造成的。
Contract
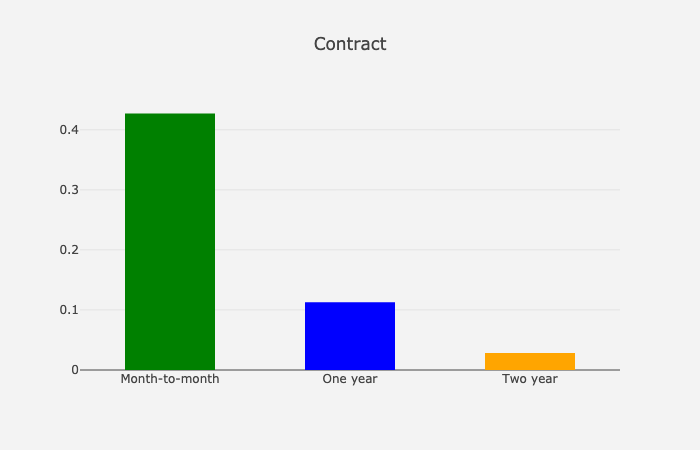

基于合约的流失率
正如预期的那样,更短的合约意味着更高的流失率。
Tech Support
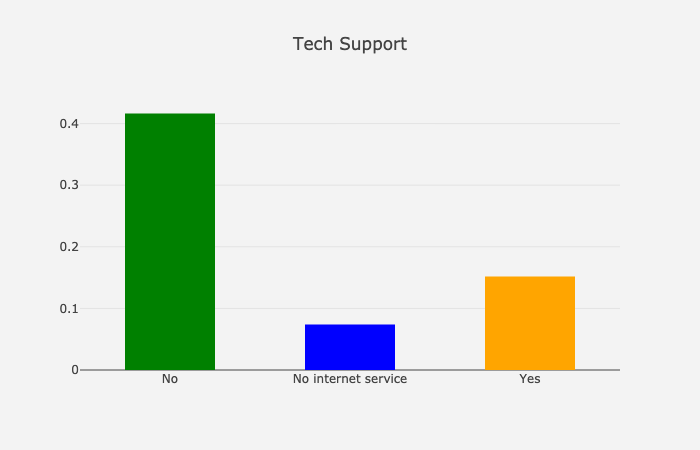

基于技术支持的流失率
不使用技术支持的客户更容易流失(约25%的差异)。
Payment Method
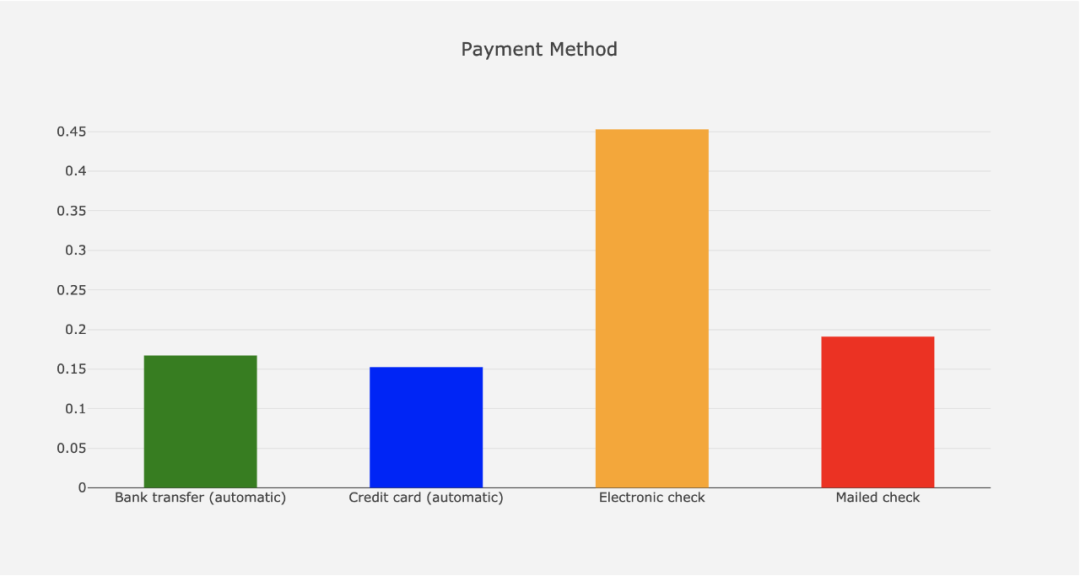

自动支付使客户更有可能留存在你的平台上(~30%的差异)。
Others
让我们在这里展示一些其他特征的图,以供参考:


基于无纸账单,流媒体电影,设备保护和电话服务的流失率
我们已经完成了类别特征的分析,让我们看看数字特征是什么样的:
Tenure
为了看到Tenure和平均流失率之间的趋势,让我们构建一个散点图:
df_plot = df_data.groupby('tenure').Churn.mean().reset_index()plot_data = [
go.Scatter(
x=df_plot['tenure'],
y=df_plot['Churn'],
mode='markers',
name='Low',
marker= dict(size= 7,
line= dict(width=1),
color= 'blue',
opacity= 0.8
),
)
]plot_layout = go.Layout(
yaxis= {'title': "Churn Rate"},
xaxis= {'title': "Tenure"},
title='Tenure based Churn rate',
plot_bgcolor = "rgb(243,243,243)",
paper_bgcolor = "rgb(243,243,243)",
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
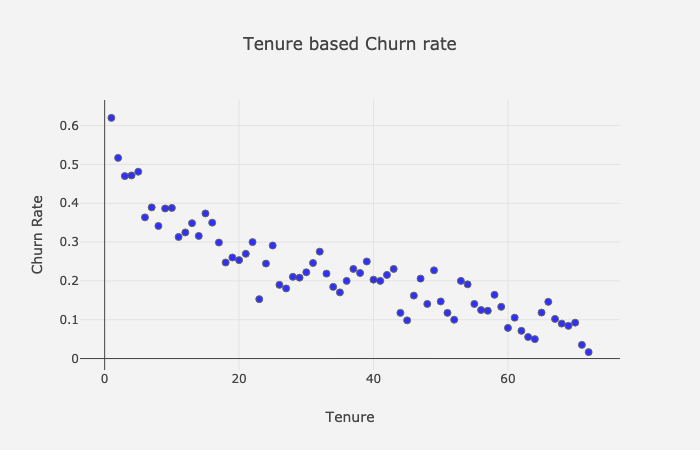

基于Tenure的流失率
很明显,更高的tenure意味着更低的流失率。我们同样用于Monthly和Total Charges:
输出:


基于月度和总费用的流失率
不幸的是,在流失率和月度和总费用之间并没有明显的趋势。
特征工程
在这一节中,我们将对我们的原始特征进行变换,以从中提取更多的信息。我们的策略如下:
- 使用聚类技术对数值列进行分组
- 应用Label Encoder到二值化的分类特征上
- 应用get_dummies()到具有多个值的分类特征上
数值列
从EDA部分我们知道,我们有三个数值列:
- Tenure
- Monthly Charges
- Total Charges
我们将应用以下步骤来创建分组:
- 采用Elbow法确定合适的簇数量
- 对所选列使用K-means并更改命名
- 观察簇的外形
让我们来看看这在实践中对于Tenure是如何操作的:
簇属性:


我们有三个分组,平均Tenure分别为7.5、33.9和63。
每个分组的流失率:


基于tenure分组的流失率
对Monthly和Total Charges使用同样的操作:
Monthly Charge:
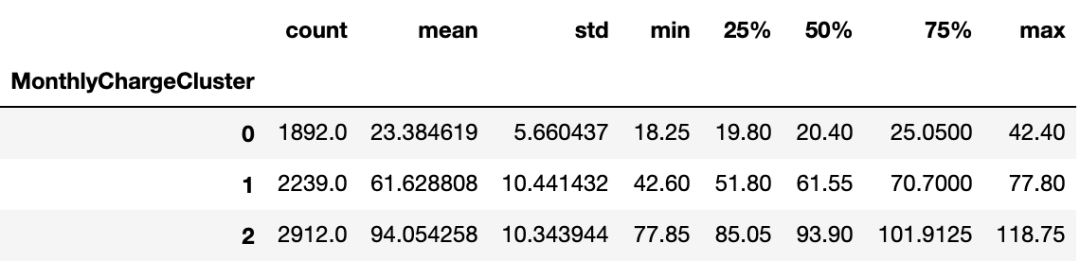

月费用分组属性
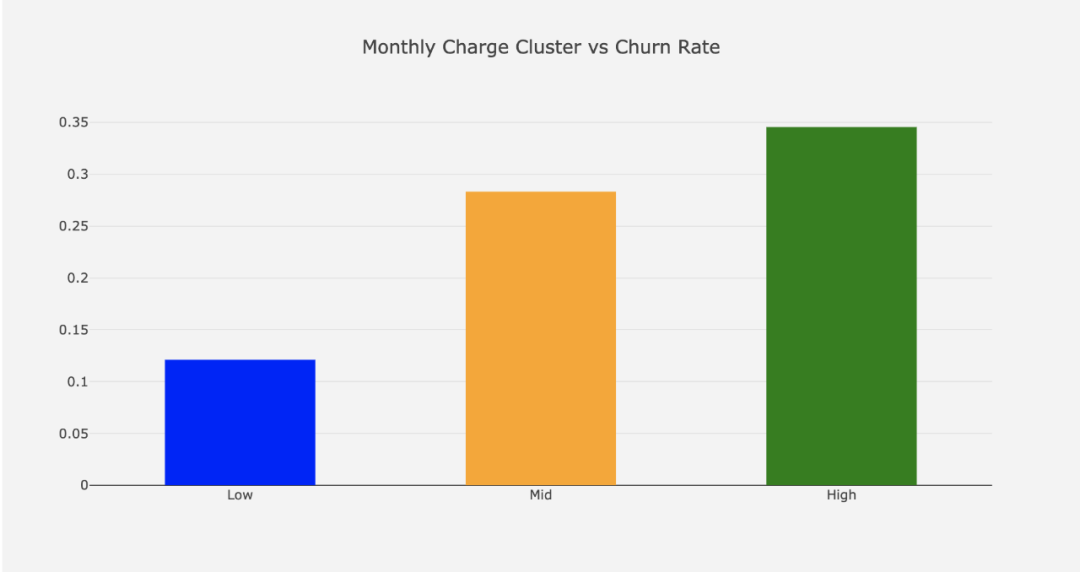

基于月费用分组的流失率
总费用:
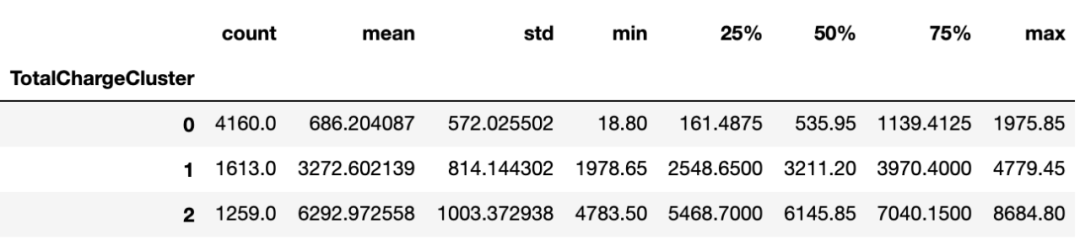

总费用分组属性
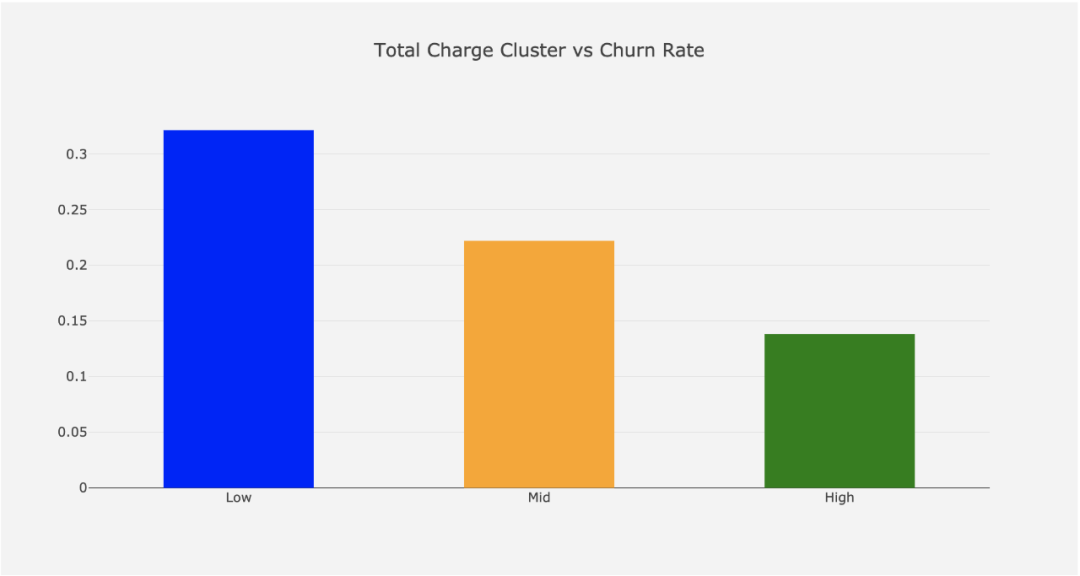

基于总费用分组的流失率
类别列
Label Encoder通过简单将不同的值赋值成一个整数,将类别列转换为数值。例如,列gender有两个值:Female & Male。Label Encoder将它转换成1和0。
get_dummies()方法就是one-hot编码。
让我们在实践中看看:
#import Label Encoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
dummy_columns = [] #array for multiple value columnsfor column in df_data.columns:
if df_data[column].dtype == object and column != 'customerID':
if df_data[column].nunique() == 2:
#apply Label Encoder for binary ones
df_data[column] = le.fit_transform(df_data[column])
else:
dummy_columns.append(column)#apply get dummies for selected columns
df_data = pd.get_dummies(data = df_data,columns = dummy_columns)
对于选定的列,看看数据是什么样的:
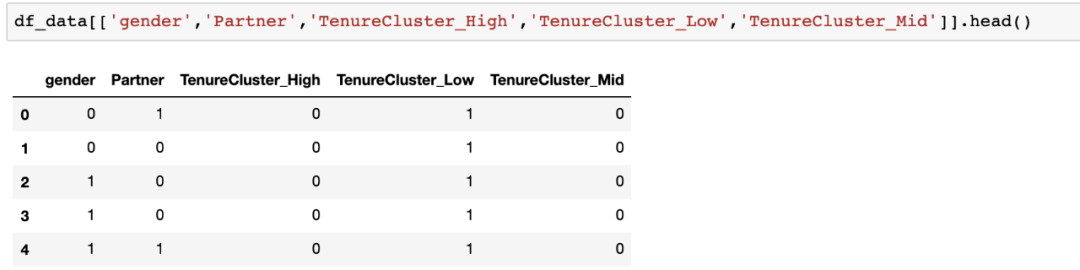

你可以很容易地看到,gender & Partner列变成了数值列,我们为TenureCluster增加了三个新列。
现在是可以拟合逻辑回归模型并提取洞察力以做出更好的业务决策了。
逻辑回归
预测客户流失是一个二分类问题。客户在一段时间内不是流失就是留存。作为一个健壮的模型,逻辑回归也提供了可解释的结果。正如我们之前所做的,我们要整理出一个要遵循的步骤来建立一个逻辑回归模型:
- 准备数据(模型的输入)
- 拟合模型并查看模型摘要
摘要如下:
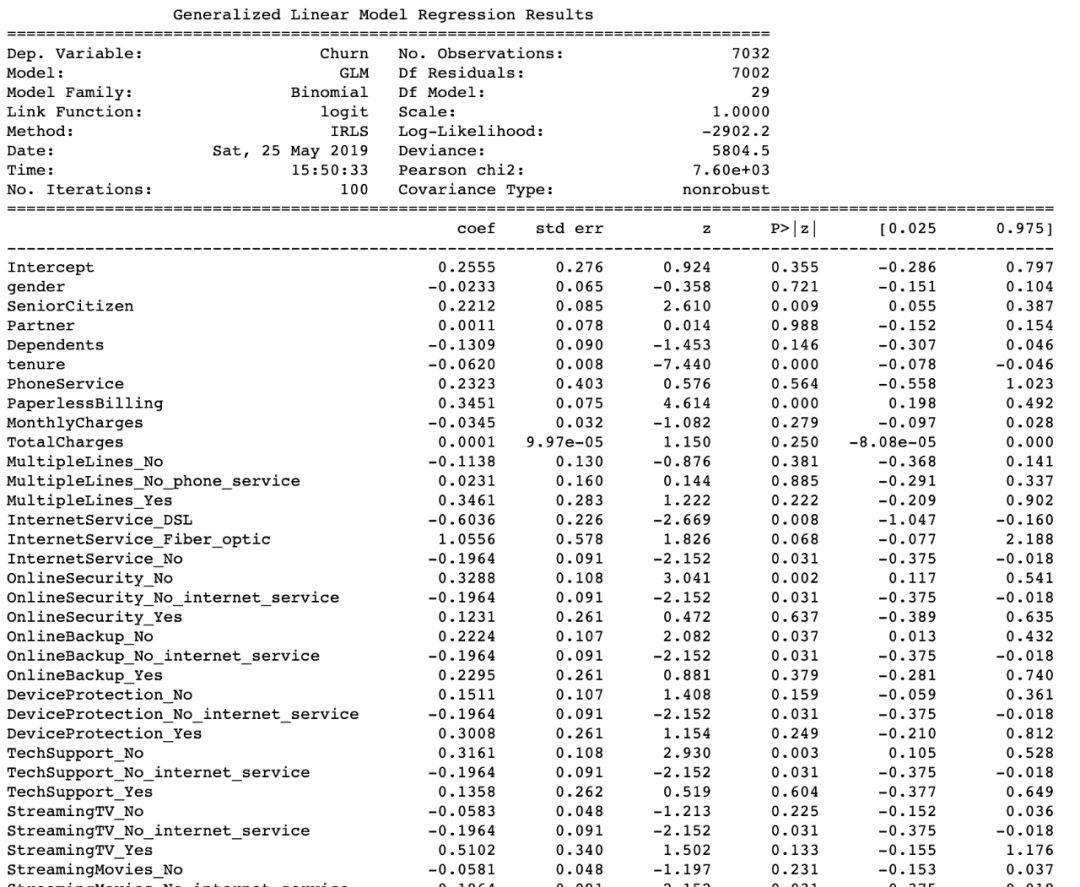

这份报告有两个重要成果。当你准备一个客户流失预测模型时,你将面临以下问题:
- 哪些特征使客户流失或留存?
- 最关键的特征是什么?我们应该关注什么?
对于第一个问题,你应该查看第4列(P>|z|)。如果p值的绝对值小于0.05,则说明该特征对流失有统计学意义。
例子有:
- SeniorCitizen
- InternetService_DSL
- OnlineSecurity_NO
然后是第二个问题。我们想要降低流失率,我们应该从哪里开始?这个问题的科学解释是:
如果我增加/减少一个unit,哪个特征会带来最好的ROI ?
这个问题可以通过查看coef列来回答。如果我们改变一个unit,指数coef就会给我们预期的流失率变化。如果我们使用下面的代码,我们将看到所有系数的变化:
np.exp(res.params)


举个例子,如果我们保持其他因素不变,每月的费用的一个unit的变化意味着大约3.4%的流失率的提高。从上面的表中,我们可以快速地确定哪些特性更重要。
现在,构建我们的分类模型的一切都准备好了。
使用XGBoost来构建二分类模型
为了用XGBoost拟合我们的数据,我们应该准备特征(X)和标签(y)集,并进行训练集和测试集的划分。
#create feature set and labels
X = df_data.drop(['Churn','customerID'],axis=1)
y = df_data.Churn#train and test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=56)#building the model & printing the score
xgb_model = xgb.XGBClassifier(max_depth=5, learning_rate=0.08, objective= 'binary:logistic',n_jobs=-1).fit(X_train, y_train)print('Accuracy of XGB classifier on training set: {:.2f}'
.format(xgb_model.score(X_train, y_train)))
print('Accuracy of XGB classifier on test set: {:.2f}'
.format(xgb_model.score(X_test[X_train.columns], y_test)))
通过使用这个简单的模型,我们达到了81%的准确率:


我们在数据集中的实际流失率是26.5%(反映为模型性能为73.5%)。这说明我们的模型是有用的。最好检查一下我们的分类模型,看看我们的模型到底在什么地方失败了。
y_pred = xgb_model.predict(X_test)
print(classification_report(y_test, y_pred))
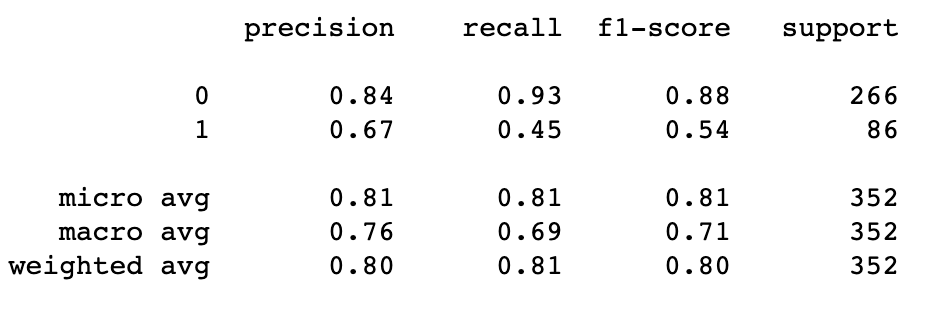

我们可以将上面的报告理解为我们的模型告诉我们,100个预测会流失的客户中,有67个客户将会流失(0.67的精确度)。实际上,大约有220个客户会流失(0.45召回率)。召回率是这里的主要问题,我们可以通过以下方式来提高我们模型的整体性能:
- 添加更多数据(本例中大约有2k行)
- 增加更多特征
- 更多特征工程
- 尝试其他模型
- 超参数调优
接下来,让我们详细看看我们的模型是如何工作的。首先,我们想要知道我们的模型究竟使用了来自数据集的哪些特征。还有,哪些是最重要的?
为了解决这个问题,我们可以使用下面的代码:
from xgboost import plot_importance
fig, ax = plt.subplots(figsize=(10,8))
plot_importance(xgb_model, ax=ax)
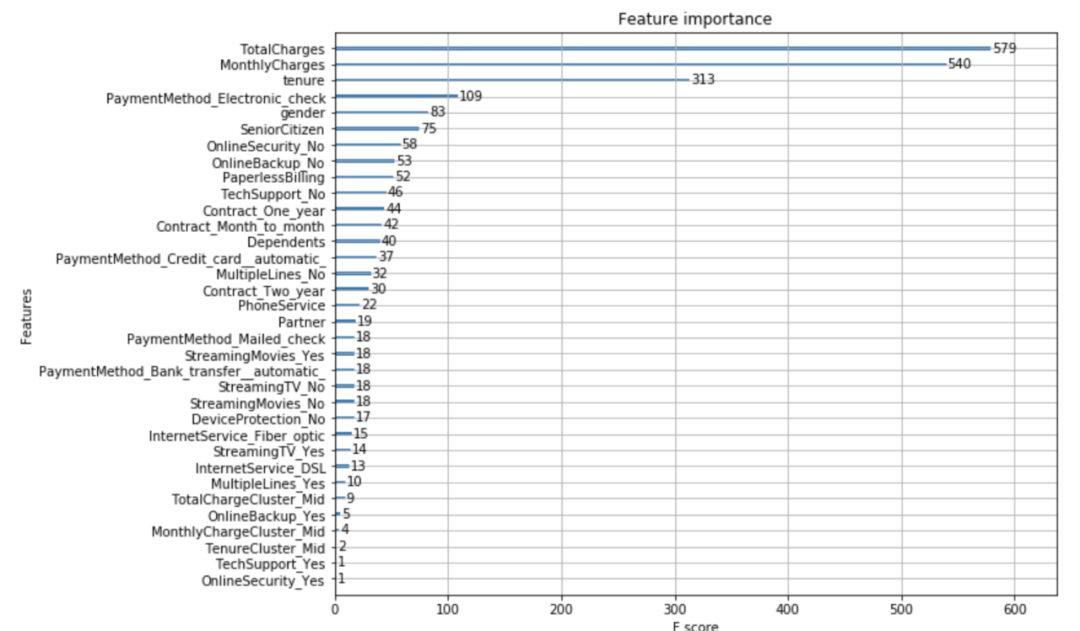

XGBoost模型中的特征重要性
我们可以看到,我们的模型比其他模型更重视总费用和月费用。
最后,使用此模型的最佳方法是为每个客户分配一个客户流失率,创建细分市场,并在此基础上构建策略。为了从我们的模型中得到客户流失的概率,使用下面的代码:
df_data['proba'] = xgb_model.predict_proba(df_data[X_train.columns])[:,1]
我们的数据集如下:


客户的流失概率
现在我们知道如果有可能流失的客户在我们最好的分群里(回顾一下第二篇和第三篇文章),我们在此基础上进行一些操作。在下一篇文章中,我们将着重于预测客户的下一个购买日。
英文原文:https://towardsdatascience.com/churn-prediction-3a4a36c2129a


本文来自CSDN,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://blog.csdn.net/u011984148/article/details/105631169
注意:本文归作者所有,未经作者允许,不得转载

